循环中的递归算法复杂度(运行时间)
我想了解您对如何检测以下递归算法的 T(n)(运行时间)的意见。

Charm 是一种用于发现事务数据库中频繁闭项集的算法。频繁闭项集列表是在一组交易(tids)中多次出现的频繁项(例如面包和牛奶是经常一起购买的物品),它们是通过将索引为 i 的当前元素与 n- 1 个连续元素循环而获得的在内部,其索引始终为 j = i + 1。该算法基于 3 个属性,并且根据情况,可以替换项目数组 P 的集合以及生成的任何新对象集合 Pi,所有这一切都取决于交易(tids),一些属性的示例如下:
- 我有一个项目数组 -> A 有 1345 笔交易,项目 D 的 tid 为 1356、F - 1345、E - 12345
- 将 A 与按支持度排序的下一个元素进行比较(A 的 tid 数量为 4,E 的 tid 数量为 5 等)
- 我将 A 与D 和 I 又回到属性 3,因为 A 的 tid 与 B 的 tid 不同(属性 1),也不包含它们(属性 2);然后添加 Pi AD - 135
- 比较 A 和 F,它们具有相同的 tid(属性 1),我通过删除旧 A 在 P 中用 AF - 1345 替换 A,在 Pi 中我们通过也在 Pi 上执行替换来循环
- 我比较AF(因为它已被替换)与 E 和 I 落入属性 2,其中 tid 1345 是 E -12345 的 tid 的子集;我在 P 中用 EFE - 1345 替换 AF,并且也在 Pi 中替换
如果集合 Pi 不为空,则运行内部循环我在属性 3 中生成的对象上递归执行 CHARM,否则我添加生成的 Xi,并通过 minsup 进行过滤(最小支持)例如,如果我将其设置为等于 3,我会拒绝集合 C(频繁关闭)中未达到 3 个 tid 的元素,例如假设的 H - 1 6 被丢弃。 itemset) 如果该元素不是现有元素之一的子集。这是一个具有初始数据集和分辨率的实际示例: 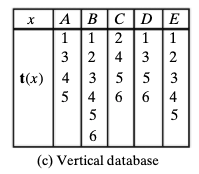
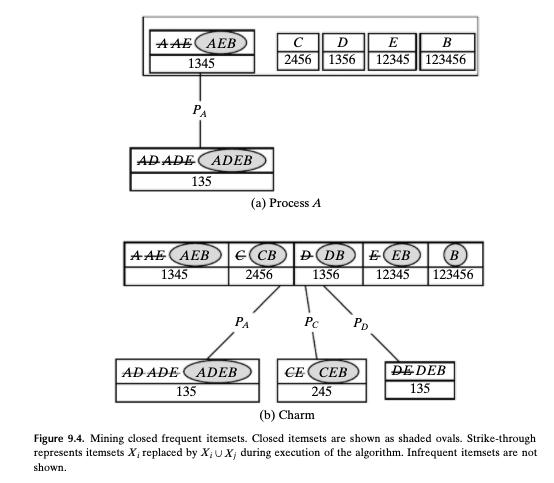
可以看出 Xi DEB 的 tid 为 135,不会作为 C 语言添加ADEB 的子集,具有相同的 tid。 要以图形方式查看分辨率,只需观看以下几分钟的视频 https://www.youtube .com/watch?v=XTj53ctgFFk。 根据我的分析,复杂性应该取决于 tid l 的平均长度和递归中传递的集合 Pi,但我不确定,如何解决以下递归算法以获得运行时间?谢谢。
I would like your opinion on how to detect the T(n) (Running Time) for the following recursive algorithm.
Charm is an algorithm for discovering frequent closed itemsets in a transaction database. A list of frequent closed itemsets are frequent items that appear several times in a set of transactions (tids) (e.g. bread and milk are items often purchased together), they are obtained by cycling the current element with index i with n- 1 successive elements in the inner for whose index will always be j = i + 1. The algorithm is based on 3 properties and depending on the case there can be a replace on the set of the array of items P and any new set of objects generated Pi, all this depends on the transactions (tids), some examples of the properties are the following:
- I have an array of items -> A with 1345 transactions, an item D with tids 1356, F - 1345, E - 12345
- Comparison A with the next elements sorted by support (number of tids present for A is 4, for E it is 5 etc.)
- I compare A with D and I fall back into property 3 since the tids of A are not the same as those of B (Property 1), nor are they contained (Property 2); then add in Pi AD - 135
- Comparison A with F, they have the same tids (Properties 1), I replace A with AF - 1345 in P by removing the old A, in Pi we cycle by performing the replace also on Pi
- I compare AF (as it has been replaced) with E and I fall into Property 2 where the tids 1345 are a subset of those of E -12345; I replace AF with EFE - 1345 in P and I replace also in Pi
Run the inner loop if the set Pi is not empty I recursively execute CHARM on the objects generated in Property 3 otherwise I add the generated Xi's and filtered by minsup (minimum support. For example if I set it equal to 3 I reject the elements that do not reach 3 tids, e.g. a hypothetical H - 1 6 is discarded) in the set C (Frequent closed itemset) if this element is not a subset of one of those present. Here is a practical example with initial dataset and resolution:
It can be seen that the Xi DEB has tids 135 and would not be added in C as a subset of ADEB which has the same tids.
To see the resolution graphically, just see the following video of a few minutes https://www.youtube.com/watch?v=XTj53ctgFFk.
From my analysis the complexity should depend on the average length of the tids l and on the set Pi passed in recursion but I'm not sure, how is the following recursive algorithm solved to get the running time? Thanks.
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!






发布评论