为什么 tesseract-ocr 在这种情况下会失败?
我正在尝试使用 Tesseract 来识别这个看似简单的情况下的字符:
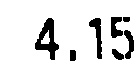
然而,唯一的事情是返回的是“5”。为什么会这样呢?我能做些什么来解决它吗?是否有任何替代方案(最好是开源 C++)可用?
I'm trying to use Tesseract to recognize characters in this seemingly simple case:
Yet, the only thing it returns is "5". Why would that be so? Is there anything I can do to fix it? Are there any alternatives (ideally open-source C++) available?
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!




发布评论
评论(2)
Tesseract 的 OCR 效果不是很好。它也不喜欢小图像或只有几个字符的图像。但它是最好的开源 OCR,其他的就更差了。不昂贵的替代方案: http://www.nicomsoft.com/crystalocr/ ,昂贵(但更好) :http://www.abbyy.com/ocr_sdk/
Tesseract is not very good OCR. Also it does not like small images or images with a few characters only. But it is the best open-source OCR, others are worse. Not expensive alternative: http://www.nicomsoft.com/crystalocr/ , expensive (but better): http://www.abbyy.com/ocr_sdk/
图像分辨率太低。尝试以 300 DPI 再次扫描。
The image resolution is too low. Try scan again @ 300 DPI.