使用单个数据库与使用多个数据库相比,性能有何提升?
我们正在构建一个软件,该软件可以接收每个系统约 100 个数据项的预先计算的小时平均值,这些数据项大约每天发送一次。可能有大约 20 个客户拥有 5-50 个系统。因此理论上每天大约插入 100 * 24 * 20 * 50 = 2400000 行。
每天不太可能有那么多插入,但这是我们需要记住的事情。
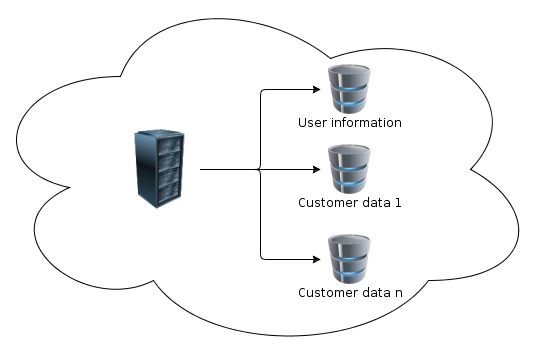
如果我们拆分数据库结构,以便每个客户都拥有自己的数据库(如上图所示),是否会提高性能?在共享数据库中将存在用户及其与数据库的关联。
或
更新
数据将保留约2-3年,然后系统将自动删除旧数据。用户不会删除“任何内容”,在这种情况下,任何内容都意味着从客户系统发送的数据。
更新 2
在图像中,服务器和数据库周围有一朵云。更具体地说:云是云计算的 Microsoft Azure 实现。
We are building a software that receives pre-calculated hour averages of about 100 data items per system that are sent about once per day. There might be about 20 customers with 5-50 systems. So the theoretical maximum will roughly 100 * 24 * 20 * 50 = 2400000 rows inserted per day.
It is very unlikely that there will be that many inserts per day, but that is something that we need to keep in mind.
Is there performance gain if we split database structure so that each customer will have it's own database like in the last picture? In the shared database there would be users and their associations to the databases.
Or
Update
Data will kept for about 2-3 years and then system will automatically delete old data. Users are not deleting "anything", in this context anything means data that is sent from the customer systems.
Update 2
In the images there is a cloud around server and database. To be more specific: that cloud is Microsoft Azure implementation of cloud computing.
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!




发布评论
评论(4)
如果每个客户仅使用自己的数据,并且不需要访问其他客户的数据,我认为由于表锁只会影响一个客户的数据这一事实,因此可以获得一些性能,例如当客户 A在表上运行级联删除后,其他客户仍然可以在各自的数据库中读取和修改同一个表中的数据。如果没有这样的分割,表锁会影响所有。
话虽这么说,拆分数据库将使管理(进行备份、修改数据库结构、更新数据库地址等)变得更加麻烦且容易出错。
您可以从一个数据库开始,保存所有数据。然后,如果您发现客户经常等待其他客户操作完成,您可以拆分数据库;如果您正确地抽象了数据库访问,则不需要对代码进行大的更改。
请记住,过早的优化是万恶之源!
If each Customer works using only his own data, and doesn't need to access other customers data, I think some performance is to be gained thanks to the fact that table locks will only affect data of one customer, so for example when customer A runs a cascade delete on a table, other customers will still be able to read and modify data from the same table in their respective databases. Without such a split, table locks affect all.
That being said, splitting the database will make administration (making backups, modifying the database structure, updating database addresses etc) more troublesome and error-prone.
You could start with one database, holding all the data. Then, if you find out customers often wait till other customers operations finish, you can split the database; if you properly abstracted database access, no big changes in code should be needed.
Remember, premature optimization is the root of all evil!
如果数据库位于不同的物理磁盘上,则数据读取和写入的性能都会提高。如果它们位于同一磁盘/服务器上,则性能增益将太小而无需担心。另一方面,如果您使用多个服务器,重要的问题是您可以并行查询它们吗?如果做不到,您很可能无法从性能提升中获得尽可能多的好处。
进行多次插入是 I/O 密集型操作,因此您必须优化磁盘访问。将负载拆分到不同的磁盘上是最好的方法,但如果不能,您仍然可以提高性能:
There would be performance gain in both reading and writing of data, if the databases are on different physical disks. If they are on the same disk/server, the performance gain will be too small to bother. On the other hand, if you use multiple servers, the important question is can you query them in parallel? If you can't, most likely you won't benefit from the performance gain as much as you could.
Having many inserts is an I/O bound operation,so you have to optimize the disk access. Splitting load on different disk is the best way you could do, but if you can't, you still can improve performance:
更好、更通用的解决方案是运行一个主数据库和多个从数据库(只读,自动与主数据库保持同步)。更新被发送到主服务器,但选择沿着所有数据库分布(因为无论查询在哪里运行,选择都会得到相同的结果)。
有许多“开箱即用”的产品可以做到这一点,无论是开源产品还是商业产品。
A better, more general, solution is to run a master db and several slave (read-only, automatically kept in synch with master) dbs. Updates are sent to the master, but selects are distributed along all dbs (since selects will get the same result no matter where the query is run).
There are many products that do this "out of the box", both open source and commercial.
我认为您的问题很大程度上与“多租户”设计相关 - 如何设计供多个用户使用的单个系统?它在 Basecamp 等“软件即服务”产品中很常见。
我不知道有任何明确的答案,但我通常的建议与 socha23 类似:设计您的解决方案,使其可以支持多个数据库,但只有当您需要。
一般来说,为每个用户提供单一解决方案更容易管理。您只需备份一个数据库。您只需部署一个代码库。您的配置文件很容易保持同步。
为各个客户提供单独的基础设施(硬件或软件)会立即使一切变得更加复杂 - 您应该投资于高度自动化来管理这种复杂性(我推荐“持续交付”方法 - http://continuousdelivery.com/)。成本远远超出了硬件或软件许可的范围 - 因此,只有在有充分理由的情况下,您才应该承担该成本。
这大概就是大多数 SaaS 提供商提供分层服务的原因。就您而言,如果“黄金”客户准备为额外的性能付费,您可以向他们提供他们自己的数据库。
I see your question largely as one related to "multi tenancy" design - how do you design a single system for use by several users? it's common in "software as a service" products like Basecamp etc.
I'm not aware of any definitive answers, but my usual recommendation is similar to socha23: design your solution so it can support multiple databases, but only go that way if you need to.
In general, having a single solution for every user is MUCH easier to manage. You only have to back up one database. You only have to deploy a single codebase. Your configuration files are easy to keep in sync.
Having separate infrastructure (hardware or software) for individual customers immediately makes everything a lot more complex - and you should invest in heavy automation to manage that complexity (I recommend the "continuous delivery" approach - http://continuousdelivery.com/). The cost goes well beyond hardware or software licenses - so you should only incur that cost if there's a good reason to do it.
This presumably is why most SaaS providers have tiered services. In your case, you might offer a "gold" customer their own database if they are prepared to pay for the additional performance.