修复一个特别模糊的 Haskell 空间泄漏
因此,在从我用来将推文数据分解为 n 元语法的 Haskell 中发挥出最后一点性能后,我遇到了空间泄漏问题。当我进行分析时,GC 使用了大约 60-70% 的进程,并且有大量内存部分专用于拖动。希望当我出错时,一些 Haskell 大师能够提出建议。
{-# LANGUAGE OverloadedStrings, BangPatterns #-}
import Data.Maybe
import qualified Data.ByteString.Char8 as B
import qualified Data.HashMap.Strict as H
import Text.Regex.Posix
import Data.List
import qualified Data.Char as C
isClassChar a = C.isAlphaNum a || a == ' ' || a == '\'' ||
a == '-' || a == '#' || a == '@' || a == '%'
cullWord :: B.ByteString -> B.ByteString
cullWord w = B.map C.toLower $ B.filter isClassChar w
procTextN :: Int -> B.ByteString -> [([B.ByteString],Int)]
procTextN n t = H.toList $ foldl' ngram H.empty lines
where !lines = B.lines $ cullWord t
ngram tr line = snd $ foldl' breakdown (base,tr) (B.split ' ' line)
base = replicate (n-1) ""
breakdown :: ([B.ByteString], H.HashMap [B.ByteString] Int) -> B.ByteString -> ([B.ByteString],H.HashMap [B.ByteString] Int)
breakdown (st@(s:ss),tree) word =
newStack `seq` expandedWord `seq` (newStack,expandedWord)
where newStack = ss ++ [word]
expandedWord = updateWord (st ++ [word]) tree
updateWord :: [B.ByteString] -> H.HashMap [B.ByteString] Int -> H.HashMap [B.ByteString] Int
updateWord w h = H.insertWith (+) w 1 h
main = do
test2 <- B.readFile "canewobble"
print $ filter (\(a,b) -> b > 100) $
sortBy (\(a,b) (c,d) -> compare d b) $ procTextN 3 test2
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!






发布评论
评论(1)
一项小的优化是在排序之前过滤数据(使用
HashMap.filter)。这帮助我将最终执行时间缩短了 2 秒。我所做的另一件事是使用序列(Data.Sequence)而不是列表(没有明显区别:-( )。我的版本可以在 这里。查看堆配置文件,我认为您的程序中没有空间泄漏:
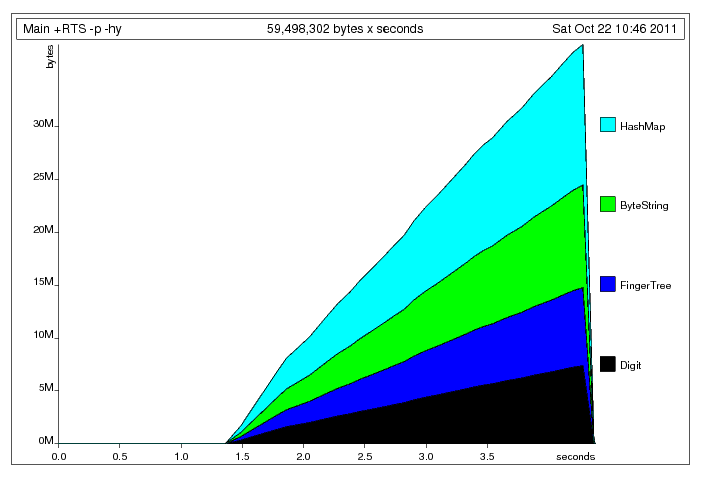
你只是在内存中构建了一个相当大的哈希表(377141 个键值对),然后将其丢弃经过一番处理后。根据 Johan 的帖子,这个大小的哈希表大约需要。 5*N + 4*(N-1) 个字 = 3394265*4 字节 ~= 13 MiB,这与堆配置文件显示的内容一致。剩余空间由键和值占用。在我的机器上,GC 花费的时间约为 40%,这听起来并不是不合理,因为您不断更新哈希表和临时“堆栈”,同时不对数据进行任何计算量大的操作。由于您需要哈希表的唯一操作是
insertWith,因此也许最好使用 可变数据结构?更新:我已经使用可变哈希表重写了您的程序。有趣的是,速度差别不大,但内存占用稍好一些:
正如你所看到的,大小块的为哈希表分配的值在整个执行过程中保持不变。
One small optimisation is to filter the data (using
HashMap.filter) before sorting it. This helped me shave 2s off the final execution time. Another thing I've done was to use sequences (Data.Sequence) instead of lists (no noticeable difference :-( ). My version can be found here.Looking at the heap profile, I don't think that there is a space leak in your program:

You're just building a fairly large hash table (377141 key-value pairs) in memory, and then discard it after some processing. According to Johan's post, a hash table of this size takes approx. 5*N + 4*(N-1) words = 3394265*4 bytes ~= 13 MiB, which agrees with what the heap profile shows. The remaining space is taken by the keys and values. On my machine, time spent in GC is around 40%, which doesn't sound unreasonable given that you're constantly updating the hash table and the temporary "stacks", while not doing anything computation-heavy with the data. Since the only operation that you need the hash table for is
insertWith, perhaps it's better to use a mutable data structure?Update: I've rewritten your program using a mutable hash table. Interestingly, the speed difference is not large, but memory usage is slightly better:
As you can see, the size of the block allocated for the hash table stays constant throughout the execution.