处理十亿条记录的推荐数据库类型
我开始参与一个项目,该项目必须重用 Microsoft SQL Server 2008 旧数据库,该数据库的表包含超过 7,000,000 条记录。
最后几分钟对该表的查询,我想知道是否使用不同类型的数据库(即非关系数据库)可以更好地处理这个问题。
你有什么建议吗?无论如何,有没有办法提高关系数据库的性能呢?
谢谢
更新:
我正在使用 Navicat 来执行这个简单的查询:
SELECT DISTINCT [NROCAJA]
FROM [CAJASE]
所以复杂的东西和子查询不是问题。我还想知道是否缺少索引是问题所在,但该表似乎已建立索引:
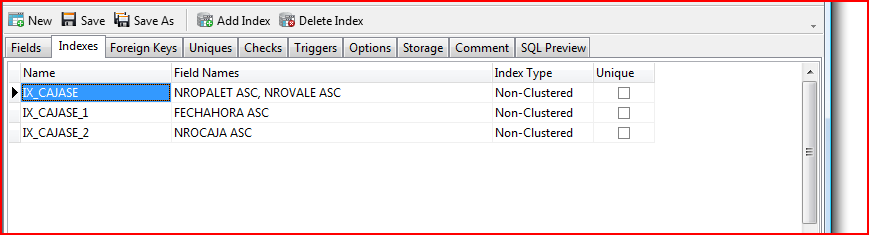
史诗般的失败:
数据库位于远程服务器中!查询实际上需要 5 秒(我仍然认为这是很多时间,但现在问题不同了)。 99%的时间都是网络传输。不管怎样,谢谢你的回答:)
I started to work in a project which must reuse a Microsoft SQL Server 2008 old database that has a table with more than 7,000,000 records.
Queries to that table last minutes and I was wondering if a different type of database (i.e. not relational) would be better to handle this.
What do you recommend? In any case, is there a way to improve the performance of a relational database?
Thanks
UPDATE:
I am using Navicat to perform this simple query:
SELECT DISTINCT [NROCAJA]
FROM [CAJASE]
so complex stuff and subqueries are not a problem. I was also wondering if a lack of indexes was the problem, but the table seems to be indexed:
EPIC FAIL:
The database was in a remote server!! The query actually takes 5 seconds (I still think it's much time, but now the issue is different). 99% of elapsed time was network transfer. Thanks for your answers anyway :)
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!




发布评论
评论(3)
700万是SQL Server的一个小型数据库,通过适当的设计,它可以轻松处理TB级数据。可能您的设计很差,索引缺失,硬件很差,查询性能很差。不要将数据库开发人员的无能归咎于 SQL Server。
7 million is a tiny database for SQL Server, it easily handles terrabytes of data with proper design. Likely you have a poor design combined with missing indexes combined with poor hardware, combined with badly performing queries. Don't blame the incompetence of your database developers on SQL Server.
分析您的查询 - 700 万条记录并不是一个很大的数字,因此您很可能会丢失索引或执行复杂的子查询,而这些子查询的性能随着数据集的扩展而表现不佳。
我认为您还不需要重新构建整个系统。
Profile your queries - 7 million records isn't that great a number, so chances are you're missing an index or performing complex sub-queries that are not performing well as the dataset scales.
I don't think you need to re-architect the entire system yet.
您选择“不同”的事实可能是一个问题。也许将这些不同的值移到它自己的表中以避免重复。
The fact that you are selecting "distinct" could be a problem. Maybe move those distinct value into it's own table to avoid duplication.