我有一个需要使用正则表达式解析的字符串。
该字符串是:
http://carto1.wallonie.be/文件/terrils/fiche_terril.idc?TERRIL_id=1 Crachet 7/12
我尝试做的是分离网址和评论,所以我尝试了:
(\S+)\s(.+)
但结果,我得到:
$1 = > http://carto1.wallonie.be/documents/terrils /fiche_terril.idc?TERRIL_id=1 Crachet
$2 = > 7/12
所以,第一个字符似乎不是空格!
我尝试用 'X' 替换 \s 并得到
http://carto1.wallonie.be/文件/terrils/fiche_terril.idc?TERRIL_id=1 CrachetX7/12
我肯定有一些奇怪的东西。
我尝试用“X”(\n、\t 等)替换每个字符,但找不到这个“类似空格”是什么?
如何识别该字符并拆分字符串?
编辑:
如果您想使用我的代码,这是 Yahoo!管道:http://pipes.yahoo.com/pipes/pipe.edit? _id=a732be6cf2b7cb92cec5f9ee6ebca756
根据Pipes 文档,看起来它使用了相当标准的正则表达式语法。
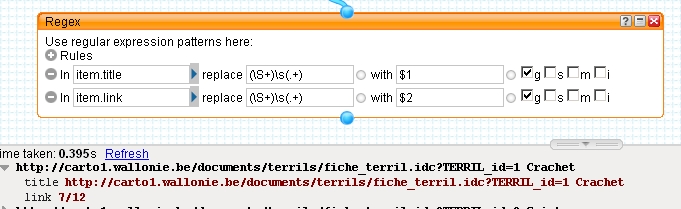
一些测试:
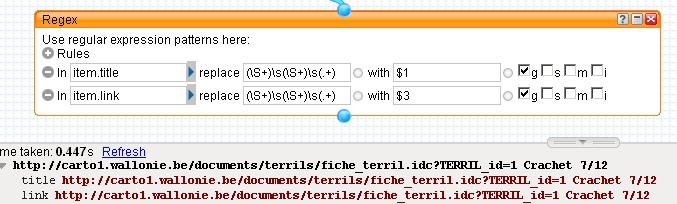
和

I have a string that I need to parse using regex.
This string is:
http://carto1.wallonie.be/documents/terrils/fiche_terril.idc?TERRIL_id=1 Crachet 7/12
What I try to do is to separate the url and the comment, so I tried:
(\S+)\s(.+)
but as result, I get:
$1 = > http://carto1.wallonie.be/documents/terrils/fiche_terril.idc?TERRIL_id=1 Crachet
$2 = > 7/12
So, it seem that first character is not a space!
I tried to replace \s by 'X' and got
http://carto1.wallonie.be/documents/terrils/fiche_terril.idc?TERRIL_id=1 CrachetX7/12
I am sure to have something strange.
I tried to replace every character by 'X' (\n, \t, etc.) but cannot find what is this "space lookalike"
How can I identify this character and split my string?
EDIT:
If you want to play with my code, this is a Yahoo! Pipe: http://pipes.yahoo.com/pipes/pipe.edit?_id=a732be6cf2b7cb92cec5f9ee6ebca756
According to the Pipes documentation, it looks like it uses fairly standard regex syntax.
Some tests:
and







发布评论
评论(1)
尝试使用正则表达式
并选中
g和m修饰符复选框。Try the regex
with the
gandmmodifier checkboxes checked.