“git init”和“git init”有什么区别?和“git init --bare”?
git init 和 git init --bare 之间有什么不同?我发现很多博客文章的 Git 服务器都需要 --bare ?
从手册页中,它说:
<前><代码>--裸露创建一个裸存储库。如果未设置GIT_DIR环境,则设置为当前工作目录
但这实际上是什么意思? Git 服务器设置是否需要 --bare ?
What is the different between git init and git init --bare? I found that a lot of blog post requires --bare for their Git server?
From the man page, it said:
--bareCreate a bare repository. If GIT_DIR environment is not set, it is set to the current working directory
But what does it actually mean? Is it required to have --bare for the Git server setup?
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!






发布评论
评论(6)
非裸 Git 存储库
此变体创建一个带有工作目录的存储库,以便您可以实际工作 (
git clone)。创建后,您将看到该目录包含一个.git文件夹,其中包含历史记录和所有 git 管道。您在.git文件夹所在的级别工作。Bare Git Repo
另一种变体创建一个没有工作目录的存储库 (
git clone --bare)。您没有获得可以工作的目录。在上述情况下,目录中的所有内容现在都包含在.git文件夹中。为什么你会使用一个而不是另一个
不需要工作目录的 git 存储库是因为你可以将分支推送到它,并且它不管理某人正在处理的内容。您仍然可以推送到非裸露的存储库,但您会被拒绝,因为您可能会移动某人正在该工作目录中处理的分支。
因此,在没有工作文件夹的项目中,您只能看到 git 存储的对象。它们被压缩、序列化并存储在其内容的 SHA1(哈希值)下。为了获取裸存储库中的对象,您需要 git show ,然后指定您想要查看的对象的 sha1 。您不会看到与您的项目类似的结构。
裸存储库通常是每个人将工作转移到的中央存储库。无需操纵实际工作。这是一种在多人之间同步工作的方法。您将无法直接查看您的项目文件。
如果您是唯一参与该项目的人或者您不想要/不需要“逻辑中央”存储库,则您可能不需要任何裸存储库。在这种情况下,人们更喜欢从其他存储库中
git pull。这避免了 git 在推送到非裸存储库时遇到的反对。Non-Bare Git Repo
This variant creates a repository with a working directory so you can actually work (
git clone). After creating it you will see that the directory contains a.gitfolder where the history and all the git plumbing goes. You work at the level where the.gitfolder is.Bare Git Repo
The other variant creates a repository without a working directory (
git clone --bare). You don't get a directory where you can work. Everything in the directory is now what was contained in the.gitfolder in the above case.Why You Would Use One vs. the Other
The need for git repos without a working directory is the fact that you can push branches to it and it doesn't manage what someone is working on. You still can push to a repository that's not bare, but you will get rejected as you can potentially move a branch that someone is working on in that working directory.
So in a project with no working folder, you can only see the objects as git stores them. They are compressed and serialized and stored under the SHA1 (a hash) of their contents. In order to get an object in a bare repository, you need to
git showand then specify the sha1 of the object you want to see. You won't see a structure like what your project looks like.Bare repositories are usually central repositories where everyone moves their work to. There is no need to manipulate the actual work. It's a way to synchronize efforts between multiple people. You will not be able to directly see your project files.
You may not have the need for any bare repositories if you are the only one working on the project or you don't want/need a "logically central" repository. One would prefer
git pullfrom the other repositories in that case. This avoids the objections that git has when pushing to non-bare repositories.简短回答
裸存储库是没有工作副本的 git 存储库,因此 .git 的内容是该目录的顶层。
使用非裸存储库在本地工作,使用裸存储库作为中央服务器/集线器与其他人共享您的更改。例如,当您在 github.com 上创建存储库时,它会被创建为裸存储库。
因此,在您的计算机中:
在服务器上:
然后在客户端上,您推送:
然后您可以通过将其添加为远程来保存自己的输入。
服务器端的存储库将通过拉取和推送来获取提交,而不是通过编辑文件然后将它们提交到服务器计算机中,因此它是一个裸存储库。
详细信息
你可以push到一个不是裸仓库的仓库,git会发现那里有一个.git仓库,但由于大多数“hub”仓库不需要工作副本,所以使用裸仓库是正常的为此并推荐,因为在这种存储库中拥有工作副本是没有意义的。
但是,如果您推送到非裸存储库,则会导致工作副本不一致,并且 git 会警告您:
您可以跳过此警告。但建议的设置是:使用非裸存储库在本地工作,使用裸存储库作为从中进行推送和拉取的集线器或中央服务器。
如果您想直接与其他开发人员共享工作副本,您可以从彼此的存储库中提取而不是推送。
Short answer
A bare repository is a git repository without a working copy, therefore the content of .git is top-level for that directory.
Use a non-bare repository to work locally and a bare repository as a central server/hub to share your changes with other people. For example, when you create a repository on github.com, it is created as a bare repository.
So, in your computer:
on the server:
Then on the client, you push:
You can then save yourself the typing by adding it as a remote.
The repository on the server side is going to get commits via pull and push, and not by you editing files and then commiting them in the server machine, therefore it is a bare repository.
Details
You can push to a repository that is not a bare repository, and git will find out that there is a .git repository there, but as most "hub" repositories do not need a working copy, it is normal to use a bare repository for it and recommended as there is no point in having a working copy in this kind of repositories.
However, if you push to a non bare repository, you are making the working copy inconsistent, and git will warn you:
You can skip this warning. But the recommended setup is: use a non-bare repository to work locally and a bare repository as a hub or central server to push and pull from.
If you want to share work directly with other developer's working copy, you can pull from each other repositories instead of pushing.
当我不久前读到这个问题时,一切都让我感到困惑。我刚刚开始使用 git,并且有这些工作副本(当时没有任何意义)。我将尝试从这个刚刚开始使用 git 对术语一无所知的人的角度来解释这一点。
可以通过以下方式描述差异的一个很好的示例:
--bare只为您提供一个存储位置(您不能在那里进行开发)。如果没有--bare它使您能够在那里开发(并拥有存储位置)。git init从当前目录创建一个 git 存储库。它在其中添加了 .git 文件夹,并可以启动您的修订历史记录。git init --bare 也会创建一个存储库,但它没有工作目录。这意味着您无法在该存储库中编辑文件、提交更改、添加新文件。
什么时候
--bare会有所帮助?您和其他几个人正在从事该项目并使用 git 。您将项目托管在某个服务器 (amazon ec2) 上。你们每个人都有自己的机器,并将代码推送到ec2上。你们实际上都没有在ec2上开发任何东西(您使用您的机器)——您只是推送您的代码。因此,您的ec2只是所有代码的存储,应该创建为--bare以及所有没有--bare的机器(大多数可能只是一个,其他的将克隆所有内容)。工作流程如下所示:When I read this question some time ago, everything was confusing to me. I just started to use git and there are these working copies (which meant nothing at that time). I will try to explain this from perspective of the guy, who just started git with no idea about terminology.
A nice example of the differences can be described in the following way:
--baregives you just a storage place (you can not develop there). Without--bareit gives you ability to develop there (and have a storage place).git initcreates a git repository from your current directory. It adds .git folder inside of it and makes it possible to start your revision history.git init --barealso creates a repository, but it does not have the working directory. This means that you can not edit files, commit your changes, add new files in that repository.When
--barecan be helpful? You and few other guys are working on the project and use git . You hosted the project on some server (amazon ec2). Each of you have your own machine and you push your code onec2. None of you actually develop anything onec2(you use your machines) - you just push your code. So yourec2is just a storage for all your code and should be created as--bareand all your machines without--bare(most probably just one, and other will just clone everything). The workflow looks like this:默认 Git 存储库假定您将使用它作为工作目录。通常,当您在服务器上时,不需要有工作目录。只是存储库。在这种情况下,您应该使用
--bare选项。A default Git repository assumes that you will be using it as your working directory. Typically, when you are on a server, you have no need to have a working directory. Just the repository. In this case, you should use the
--bareoption.非裸存储库是默认的。它是您运行 git init 时创建的内容,或者是从服务器克隆(没有
bare选项)时获得的内容。当您使用这样的存储库时,您可以查看和编辑存储库中的所有文件。当您与存储库交互时(例如通过提交更改),Git 将您的更改存储在名为
.git的隐藏目录中。当您有 git 服务器时,就不需要文件的工作副本。您所需要的只是存储在
.git中的 Git 数据。裸存储库就是.git目录,没有用于修改和提交文件的工作区域。当您从服务器克隆时,Git 在
.git目录中拥有创建工作副本所需的所有信息。A non-bare repository is the default. It is what is created when you run
git init, or what you get when you clone (without thebareoption) from a server.When you work with a repository like this, you can see and edit all of the files that are in the repository. When you interact with the repository - for example by committing a change - Git stores your changes in a hidden directory called
.git.When you have a git server there is no need for there to be working copies of the files. All you need is the Git data that's stored in
.git. A bare repository is exactly the.gitdirectory, without a working area for modifying and committing files.When you clone from a server Git has all the information it needs in the
.gitdirectory to create your working copy.--bare 和工作树存储库之间的另一个区别是,在第一种情况下,不存储丢失的提交,但仅存储属于分支轨道的提交。另一方面,工作树永远保留所有提交。见下文...
我使用 git init --bare 创建了第一个存储库(名称:git-bare)。这是服务器。它位于左侧,没有远程分支,因为这是远程存储库本身。
我使用第一个存储库的
git clone创建了第二个存储库(名称:git-working-tree)。这是在右边。它有链接到远程分支的本地分支。(文本“first”、“second”、“third”、“fourth”、“alpha”、“beta”和“delta”是提交注释。名称“master”和“greek”是分支名称。)
< a href="https://i.sstatic.net/vk18B.png" rel="nofollow noreferrer">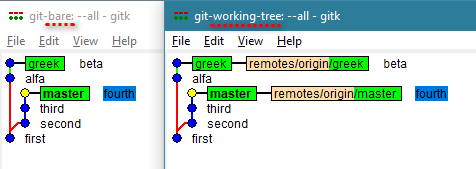
现在我将删除 git-bare 中名为“greek”的分支 em> (命令:
git push --delete origin greek)和本地 git-working-tree (命令:gitbranch -D greek)。树的外观如下:git-bare 存储库会删除分支和所有引用的提交。从图中我们可以看到它的树因此被减少了。
另一方面,git-working-tree 存储库相当于常用的本地存储库,不会删除提交,现在只能通过带有
的哈希直接引用git checkout 7fa897b7 命令。这就是为什么它的树没有修改过的结构。简而言之:提交永远不会在工作树存储库中删除,但会在裸存储库中删除。
实际上,您只能恢复如果本地存储库中存在分支,则已删除服务器上的分支。
但很奇怪的是,删除远程分支后,裸存储库的大小并没有减少磁盘大小。也就是说,这些文件仍然以某种方式存在。要通过删除不再引用的内容或永远无法引用的内容(后一种情况)来转储存储库,请使用 git gc --prune 命令
Another difference between --bare and Working Tree repositories is that in the first case no lost commits are stored, but only commits that belong to a branch track are stored. On the other hand, Working Tree keeps all commits forever. See below...
I created the first repository (name: git-bare) with
git init --bare. It's the server. It's on the left side, where there are no remote branches because this is the remote repository itself.I created the second repository (name: git-working-tree) with
git clonefrom the first. It's on the right. It has local branches linked to remote branches.(The texts 'first', 'second', 'third', 'fourth', 'alpha', 'beta' and 'delta' are the commit comments. The names 'master' and 'greek' are branch names.)
Now I will delete the branch named 'greek' both in git-bare (command:
git push --delete origin greek) and locally in git-working-tree (command:git branch -D greek). Here's how the tree looks:The git-bare repository deletes both the branch and all referenced comits. In the picture we see that its tree was reduced for this reason.
On the other hand, the git-working-tree repository, which is equivalent to a commonly used local repository, does not delete commits, which can now only be referenced directly by your hash with a
git checkout 7fa897b7command. That is why its tree does not have its modified structure.IN BRIEF: Commits are never dropped in working-tree repositories, but are deleted in bare repositories.
In practical terms, you can only recover a deleted branch on the server if it exists in a local repository.
But it is very strange that the size of the bare repository does not decrease in disk size after deleting a remote branch. That is, the files are still there somehow. To dump the repository by deleting what is no longer referenced or what can never be referenced (the latter case) use the
git gc --prunecommand