每个 N 的最新记录的最佳执行查询
这是我发现自己所处的场景。
我有一个相当大的表,我需要从中查询最新记录。以下是查询的基本列的创建:
CREATE TABLE [dbo].[ChannelValue](
[ID] [bigint] IDENTITY(1,1) NOT NULL,
[UpdateRecord] [bit] NOT NULL,
[VehicleID] [int] NOT NULL,
[UnitID] [int] NOT NULL,
[RecordInsert] [datetime] NOT NULL,
[TimeStamp] [datetime] NOT NULL
) ON [PRIMARY]
GO
ID 列是主键,VehicleID 和 TimeStamp 有一个非聚集索引
CREATE NONCLUSTERED INDEX [IX_ChannelValue_TimeStamp_VehicleID] ON [dbo].[ChannelValue]
(
[TimeStamp] ASC,
[VehicleID] ASC
)ON [PRIMARY]
GO
我正在处理的用于优化查询的表有超过 2300 万行,只是查询需要操作的大小的十分之一。
我需要返回每个 VehicleID 的最新行。
我一直在 StackOverflow 上查看对这个问题的回答,并且进行了大量的谷歌搜索,似乎有 3 或 4 种常见方法可以在 SQL Server 2005 及更高版本上执行此操作。
到目前为止,我发现的最快方法是以下查询:
SELECT cv.*
FROM ChannelValue cv
WHERE cv.TimeStamp = (
SELECT
MAX(TimeStamp)
FROM ChannelValue
WHERE ChannelValue.VehicleID = cv.VehicleID
)
根据表中当前的数据量,执行大约需要 6 秒,这在合理的范围内,但根据表在实时环境中包含的数据量,查询开始执行速度太慢。
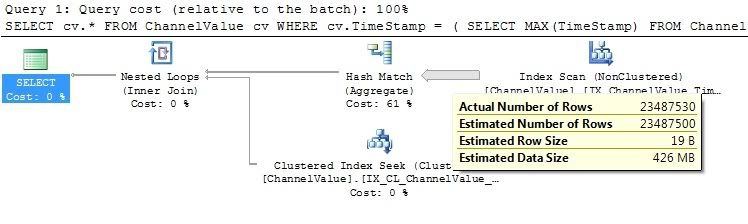
查看执行计划,我关心的是 SQL Server 正在做什么来返回行。
我无法发布执行计划图像,因为我的声誉不够高,但索引扫描正在解析表中的每一行,这大大减慢了查询速度。
我尝试使用几种不同的方法重写查询,包括使用 SQL 2005像这样的分区方法:
WITH cte
AS (
SELECT *,
ROW_NUMBER() OVER(PARTITION BY VehicleID ORDER BY TimeStamp DESC) AS seq
FROM ChannelValue
)
SELECT
VehicleID,
TimeStamp,
Col1
FROM cte
WHERE seq = 1
但是该查询的性能甚至更差了相当大的数量级。
我尝试过像这样重新构造查询,但结果速度和查询执行计划几乎相同:
SELECT cv.*
FROM (
SELECT VehicleID
,MAX(TimeStamp) AS [TimeStamp]
FROM ChannelValue
GROUP BY VehicleID
) AS [q]
INNER JOIN ChannelValue cv
ON cv.VehicleID = q.VehicleID
AND cv.TimeStamp = q.TimeStamp
我在表结构方面有一些灵活性(尽管程度有限),因此我可以添加索引、索引视图和等等,甚至是数据库中的附加表。
我非常感谢这里的任何帮助。
编辑 添加了执行计划图像的链接。
Here is the scenario I find myself in.
I have a reasonably big table that I need to query the latest records from. Here is the create for the essential columns for the query:
CREATE TABLE [dbo].[ChannelValue](
[ID] [bigint] IDENTITY(1,1) NOT NULL,
[UpdateRecord] [bit] NOT NULL,
[VehicleID] [int] NOT NULL,
[UnitID] [int] NOT NULL,
[RecordInsert] [datetime] NOT NULL,
[TimeStamp] [datetime] NOT NULL
) ON [PRIMARY]
GO
The ID column is a Primary Key and there is a non-Clustered index on VehicleID and TimeStamp
CREATE NONCLUSTERED INDEX [IX_ChannelValue_TimeStamp_VehicleID] ON [dbo].[ChannelValue]
(
[TimeStamp] ASC,
[VehicleID] ASC
)ON [PRIMARY]
GO
The table I'm working on to optimise my query is a little over 23 million rows and is only a 10th of the sizes the query needs to operate against.
I need to return the latest row for each VehicleID.
I've been looking through the responses to this question here on StackOverflow and I've done a fair bit of Googling and there seem to be 3 or 4 common ways of doing this on SQL Server 2005 and upwards.
So far the fastest method I've found is the following query:
SELECT cv.*
FROM ChannelValue cv
WHERE cv.TimeStamp = (
SELECT
MAX(TimeStamp)
FROM ChannelValue
WHERE ChannelValue.VehicleID = cv.VehicleID
)
With the current amount of data in the table it takes about 6s to execute which is within reasonable limits but with the amount of data the table will contain in the live environment the query begins to perform too slow.
Looking at the execution plan my concern is around what SQL Server is doing to return the rows.
I cannot post the execution plan image because my Reputation isn't high enough but the index scan is parsing every single row within the table which is slowing the query down so much.
I've tried rewriting the query with several different methods including using the SQL 2005 Partition method like this:
WITH cte
AS (
SELECT *,
ROW_NUMBER() OVER(PARTITION BY VehicleID ORDER BY TimeStamp DESC) AS seq
FROM ChannelValue
)
SELECT
VehicleID,
TimeStamp,
Col1
FROM cte
WHERE seq = 1
But the performance of that query is even worse by quite a large magnitude.
I've tried re-structuring the query like this but the result speed and query execution plan is nearly identical:
SELECT cv.*
FROM (
SELECT VehicleID
,MAX(TimeStamp) AS [TimeStamp]
FROM ChannelValue
GROUP BY VehicleID
) AS [q]
INNER JOIN ChannelValue cv
ON cv.VehicleID = q.VehicleID
AND cv.TimeStamp = q.TimeStamp
I have some flexibility available to me around the table structure (although to a limited degree) so I can add indexes, indexed views and so forth or even additional tables to the database.
I would greatly appreciate any help at all here.
Edit Added the link to the execution plan image.
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!








发布评论
评论(3)
取决于您的数据(每组有多少行?)和您的索引。
请参阅优化每组查询的 TOP N,了解 3 种方法的一些性能比较。
在您的情况下,只有少量车辆有数百万行,我会在
VehicleID, Timestamp上添加索引并执行Depends on your data (how many rows are there per group?) and your indexes.
See Optimizing TOP N Per Group Queries for some performance comparisons of 3 approaches.
In your case with millions of rows for only a small number of Vehicles I would add an index on
VehicleID, Timestampand do如果您的记录是按顺序插入的,则将查询中的
TimeStamp替换为ID可能会产生影响。附带说明一下,这会返回多少条记录?如果您要返回数十万行,则延迟可能会导致网络开销。
If your records are inserted sequentially, replacing
TimeStampin your query withIDmay make a difference.As a side note, how many records is this returning? Your delay could be network overhead if you are getting hundreds of thousands of rows back.
试试这个:
预计会进行表或索引扫描,因为您没有以任何方式过滤数据。您要求所有 VehicleID 的最新时间戳 - 查询引擎必须查看每一行以找到最新的时间戳。
您可以通过缩小返回的列数(不要使用 SELECT *)并提供由 VehicleID + TimeStamp 组成的索引来帮助解决这个问题。
Try this:
A table or index scan is expected, because you're not filtering data in any way. You're asking for the latest TimeStamp for all VehicleIDs - the query engine HAS to look at every row to find the latest TimeStamp.
You can help it out by narrowing the number of columns being returned (don't use SELECT *), and by providing an index that consists of VehicleID + TimeStamp.