preg_match_all `u` 标志依赖于什么?
我在 PHP 应用程序中有一些代码,当我尝试在生产服务器上使用它时,它返回 null,但它在开发服务器上运行良好。这是代码行:
// use the regex unicode support to separate the UTF-8 characters into an array
preg_match_all( '/./us', $str, $match );
u 标志依赖什么?我在启用和禁用 mb_string 的情况下进行了测试,它似乎没有影响它。
我收到的错误是
preg_match_all: Compilation failed:known option bit(s) set at offset -1
more info
这是生产服务器上的选项之一:
'--with-pcre-regex=/opt/pcre'
这里是 pcre 部分
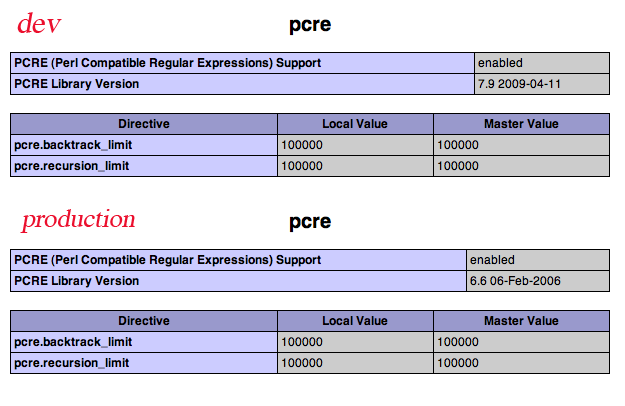
我相信这是 @Wesley 所指的注释:
In order process UTF-8 strings, you must build PCRE to include UTF-8
support in the code, and, in addition, you must call pcre_compile()
with the PCRE_UTF8 option flag, or the pattern must start with the
sequence (*UTF8). When either of these is the case, both the pattern
and any subject strings that are matched against it are treated as
UTF-8 strings instead of strings of 1-byte characters.
有关如何“构建 PCRE 以包含 UTF-8”的任何链接或提示吗?
pcretest -C<的结果/代码>
PCRE version 6.6 06-Feb-2006
Compiled with
UTF-8 support
Unicode properties support
Newline character is LF
Internal link size = 2
POSIX malloc threshold = 10
Default match limit = 10000000
Default recursion depth limit = 10000000
Match recursion uses stack
I have some code in a PHP application that is returning null when I try and use it on the production server, but it works fine on the development server. Here is the line of code:
// use the regex unicode support to separate the UTF-8 characters into an array
preg_match_all( '/./us', $str, $match );
What is the u flag dependent on? I tested with mb_string enabled and disabled and it does not seem to affect it.
The error I'm getting is
preg_match_all: Compilation failed: unknown option bit(s) set at offset -1
more info
this is one of the options on the prodction server:
'--with-pcre-regex=/opt/pcre'
and here are the pcre sections
I believe this is the note @Wesley was referring to:
In order process UTF-8 strings, you must build PCRE to include UTF-8
support in the code, and, in addition, you must call pcre_compile()
with the PCRE_UTF8 option flag, or the pattern must start with the
sequence (*UTF8). When either of these is the case, both the pattern
and any subject strings that are matched against it are treated as
UTF-8 strings instead of strings of 1-byte characters.
Any links or tips on how to "build PCRE to include UTF-8" ?
results of pcretest -C
PCRE version 6.6 06-Feb-2006
Compiled with
UTF-8 support
Unicode properties support
Newline character is LF
Internal link size = 2
POSIX malloc threshold = 10
Default match limit = 10000000
Default recursion depth limit = 10000000
Match recursion uses stack
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!




发布评论
评论(2)
该标志取决于在启用 unicode 支持的情况下构建的 PCRE。
PHP 捆绑了该库,并且通常在启用 unicode 支持的情况下构建:当 PHP 使用捆绑的 PCRE 库构建时,
u修饰符可用,并且自 PHP 4.1.0 起始终有效。然而,一些 Linux 发行版根据自己的 PCRE 构建来构建 PHP,而 PCRE 没有启用 unicode 支持,因此
u修饰符在这些构建上不起作用。解决方案是使用替代 PHP 包。
This flag depends on PCRE being built with unicode support enabled.
PHP bundles this library and it's normally built with unicode support enabled: The
umodifier is available and always works since PHP 4.1.0, when PHP is built with the bundled PCRE library.However some Linux distributions build PHP against their own build of PCRE, which do not have unicode support enabled, and as a result the
umodifier doesn't work on those builds.The solution is to use an alternative PHP package.
这取决于使用 --enable-utf8 编译的 PCRE。
It depends on the PCRE being compiled with --enable-utf8.