如何追踪广度优先搜索中的路径?
如何跟踪广度优先搜索的路径,例如在以下示例中:

如果搜索键11,则返回连接的最短列表1 至 11。
[1, 4, 7, 11]
How do you trace the path of a Breadth-First Search, such that in the following example:
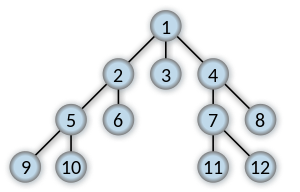
If searching for key 11, return the shortest list connecting 1 to 11.
[1, 4, 7, 11]
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!






发布评论
评论(7)
您应该查看http://en.wikipedia.org/wiki/Breadth-first_search 首先。
下面是一个快速实现,其中我使用列表列表来表示路径队列。
打印:
['1', '4', '7', '11']另一种方法是维护从每个节点到其父节点的映射,并在检查相邻节点时记录其父母。搜索完成后,只需根据父映射进行回溯即可。
上面的代码基于没有循环的假设。
You should have look at http://en.wikipedia.org/wiki/Breadth-first_search first.
Below is a quick implementation, in which I used a list of list to represent the queue of paths.
This prints:
['1', '4', '7', '11']Another approach would be maintaining a mapping from each node to its parent, and when inspecting the adjacent node, record its parent. When the search is done, simply backtrace according the parent mapping.
The above codes are based on the assumption that there's no cycles.
非常简单的代码。每次发现节点时,您都会不断附加路径。
Very easy code. You keep appending the path each time you discover a node.
我非常喜欢qiao的第一个回答!
这里唯一缺少的是将顶点标记为已访问。
为什么我们需要这样做?
假设有另一个节点 13 从节点 11 连接。现在我们的目标是找到节点 13。
运行一段时间后,队列将如下所示:
请注意,末尾有两条节点号为 10 的路径。
这意味着从节点 10 开始的路径将被检查两次。在这种情况下,它看起来并没有那么糟糕,因为节点号 10 没有任何子节点..但它可能真的很糟糕(即使在这里我们也会无缘无故地检查该节点两次..)
节点号 13 不在这些路径中,因此程序在到达末尾节点号为 10 的第二条路径之前不会返回。我们将重新检查它。.
我们缺少的是设置标记访问过的节点并且不再检查它们..
这是修改后的 qiao 代码:
程序的输出将是:
没有不必要的重新检查..
I liked qiao's first answer very much!
The only thing missing here is to mark the vertexes as visited.
Why we need to do it?
Lets imagine that there is another node number 13 connected from node 11. Now our goal is to find node 13.
After a little bit of a run the queue will look like this:
Note that there are TWO paths with node number 10 at the end.
Which means that the paths from node number 10 will be checked twice. In this case it doesn't look so bad because node number 10 doesn't have any children.. But it could be really bad (even here we will check that node twice for no reason..)
Node number 13 isn't in those paths so the program won't return before reaching to the second path with node number 10 at the end..And we will recheck it..
All we are missing is a set to mark the visited nodes and not to check them again..
This is qiao's code after the modification:
The output of the program will be:
Without the unneccecery rechecks..
我想我应该尝试编写这个代码来娱乐:
如果你想要循环,你可以添加这个:
I thought I'd try code this up for fun:
If you want cycles you could add this:
如果图表中包含了循环,这样的效果不是更好吗?
这样只有新节点才会被访问,而且避免了循环。
With cycles included in the graph, would not something like this work better?
This way only new nodes will be visited and moreover, avoid cycles.
我喜欢@Qiao的第一个答案和@Or的补充。为了减少处理量,我想添加 Or 的答案。
在@Or 的回答中,跟踪访问的节点非常棒。我们还可以允许程序比当前更早退出。在 for 循环中的某个时刻,
current_neighbour必须是end,一旦发生这种情况,就会找到最短路径,程序就可以返回。我将修改该方法如下,密切注意 for 循环
输出和其他一切都将是相同的。但是,处理代码所需的时间会更少。这对于较大的图尤其有用。我希望这对将来的人有帮助。
I like both @Qiao first answer and @Or's addition. For a sake of a little less processing I would like to add to Or's answer.
In @Or's answer keeping track of visited node is great. We can also allow the program to exit sooner that it currently is. At some point in the for loop the
current_neighbourwill have to be theend, and once that happens the shortest path is found and program can return.I would modify the the method as follow, pay close attention to the for loop
The output and everything else will be the same. However, the code will take less time to process. This is especially useful on larger graphs. I hope this helps someone in the future.
Javascript 版本和搜索第一个/所有路径...
您可以将其
转换为python,它很容易输出,如下所示..
Javascript version and search first/all paths ...
Your can
convertit topython, it's easyoutput like this..