子查询或 leftjoin 与 group by 哪个更快?
 我必须在我的应用程序中显示运行总计和总计列...所以我使用了以下查询为了找到运行总计......我发现两者都按照我的需要工作。在一个中,我使用了带有 group by 的左连接,在另一个中,我使用了子查询。
我必须在我的应用程序中显示运行总计和总计列...所以我使用了以下查询为了找到运行总计......我发现两者都按照我的需要工作。在一个中,我使用了带有 group by 的左连接,在另一个中,我使用了子查询。
现在我的问题是,当我的数据每天增长数千次时,哪一种更快,如果数据限制在 1000 或 2000 行,那么哪一种更好......以及任何其他方法比这两种更快? ??
declare @tmp table(ind int identity(1,1),col1 int)
insert into @tmp
select 2
union
select 4
union
select 7
union
select 5
union
select 8
union
select 10
SELECT t1.col1,sum( t2.col1)
FROM @tmp AS t1 LEFT JOIN @tmp t2 ON t1.ind>=t2.ind
group by t1.ind,t1.col1
select t1.col1,(select sum(col1) from @tmp as t2 where t2.ind<=t1.ind)
from @tmp as t1
i have to show running total with the total column in my application ... so i have used the following queries for finding the running total... and i find that both are working as per my need . in one i used the left join with group by and in another one i used the sub query .
and now my question is which one is faster when my data grow in thousands daily and if data will be in limit of 1000 or 2000 rows then which one is better ... and any other method by which is more faster then these two ????
declare @tmp table(ind int identity(1,1),col1 int)
insert into @tmp
select 2
union
select 4
union
select 7
union
select 5
union
select 8
union
select 10
SELECT t1.col1,sum( t2.col1)
FROM @tmp AS t1 LEFT JOIN @tmp t2 ON t1.ind>=t2.ind
group by t1.ind,t1.col1
select t1.col1,(select sum(col1) from @tmp as t2 where t2.ind<=t1.ind)
from @tmp as t1
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!






发布评论
评论(3)
关于在 SQL Server 中计算运行总计的重要资源是由 Itzik Ben Gan 提交的此文档,该文档已提交至SQL Server 团队希望将
OVER子句从最初的 SQL Server 2005 实现中进一步扩展。在其中,他展示了一旦进入数万行游标如何执行基于集合的解决方案。 SQL Server 2012 确实扩展了 OVER 子句,使此类查询变得更加容易。然而,由于您使用的是 SQL Server 2005,因此您无法使用此功能。
亚当·马哈尼克 此处展示如何使用 CLR 来提高标准 TSQL 游标的性能。
对于此表定义,
我在数据库中创建了包含 2,000 行和 10,000 行的表,其中
ALLOW_SNAPSHOT_ISOLATION ON和一个关闭此设置的表(这样做的原因是因为我的初始结果位于设置为 on 的数据库中)这导致了结果令人费解的一面)。所有表的聚集索引只有 1 个根页。每个叶子页的数量如下所示。
我测试了以下情况(链接显示执行计划)
包含附加 CTE 选项的原因是为了提供一个 CTE 解决方案,该解决方案将如果
ind列不能保证顺序,仍然可以工作。所有查询都添加了
CAST(col1 AS BIGINT)以避免运行时出现溢出错误。此外,对于所有这些,我将结果分配给上述变量,以消除发送回结果所花费的时间。结果
相关子查询和
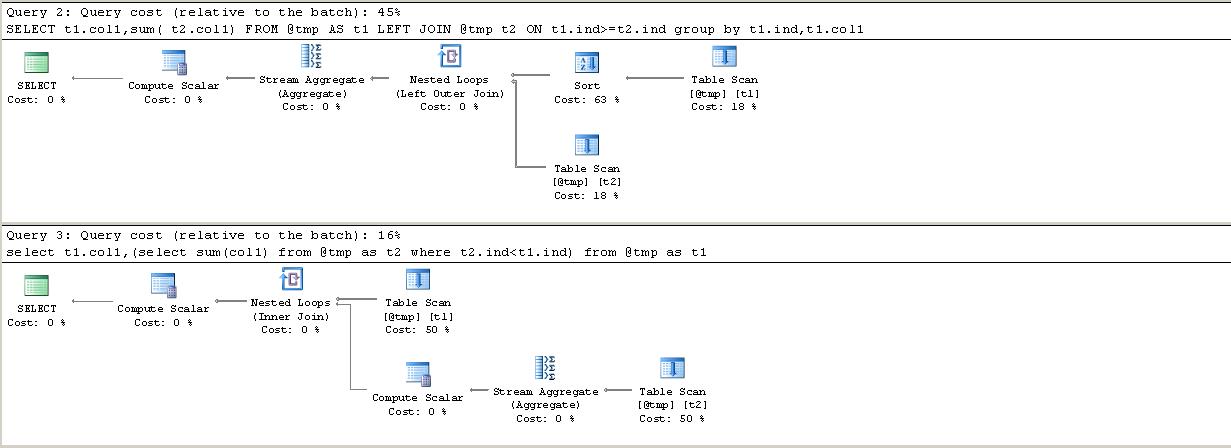
GROUP BY版本均使用由RunningTotals表 (T1) 上的聚集索引扫描驱动的“三角”嵌套循环连接),并且对于该扫描返回的每一行,在T2.ind<=T1.ind上查找回表 (T2) 自连接。这意味着相同的行会被重复处理。当处理
T1.ind=1000行时,自连接会检索并汇总具有ind <= 1000的所有行,然后对于下一行,其中T1 .ind=1001再次检索相同的 1000 行,并与另外一行一起求和,依此类推。对于 2,000 行的表,此类操作的总数为 2,001,000,对于 10k 行,此类操作的总数为 50,005,000 或更一般
( n² + n) / 2显然呈指数增长。在 2,000 行的情况下,
GROUP BY和子查询版本之间的主要区别在于,前者在连接后具有流聚合,因此有三列输入其中 (T1.ind< /code>、T2.col1、T2.col1)和T1.ind的GROUP BY属性,而后者是作为标量聚合计算,在连接之前使用流聚合,仅将T2.col1输入其中,并且根本没有设置GROUP BY属性。可以看出,这种更简单的安排在减少 CPU 时间方面具有显着的好处。对于 10,000 行的情况,子查询计划还有一个额外的差异。它添加了一个eager spool,它复制所有
ind,cast (col1 as bigint)值存入tempdb。在启用快照隔离的情况下,这比聚集索引结构更紧凑,最终效果是将读取次数减少约 25%(因为基表为版本控制信息保留了相当多的空白空间),当此选项关闭时,其结果会不太紧凑(可能是由于bigint与int的差异),并且会产生更多的读取结果。这减少了子查询和 group by 版本之间的差距,但子查询仍然获胜。然而,明显的赢家是递归 CTE。对于“无间隙”版本,从基表的逻辑读取现在为
2 x (n + 1),反映了n索引查找 2 级索引以检索所有这些行加上末尾的附加行,该行不返回任何内容并终止递归。然而,这仍然意味着需要 20,002 次读取来处理 22 页表!递归 CTE 版本的逻辑工作表读取非常高。似乎每个源行有 6 次工作表读取。这些来自存储前一行的输出的索引假脱机,然后在下一次迭代中再次读取(Umachandar Jayachandran对此进行了很好的解释 此处)。尽管数量很高,但这仍然是表现最好的。
A great resource on calculating running totals in SQL Server is this document by Itzik Ben Gan that was submitted to the SQL Server Team as part of his campaign to have the
OVERclause extended further from its initial SQL Server 2005 implementation. In it he shows how once you get into tens of thousands of rows cursors out perform set based solutions. SQL Server 2012 did indeed extend theOVERclause making this sort of query much easier.As you are on SQL Server 2005 however this is not available to you.
Adam Machanic shows here how the CLR can be used to improve on the performance of standard TSQL cursors.
For this table definition
I create tables with both 2,000 and 10,000 rows in a database with
ALLOW_SNAPSHOT_ISOLATION ONand one with this setting off (The reason for this is because my initial results were in a DB with the setting on that led to a puzzling aspect of the results).The clustered indexes for all tables just had 1 root page. The number of leaf pages for each is shown below.
I tested the following cases (Links show execution plans)
The reason for inclusion of the additional CTE option was in order to provide a CTE solution that would still work if the
indcolumn was not guaranteed sequential.All of the queries had a
CAST(col1 AS BIGINT)added in order to avoid overflow errors at runtime. Additionally for all of them I assigned the results to variables as above in order to eliminate time spent sending back results from consideration.Results
Both the correlated subquery and the
GROUP BYversion use "triangular" nested loop joins driven by a clustered index scan on theRunningTotalstable (T1) and, for each row returned by that scan, seeking back into the table (T2) self joining onT2.ind<=T1.ind.This means that the same rows get processed repeatedly. When the
T1.ind=1000row is processed the self join retrieves and sums all rows with anind <= 1000, then for the next row whereT1.ind=1001the same 1000 rows are retrieved again and summed along with one additional row and so on.The total number of such operations for a 2,000 row table is 2,001,000, for 10k rows 50,005,000 or more generally
(n² + n) / 2which clearly grows exponentially.In the 2,000 row case the main difference between the
GROUP BYand the subquery versions is that the former has the stream aggregate after the join and so has three columns feeding into it (T1.ind,T2.col1,T2.col1) and aGROUP BYproperty ofT1.indwhereas the latter is calculated as a scalar aggregate, with the stream aggregate before the join, only hasT2.col1feeding into it and has noGROUP BYproperty set at all. This simpler arrangement can be seen to have a measurable benefit in terms of reduced CPU time.For the 10,000 row case there is an additional difference in the sub query plan. It adds an eager spool which copies all the
ind,cast(col1 as bigint)values intotempdb. In the case that snapshot isolation is on this works out more compact than the clustered index structure and the net effect is to reduce the number of reads by about 25% (as the base table preserves quite a lot of empty space for versioning info), when this option is off it works out less compact (presumably due to thebigintvsintdifference) and more reads result. This reduces the gap between the sub query and group by versions but the sub query still wins.The clear winner however was the Recursive CTE. For the "no gaps" version logical reads from the base table are now
2 x (n + 1)reflecting thenindex seeks into the 2 level index to retrieve all of the rows plus the additional one at the end that returns nothing and terminates the recursion. That still meant 20,002 reads to process a 22 page table however!Logical work table reads for the recursive CTE version are very high. It seems to work out at 6 worktable reads per source row. These come from the index spool that stores the output of the previous row then is read from again in the next iteration (good explanation of this by Umachandar Jayachandran here). Despite the high number this is still the best performer.
我想你会发现递归 CTE 更快一些。
的,有。如果您正在寻找出色的性能,您应该只在简单的选择中提取数据,并在进行演示时在客户端上进行运行总计计算。
I think you will find the recursive CTE a bit faster.
Yes there is. If you are looking for outstanding performance you should just pull your data in a simple select and do the running total calculation on the client when you do the presentation.
您的问题不是很精确,因此这里有一些应该回答它的一般规则。
EXPLAIN比较查询。这将为您提供有关较大数据会发生什么情况的提示。Your question wasn't very precise, so here are a few general rules that should be answer it.
EXPLAINto compare the queries. This will give you hints on what will happen with larger data.