如何在 C# 中获取 unicode 字符的十进制值?
如何在 C# 中获取 unicode 字符的数值?
例如,如果泰米尔语字符 அ (U+0B85 )给定,输出应为2949(即0x0B85)
另请参阅
多代码点字符
有些字符需要多个代码点。在这个例子中,UTF-16,每个代码单元仍然在基本多语言平面中:
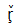 (即<代码>U+0072
(即<代码>U+0072 U+0327U+030C)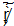 (即
(即 U+0072U+0338U+0327U+0316U+0317U+0300U+0301U+0302U+0308U+0360)
更重要的一点是,一个“字符”可能需要超过 1 个 UTF-16 代码单元,它可以需要超过 2 个 UTF-16 代码单元,它可以需要超过 3 个 UTF-16 代码单元。
更重要的一点是,一个“字符”可能需要数十个 unicode 代码点。在 C# 中的 UTF-16 中,这意味着超过 1 个 char。一个字符可能需要 17 个字符。
我的问题是关于将 char 转换为 UTF-16 编码值。即使一整串17个char只代表一个“字符”,我仍然想知道如何将每个UTF-16单位转换为数值。
例如
String s = "அ";
int i = Unicode(s[0]);
How do i get the numeric value of a unicode character in C#?
For example if tamil character அ (U+0B85) given, output should be 2949 (i.e. 0x0B85)
See also
- C++: How to get decimal value of a unicode character in c++
- Java: How can I get a Unicode character's code?
Multi code-point characters
Some characters require multiple code points. In this example, UTF-16, each code unit is still in the Basic Multilingual Plane:
- (i.e.
U+0072U+0327U+030C) - (i.e.
U+0072U+0338U+0327U+0316U+0317U+0300U+0301U+0302U+0308U+0360)
The larger point being that one "character" can require more than 1 UTF-16 code unit, it can require more than 2 UTF-16 code units, it can require more than 3 UTF-16 code units.
The larger point being that one "character" can require dozens of unicode code points. In UTF-16 in C# that means more than 1 char. One character can require 17 char.
My question was about converting char into a UTF-16 encoding value. Even if an entire string of 17 char only represents one "character", i still want to know how to convert each UTF-16 unit into a numeric value.
e.g.
String s = "அ";
int i = Unicode(s[0]);
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!




发布评论
评论(5)
它与Java基本相同。如果您将其作为
char获取,则可以隐式转换为int:如果您将其作为字符串的一部分获取,只需先获取该单个字符:
请注意,不在基本多语言平面中的字符将表示为两个 UTF-16 代码单元。 .NET 支持查找完整的 Unicode 代码点,但这并不简单。
It's basically the same as Java. If you've got it as a
char, you can just convert tointimplicitly:If you've got it as part of a string, just get that single character first:
Note that characters not in the basic multilingual plane will be represented as two UTF-16 code units. There is support in .NET for finding the full Unicode code point, but it's not simple.
如果您的字符为
char,则可以将其转换为int,它将表示字符的数值。然后,您可以以任何您喜欢的方式打印出来,就像打印任何其他整数一样。如果您想要十六进制输出,则可以使用:
X表示十六进制,4表示用零填充到四个字符。If you have the character as a
char, you can cast that to anint, which will represent the character's numeric value. You can then print that out in any way you like, just like with any other integer.If you wanted hexadecimal output instead, you can use:
Xis for hexadecimal,4is for zero-padding to four characters.char不一定是整个 Unicode 代码点。在 UTF-16 编码语言(例如 C#)中,您实际上可能需要 2 个 char 来表示单个“逻辑”字符。并且您的字符串长度可能不是您所期望的 - MSDN 文档String.Length 属性 表示:“Length 属性返回此实例中 Char 对象的数量,而不是 Unicode 字符的数量。”
char,它已经是数字(本质上是一个无符号的 16 位整数)。您可能希望将其转换为某些整数类型,但这不会改变char中最初存在的实际位。如果您的 Unicode 字符为 2 个
char,您需要将一个乘以 2^16,然后将其与另一个相加,得到一个uint数值:char c1 = ...;
字符 c2 = ...;
uint c = ((uint)c1 << 16) | c2;
当您说“十进制”时,这通常意味着仅包含人类将其解释为十进制数字的字符的字符串。
如果您只能用一个
char来表示您的 Unicode 字符,则只需通过以下方式将其转换为十进制字符串:char c = 'அ';
string s = ((ushort)c).ToString();
如果您的 Unicode 字符有 2 个
chars,请如上所述将它们转换为uint,然后调用uint.ToString。< /p>--- 编辑 ---
AFAIK 变音标记被视为单独的“字符”(和单独的代码点),尽管在视觉上与“基本”字符一起呈现。这些代码点中的每一个单独计算仍然最多为 2 个 UTF-16 代码单元。
顺便说一句,我认为你所谈论的正确名称不是“字符”,而是“组合字符”。所以,是的,单个组合字符可以有超过 1 个代码点,因此可以有超过 2 个代码单元。如果您想要十进制表示形式(例如组合字符),您可能可以通过 BigInteger 最轻松地完成:
根据您希望的代码单元“数字”的重要性顺序,您可能需要反转
c。A
charis not necessarily the whole Unicode code point. In UTF-16 encoded languages such as C#, you may actually need 2chars to represent a single "logical" character. And your string lengths migh not be what you expect - the MSDN documnetation for String.Length Property says:"The Length property returns the number of Char objects in this instance, not the number of Unicode characters."
char, it is already numeric (essentially an unsigned 16-bit integer). You may want to cast it to some of the integer types, but this won't change the actual bits that were originally present in thechar.If your Unicode character is 2
chars, you'll need to multiply one by 2^16 and add it to the other, resulting in auintnumeric value:char c1 = ...;
char c2 = ...;
uint c = ((uint)c1 << 16) | c2;
When you say "decimal", this usually means a character string containing only characters that a human being would interpret as decimal digits.
If you can represent your Unicode character by only one
char, you can convert it to decimal string simply by:char c = 'அ';
string s = ((ushort)c).ToString();
If you have 2
charsfor your Unicode character, convert them to auintas described above, then calluint.ToString.--- EDIT ---
AFAIK diacritical marks are considered separate "characters" (and separate code points) despite being visually rendered together with the "base" character. Each of these code points taken alone is still at most 2 UTF-16 code units.
BTW I think the proper name for what you are talking about is not "character" but "combining character". So yes, a single combining character can have more than 1 code point and therefore more than 2 code units. If you want a decimal representation of such as combining character, you can probably do it most easily through
BigInteger:Depending on what order of significance of the code unit "digits" you wish, you may want reverse the
c.这是使用平面 1(补充多语言平面 (SMP))的示例:
This is an example of using Plane 1, the Supplementary Multilingual Plane (SMP):