为什么这个遗传算法会停滞不前?
Roger Alsing 编写了一种进化算法来重建蒙娜丽莎< /a> 使用 C#。他的算法很简单:
- 生成大小为 2 的随机群体。
- 用最适应者的克隆取代最不适合的个体。
- 变异其中一个个体。
- 转到步骤 2
有一个名为 Watchmaker 的 Java 进化算法框架。作者使用真正的遗传算法重新实现了蒙娜丽莎问题:http://watchmaker.uncommons.org/ example/monalisa.php
一开始还不错,但在 30 分钟内,Watchmaker 的实现停滞不前,近似程度很差,而 Roger 的实现看起来接近完成。我尝试调整这些设置,但没有多大帮助。 为什么 Watchmaker 的实施比 Roger 的慢得多并且为什么停滞不前?
链接:
Roger Alsing wrote an Evolutionary Algorithm for recreating the Mona Lisa using C#. His algorithm is simple:
- Generation a random population of size two.
- Replace the least-fit individual with a clone of the fittest.
- Mutate one of the individuals.
- Go to step 2
There is a Java Evolutionary Algorithm framework called Watchmaker. The author reimplemented the Mona Lisa problem using a genuine Genetic Algorithm: http://watchmaker.uncommons.org/examples/monalisa.php
It starts out well enough, but within 30 minutes the Watchmaker implementation stagnates with a poor approximation whereas Roger's implementation looks close to complete. I tried playing around with the settings but it didn't help much. Why is Watchmaker's implementation so much slower than Roger's and why does it stagnate?
Links:
- Roger's source-code
- Watchmaker's source-code
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!





发布评论
评论(1)
在过去的一个月里,我研究了这个问题,并取得了一些有趣的发现:
我修改了健身得分以删除隐藏的多边形(纯粹出于性能原因):
适应度+=candidate.size();这意味着适应度得分永远不会为零。
我已将最大多边形数量从 50 增加到 65535。
当我第一次尝试运行 Watchmaker 的《蒙娜丽莎》示例时,它会运行几天,但看起来与目标图像并不接近。罗杰的算法更好,但一个小时后仍然停滞不前。使用新算法,我在 15 分钟内成功地重新创建了目标图像。健康分数显示为 150,000,但肉眼看来,候选人与原始候选人几乎一模一样。
我整理了一个诊断显示,向我展示了整个种群随时间的演变。它还告诉我在任何给定时间有多少独特的候选者在人群中活跃。数字较低表示缺乏方差。要么是人口压力太大,要么是突变率太低。根据我的经验,一个体面的人群中至少包含 50% 的独特候选人。
我使用此诊断显示来调整算法。每当独特候选者的数量太少时,我就会增加突变率。每当算法停滞得太快时,我就会检查总体中发生的情况。我经常注意到突变量太高(颜色或顶点移动太快)。
我很高兴我在过去的一个月里研究了这个问题。它教会了我很多关于 GA 本质的知识。它与设计的关系比代码优化的关系更大。我还发现,实时观察整个种群的进化比只研究最适合的候选者非常重要。这使您可以相当快地发现哪些突变是有效的以及您的突变率是否太低或太高。
我学到了另一个重要的教训,即为什么向健身评估者提供与向用户显示的完全相同的图像极其重要。
如果您还记得我报告的最初问题是候选图像在评估之前被缩小,从而允许许多像素避免检测/校正。昨天我为向用户显示的图像启用了抗锯齿功能。我认为只要评估器看到 100% 的像素(不进行缩放)我就应该安全,但事实证明这还不够。
看一下下面的图像:
启用抗锯齿:
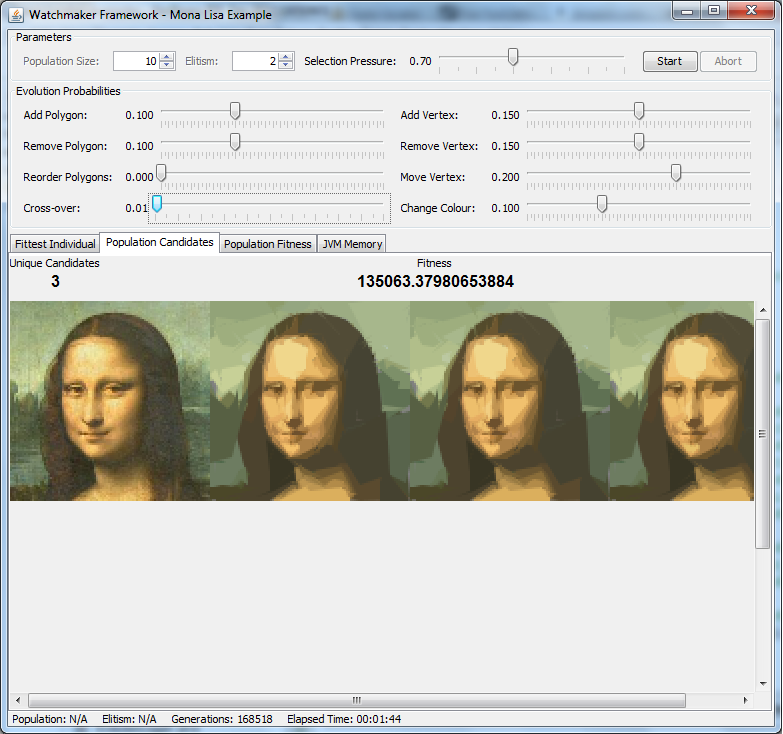
抗锯齿已禁用:
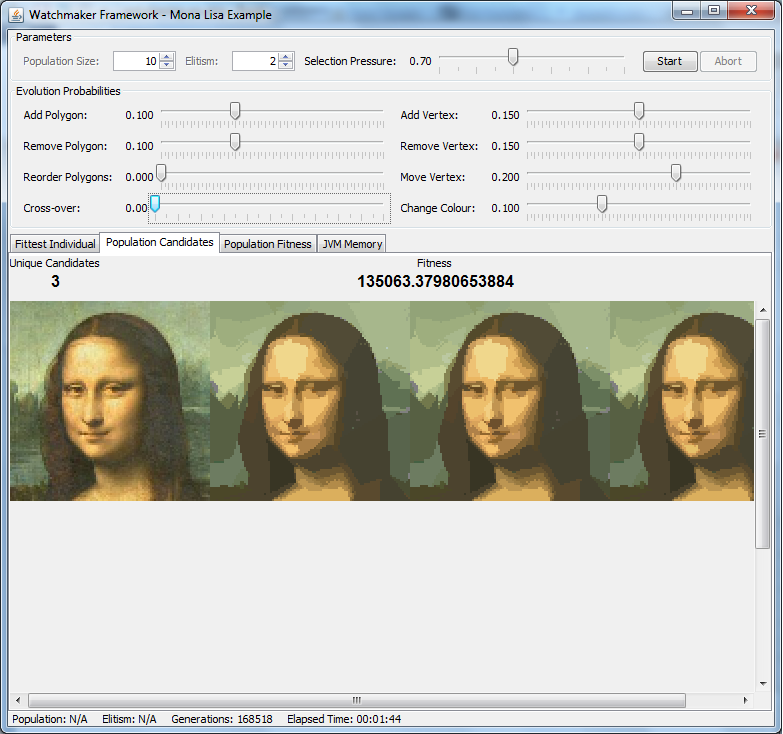
它们显示启用和禁用抗锯齿的完全相同的候选对象。请注意抗锯齿版本如何在脸上出现“条纹”错误,类似于我在缩放候选对象时看到的问题。事实证明,有时候选对象包含的多边形会以“条纹”(以亚像素精度渲染的多边形)的形式将错误引入图像中。有趣的是,别名会抑制这些错误,因此求值器函数看不到它。因此,用户会看到一大堆适应度函数永远无法修复的错误。听起来很熟悉吗?
总之:您应该始终(总是!)将您向用户显示的完全相同的图像传递给健身函数。安全总比后悔好:)
遗传算法很有趣。我鼓励你自己和他们一起玩。
I've studied this problem over the past month and made some interesting discoveries:
I've modified the fitness score to remove hidden polygons (purely for performance reasons):
fitness += candidate.size();This means that the fitness score will never hit zero.
I've increased the maximum number of polygons from 50 to 65535.
When I first tried running Watchmaker's Mona Lisa example it would run for days and not look anything close to the target image. Roger's algorithm was better but still stagnated after an hour. Using the new algorithm I managed to recreate the target image in less than 15 minutes. The fitness score reads 150,000 but to the naked eye the candidate looks almost identical to the original.
I put together a diagnostics display that shows me the entire population evolving over time. It also tells me how many unique candidates are active in the population at any given time. A low number indicates a lack of variance. Either the population pressure is too high or the mutation rates are too low. In my experience, a decent population contains at least 50% unique candidates.
I used this diagnostic display to tune the algorithm. Whenever the number of unique candidates was too low, I'd increase the mutation rate. Whenever the algorithm was stagnating too quickly I'd examine what was going on in the population. Very frequently I'd notice that the mutation amount was too high (colors or vertices moving too quickly).
I'm glad I spent the past month studying this problem. It's taught me a lot about the nature of GAs. It has a lot more to do with design than code optimization. I've also discovered that it's extremely important to watch the entire population evolve in real time as opposed to only studying the fittest candidate. This allows you to discover fairly quickly which mutations are effective and whether your mutation rate is too low or high.
I learned yet another important lesson about why it's extremely important to provide the fitness evaluator the exact same image as shown to the user.
If you recall the original problem I reported was that the candidate image was being scaled down before evaluation, thereby allowing many pixels to avoid detection/correction. Yesterday I enabled anti-aliasing for the image shown to the user. I figured so long as the evaluator was seeing 100% of the pixels (no scaling going on) I should be safe, but it turns out this isn't enough.
Take a look at the following images:
Anti-aliasing enabled:

Anti-aliasing disabled:

They show the exact same candidates with anti-aliasing enabled and disabled. Notice how the anti-aliased version has "streaks" of errors across the face, similar to the problem I was seeing when the candidate was being scaled. It turns out that sometimes the candidates contains polygons that introduce errors into the image in the form of "streaks" (polygons rendered with sub-pixel precision). The interesting thing is that aliasing suppresses these errors so the evaluator function does not see it. Consequently, the users sees a whole bunch of errors which the fitness function will never fix. Sounds familiar?
In conclusion: you should always (always!) pass the fitness function the exact same image you display to the user. Better safe than sorry :)
Genetic Algorithms are a lot of fun. I encourage you to play with them yourself.