在组之间绘制p值/意义符号
除了我从一般方差分析中获得的P值(p = 0.034*),这在我的条形图中很重要且手动注释。我还想在每个独立的时间点(0、0.5、8、24、48)的因素(“正常”和“高光+冰”)中找到并包括p值/重要性符号(“正常”和“高光+冰”)。 br>
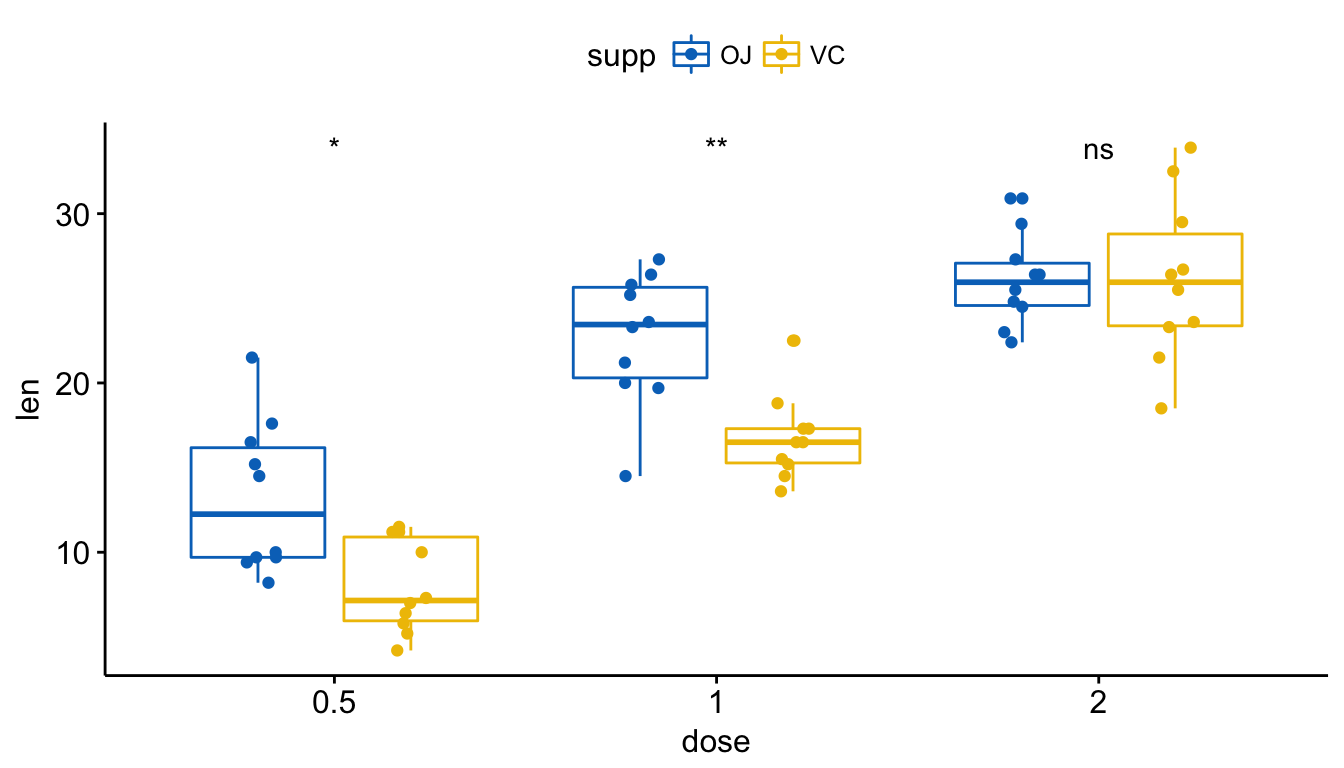
但是,似乎所有这些都不显着,如所附图像所示。
我可以知道我做错了哪一步?
PS我所需的p-value/意义绘图的示例
(http://www.sthda.com/english/sthda-upload/figures/ggpubr/010-add-p-values-to-ggplots-compare- Means-Interaction-3.png ) ( http://www.sthda.com/english/sthda-upload/figures/ggpubr/010-Add-p--values-to-ggplots-to-ggplots-compare-compare-compare-compare-means-ingeration-interaction-ingeraction-2.png )
我的数据框架:
Exp1_fv<-summarySE(data=Exp1, measurevar="fv", groupvars=c("growth_condition","time"))
data.frame(Exp1_fv)
growth_condition time N fv sd se ci
Normal 0.0 3 0.8066667 0.005773503 0.003333333 0.01434218
Normal 0.5 3 0.8033333 0.011547005 0.006666667 0.02868435
Normal 8.0 3 0.8100000 0.010000000 0.005773503 0.02484138
Normal 24.0 3 0.8166667 0.005773503 0.003333333 0.01434218
Normal 48.0 3 0.8100000 0.010000000 0.005773503 0.02484138
High light+Chilled 0.0 3 0.8133333 0.005773503 0.003333333 0.01434218
High light+Chilled 0.5 3 0.6766667 0.068068593 0.039299420 0.16909176
High light+Chilled 8.0 3 0.4433333 0.095043850 0.054873592 0.23610201
High light+Chilled 24.0 3 0.3900000 0.045825757 0.026457513 0.11383749
High light+Chilled 48.0 3 0.6966667 0.035118846 0.020275875 0.08724005
我的脚本:
ggplot(data=Exp1_fv, mapping = aes(x = factor(time), y = fv, fill= growth_condition))+
geom_bar(stat = "identity", position = "dodge")+
labs(title="Fv/Fm", x= "Time (hours)", y="Fv/Fm", fill= "Growth condition")+
ylim(0,1.2)+
geom_errorbar(aes(ymin=fv-se, ymax=fv+se), width=.2, position=position_dodge(width= 0.9))+
annotate(geom="text", x=1, y=1.1, label="p=0.034")+
annotate(geom="text", x=1, y=1.0, label="n=3")+
stat_compare_means(aes(group=growth_condition), label="p.signif")

如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!




{kind=link}
{kind=link}
发布评论
评论(1)
显然,“ stat_compare_means”将需要分组的完整数据,以提供任何有意义的统计测试(借助Adam Quek以获取建议)。因此,我将不得不在“ stat_compare_means”函数中引用我的原始数据(注释为“ EXP1”),而不是使用摘要数据(注释为“ EXP1_FV”,我从“ summarysese”函数中获得的“ EXP1_FV”)。
修改后的脚本:
stat_compare_means(data = exp1,label =“ p.Signif”,label.y = 0.85,method =“ anova”)
修改的图像
Apparently, "stat_compare_means" will require the full data of the groupings in order to provide any meaningful statistical test (credit to Adam Quek for the advice). Hence, I will have to refer my raw data (annotated as "Exp1") in the "stat_compare_means" function, rather than using the summarized data (annotated as "Exp1_fv" which I got from the "summarySE" function).
Modified script:
stat_compare_means(data=Exp1, label="p.signif", label.y= 0.85, method="anova")
Modified image