“来自不同的顶点链”是什么意思?在这个最近邻算法中?
以下伪代码来自算法设计手册在线预览版的第一章(第7页来自此 PDF)。
这个例子是一个有缺陷的算法,但我仍然很想理解它:
[...] 一个不同的想法可能是重复连接最近的一对 连接不会产生问题的端点,例如 周期提前终止。每个顶点都有自己的开始 单顶点链。将所有内容合并在一起后,我们最终会 包含其中所有点的单个链。连接 最后两个端点给了我们一个循环。执行过程中的任意一步 对于这个最近对启发式,我们将有一组单个顶点 和可合并的顶点不相交链。在伪代码中:
ClosestPair(P)
Let n be the number of points in set P.
For i = 1 to n − 1 do
d = ∞
For each pair of endpoints (s, t) from distinct vertex chains
if dist(s, t) ≤ d then sm = s, tm = t, and d = dist(s, t)
Connect (sm, tm) by an edge
Connect the two endpoints by an edge
请注意 sm 和 tm 应该是 sm 和 <代码>tm。
首先,我不明白“来自不同的顶点链”是什么意思。其次,i 在外循环中用作计数器,但 i 本身从未在任何地方实际使用过!有比我聪明的人可以解释一下这里到底发生了什么吗?
The following pseudo-code is from the first chapter of an online preview version of The Algorithm Design Manual (page 7 from this PDF).
The example is of a flawed algorithm, but I still really want to understand it:
[...] A different idea might be to repeatedly connect the closest pair of
endpoints whose connection will not create a problem, such as
premature termination of the cycle. Each vertex begins as its own
single vertex chain. After merging everything together, we will end up
with a single chain containing all the points in it. Connecting the
final two endpoints gives us a cycle. At any step during the execution
of this closest-pair heuristic, we will have a set of single vertices
and vertex-disjoint chains available to merge. In pseudocode:
ClosestPair(P)
Let n be the number of points in set P.
For i = 1 to n − 1 do
d = ∞
For each pair of endpoints (s, t) from distinct vertex chains
if dist(s, t) ≤ d then sm = s, tm = t, and d = dist(s, t)
Connect (sm, tm) by an edge
Connect the two endpoints by an edge
Please note that sm and tm should be sm and tm.
First of all, I don't understand what "from distinct vertex chains" would mean. Second, i is used as a counter in the outer loop, but i itself is never actually used anywhere! Could someone smarter than me please explain what's really going on here?
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!







发布评论
评论(4)
在欧内斯特·弗里德曼-希尔(Ernest Friedman-Hill)的解释(已接受的答案)之后,我是这样看的:
所以来自同一本书的例子(图1.4)。
我已向顶点添加了名称以使其清晰
所以第一步所有顶点都是单顶点链,所以我们连接 AD、BE 和 CF 对,b/ c 之间的距离最小。
在第二步中,我们有 3 条链,AD 和 BE 之间的距离与 BE 和 CF 之间的距离相同,因此我们将 AD 与 BE 连接起来,我们留下两条链 - ADEB 和 CF
在第三步中,有唯一的方法连接它们是通过 B 和 C,b/c BC 比 BF、AF 和 AC 短(记住我们只考虑链的端点)。所以我们现在有一条链 ADEBCF。
在最后一步,我们连接两个端点(A 和 F)以获得一个循环。
This is how I see it, after explanation of Ernest Friedman-Hill (accepted answer):
So the example from the same book (Figure 1.4).

I've added names to the vertices to make it clear
So at first step all the vertices are single vertex chains, so we connect A-D, B-E and C-F pairs, b/c distance between them is the smallest.
At the second step we have 3 chains and distance between A-D and B-E is the same as between B-E and C-F, so we connect let's say A-D with B-E and we left with two chains - A-D-E-B and C-F
At the third step there is the only way to connect them is through B and C, b/c B-C is shorter then B-F, A-F and A-C (remember we consider only endpoints of chains). So we have one chain now A-D-E-B-C-F.
At the last step we connect two endpoints (A and F) to get a cycle.
1)描述指出每个顶点总是要么属于“单顶点链”(即,它是单独的),要么属于另一个链;一个顶点只能属于一条链。该算法表示,在每一步中,您都会选择每对可能的两个顶点,这两个顶点都是它们所属的各自链的端点,并且尚未属于同一链。有时他们会是单身;有时他们会单身。有时,其中一个或两个已经属于一个重要的链,因此您将加入两个链。
2) 重复循环n次,以便最终选择每个顶点;但是,是的,实际的迭代计数没有用于任何用途。重要的是你运行循环的次数足够多。
1) The description states that every vertex always belongs either to a "single-vertex chain" (i.e., it's alone) or it belongs to one other chain; a vertex can only belong to one chain. The algorithm says at each step you select every possible pair of two vertices which are each an endpoint of the respective chain they belong to, and don't already belong to the same chain. Sometimes they'll be singletons; sometimes one or both will already belong to a non-trivial chain, so you'll join two chains.
2) You repeat the loop n times, so that you eventually select every vertex; but yes, the actual iteration count isn't used for anything. All that matters is that you run the loop enough times.
虽然问题已经得到解答,但这里有一个最近对启发式的 python 实现。它从每个点作为一条链开始,然后连续扩展链以构建一条包含所有点的长链。
该算法确实构建了一条路径,但它不是机器人手臂运动的序列,因为手臂起点未知。
Though question is already answered, here's a python implementation for closest pair heuristic. It starts with every point as a chain, then successively extending chains to build one long chain containing all points.
This algorithm does build a path yet it's not a sequence of robot arm movements for that arm starting point is unknown.
TLDR:如果已经熟悉本线程中提出的问题以及迄今为止提供的答案,请跳至下面的“ClestPair 启发式的澄清描述”部分。
备注:我最近开始学习算法设计手册,
ClosestPair启发式示例让我感到困扰,因为我觉得它缺乏清晰度。看来其他人也有类似的感受。不幸的是,这个帖子上提供的答案并没有完全适合我——我觉得它们对我来说都有点太模糊了。但这些答案确实帮助我朝着我认为对斯基纳的正确解释的方向前进。问题陈述和背景:来自本书第 5 页,供那些没有该书的人参考(第 3 版):
Skiena 首先详细介绍了如何
NearestNeighbor启发式是不正确的,使用下图来帮助说明他的情况:上图说明了
NearestNeighbor启发式,底部的数字是最优解。显然,需要采用不同的方法来找到最佳解决方案。提示ClosestPair启发式以及此问题的原因。书籍描述:书中概述了
ClosestPair启发式的以下描述:ClosestPair启发式的澄清描述首先“放大”一点并回答我们正在尝试寻找什么的基本问题可能会有所帮助用图论术语:
也就是说,我们想要找到一系列边
(e_1, e_2, ..., e_{n-1}),其中存在一系列顶点(v_1, v_2, ..., v_n)其中v_1 = v_n并且所有边都是不同的。边是加权的,其中每条边的权重只是构成该边的顶点之间的距离——我们希望最小化存在的任何闭合路径的总权重。实际上,
ClosestPair启发式为伪代码中外部for循环的每次迭代提供了这些不同的边之一(行3-10),其中内部for循环(第5-9行)确保在每个步骤中选择不同的边缘,(s_m, t_m),是由来自不同顶点链端点的顶点组成;也就是说,s_m来自一个顶点链的端点,而t_m来自另一个不同顶点链的端点。内部 for 循环只是确保我们考虑所有这些对,从而最小化过程中潜在顶点之间的距离。注意(顶点之间距离的关系):一个潜在的混乱来源是在两个
for循环中都没有指定任何“处理顺序”。我们如何确定比较端点以及这些端点的顶点的顺序?没关系。内部 for 循环的性质清楚地表明,在存在联系的情况下,将选择最近遇到的具有最小距离的顶点对。ClosestPair启发式的好实例回想一下应用
NearestNeighbor启发式的坏实例中发生的情况(观察新添加的顶点标签):总距离很荒谬,因为我们一直在
0上来回跳跃。现在考虑一下当我们使用
ClosestPair启发式时会发生什么。我们有n = 7个顶点;因此,伪代码表明外部for循环将执行 6 次。正如书中所指出的,每个顶点都以它自己的单个顶点链开始(即,每个点都是一个单例,其中单例是一条具有一个端点的链)。在我们的例子中,根据上图,内部for循环将执行多少次?那么,有多少种方法可以选择 n 元素集的 2 元素子集(即 2 元素子集代表潜在的顶点配对)?有n选择 2 这样的子集:因为
n = 7在我们的例子中,总共有 21 个可能的顶点配对需要研究。上图的性质清楚地表明,(C, D)和(D, E)是第一次迭代的唯一可能结果,因为它们之间的最小可能距离开头的顶点为 1,并且dist(C, D) = dist(D, E) = 1。由于没有处理顺序,因此尚不清楚实际上连接哪些顶点来给出第一条边(C, D)或(D, E)。假设我们最后遇到顶点D和E,从而导致(D, E)作为我们的第一条边。现在还有 5 次迭代需要进行,并且需要考虑 6 个顶点链:
A、B、C、(D、E)、F、G。注意(每次迭代都会消除一个顶点链):
ClosestPair启发式中的外部for循环的每次迭代都会导致消除一个顶点链。外部 for 循环迭代继续,直到留下由所有顶点组成的单个顶点链,其中最后一步是通过边连接该单个顶点链的两个端点。更准确地说,对于由n个顶点组成的图G,我们从n个顶点链开始(即,每个顶点作为其自己的单个顶点开始)链)。外部for循环的每次迭代都会导致连接G的两个顶点,这些顶点来自不同的顶点链;也就是说,连接这些顶点会导致将两个不同的顶点链合并为一个,从而使剩下要考虑的顶点链总数减1。对于具有 n 个顶点的图重复此过程 n - 1 次会导致留下 n - (n - 1) = 1顶点链,包含 G 中所有点的单链。连接最后两个端点给我们一个循环。每次迭代的一种可能的描述如下:
因此,在本示例中,
ClosestPair启发式做了正确的事情,而之前NearestNeighbor启发式做了错误的事情:ClosestPair启发式的错误实例考虑
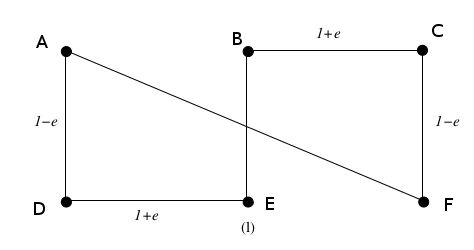
ClosestPair算法对下图中的点集执行的操作(首先尝试想象一下可能会有所帮助)没有任何边连接顶点的点集):我们如何使用
ClosestPair连接顶点?我们有 n = 6 个顶点;因此,外部for循环将执行6 - 1 = 5次,其中我们的首要任务是调查所有可能对的顶点之间的距离。上图帮助我们看到
dist(A, D) = dist(B, E) = dist(C, F) = 1 - ɛ是自以来第一次迭代中唯一可能的选项>1 - ɛ是任意两个顶点之间的最短距离。我们任意选择(A, D)作为第一个配对。现在还有 4 次迭代需要进行,并且需要考虑 5 个顶点链:
(A, D)、B、C、E、F。每次迭代的一种可能的描述如下:注意(正确考虑从不同顶点链连接的端点):上面描述的迭代
1-3在我们没有其他有意义的选择可以考虑。即使我们有了不同的顶点链(A, D)、(B, E)和(C, F),下一个选择同样是平淡无奇且随意的。鉴于第四次迭代中顶点之间的最小可能距离为1 + ɛ,有四种可能性:(A, B), (D, E), (B, C), ( E,F)。上述所有点的顶点之间的距离为1 + ɛ。(D, E)的选择是任意的。其他三个顶点配对中的任何一个都可以发挥同样的作用。但请注意迭代5期间发生的情况——我们对顶点配对的可能选择已经被严格缩小。具体来说,顶点链(A, D, E, B)和(C, F)具有端点(A, B)和 (C, F) 分别只允许四种可能的顶点配对:(A, C)、(A, F)、(B, C)、(B, F) 。即使这看起来很明显,但值得注意的是,D和E都不是上面可行的候选顶点——这两个顶点都不包含在端点中,( A, B),它们为顶点的顶点链,即(A, D, E, B)。现阶段没有任意选择。上面对中的顶点之间的距离没有联系。(B, C)配对产生顶点之间的最小距离:1 + ɛ。一旦顶点B和C通过边连接起来,所有迭代都已完成,我们只剩下一个顶点链:(A, D, E ,B,C,F)。连接A和F给我们一个循环并结束这个过程。穿过
(A, D, E, B, C, F)的总距离如下:上面的距离计算为
5 - ɛ + √(5ɛ^2 + 6ɛ + 5 ),而不是仅绕边界行驶的总距离(上图中右侧的图,所有边缘都涂成红色):6 + 2ɛ。作为ɛ -> 0,我们看到5 + √5 ≈ 7.24 > 6其中6是必要的行程量。 我们最终会走得比需要的更远。因此,在这种情况下,通过使用
ClosestPair启发式,TLDR: Skip to the section "Clarified description of ClosestPair heuristic" below if already familiar with the question asked in this thread and the answers contributed thus far.
Remarks: I started the Algorithm Design Manual recently and the
ClosestPairheuristic example bothered me because of what I felt like was a lack of clarity. It looks like others have felt similarly. Unfortunately, the answers provided on this thread didn't quite do it for me--I felt like they were all a bit too vague and hand-wavy for me. But the answers did help nudge me in the direction of what I feel is the correct interpretation of Skiena's.Problem statement and background: From page 5 of the book for those who don't have it (3rd edition):
Skiena first details how the
NearestNeighborheuristic is incorrect, using the following image to help illustrate his case:The figure on top illustrates a problem with the approach employed by the
NearestNeighborheuristic, with the bottom figure being the optimal solution. Clearly a different approach is needed to find this optimal solution. Cue theClosestPairheuristic and the reason for this question.Book description: The following description of the
ClosestPairheuristic is outlined in the book:Clarified description of
ClosestPairheuristicIt may help to first "zoom back" a bit and answer the basic question of what we are trying to find in graph theory terms:
That is, we want to find a sequence of edges
(e_1, e_2, ..., e_{n-1})for which there is a sequence of vertices(v_1, v_2, ..., v_n)wherev_1 = v_nand all edges are distinct. The edges are weighted, where the weight for each edge is simply the distance between vertices that comprise the edge--we want to minimize the overall weight of whatever closed trails exist.Practically speaking, the
ClosestPairheuristic gives us one of these distinct edges for every iteration of the outerforloop in the pseudocode (lines3-10), where the innerforloop (lines5-9) ensures the distinct edge being selected at each step,(s_m, t_m), is comprised of vertices coming from the endpoints of distinct vertex chains; that is,s_mcomes from the endpoint of one vertex chain andt_mfrom the endpoint of another distinct vertex chain. The innerforloop simply ensures we consider all such pairs, minimizing the distance between potential vertices in the process.Note (ties in distance between vertices): One potential source of confusion is that no sort of "processing order" is specified in either
forloop. How do we determine the order in which to compare endpoints and, furthermore, the vertices of those endpoints? It doesn't matter. The nature of the innerforloop makes it clear that, in the case of ties, the most recently encountered vertex pairing with minimal distance is chosen.Good instance of
ClosestPairheuristicRecall what happened in the bad instance of applying the
NearestNeighborheuristic (observe the newly added vertex labels):The total distance covered was absurd because we kept jumping back and forth over
0.Now consider what happens when we use the
ClosestPairheuristic. We haven = 7vertices; hence, the pseudocode indicates that the outerforloop will be executed 6 times. As the book notes, each vertex begins as its own single vertex chain (i.e., each point is a singleton where a singleton is a chain with one endpoint). In our case, given the figure above, how many times will the innerforloop execute? Well, how many ways are there to choose a 2-element subset of ann-element set (i.e., the 2-element subsets represent potential vertex pairings)? There arenchoose 2 such subsets:Since
n = 7in our case, there's a total of 21 possible vertex pairings to investigate. The nature of the figure above makes it clear that(C, D)and(D, E)are the only possible outcomes from the first iteration since the smallest possible distance between vertices in the beginning is 1 anddist(C, D) = dist(D, E) = 1. Which vertices are actually connected to give the first edge,(C, D)or(D, E), is unclear since there is no processing order. Let's assume we encounter verticesDandElast, thus resulting in(D, E)as our first edge.Now there are 5 more iterations to go and 6 vertex chains to consider:
A, B, C, (D, E), F, G.Note (each iteration eliminates a vertex chain): Each iteration of the outer
forloop in theClosestPairheuristic results in the elimination of a vertex chain. The outerforloop iterations continue until we are left with a single vertex chain comprised of all vertices, where the last step is to connect the two endpoints of this single vertex chain by an edge. More precisely, for a graphGcomprised ofnvertices, we start withnvertex chains (i.e., each vertex begins as its own single vertex chain). Each iteration of the outerforloop results in connecting two vertices ofGin such a way that these vertices come from distinct vertex chains; that is, connecting these vertices results in merging two distinct vertex chains into one, thus decrementing by 1 the total number of vertex chains left to consider. Repeating such a processn - 1times for a graph that hasnvertices results in being left withn - (n - 1) = 1vertex chain, a single chain containing all the points ofGin it. Connecting the final two endpoints gives us a cycle.One possible depiction of how each iteration looks is as follows:
Hence, the
ClosestPairheuristic does the right thing in this example where previously theNearestNeighborheuristic did the wrong thing:Bad instance of
ClosestPairheuristicConsider what the
ClosestPairalgorithm does on the point set in the figure below (it may help to first try imagining the point set without any edges connecting the vertices):How can we connect the vertices using
ClosestPair? We haven = 6vertices; thus, the outerforloop will execute6 - 1 = 5times, where our first order of business is to investigate the distance between vertices oftotal possible pairs. The figure above helps us see that
dist(A, D) = dist(B, E) = dist(C, F) = 1 - ɛare the only possible options in the first iteration since1 - ɛis the shortest distance between any two vertices. We arbitrarily choose(A, D)as the first pairing.Now are there are 4 more iterations to go and 5 vertex chains to consider:
(A, D), B, C, E, F. One possible depiction of how each iteration looks is as follows:Note (correctly considering the endpoints to connect from distinct vertex chains): Iterations
1-3depicted above are fairly uneventful in the sense that we have no other meaningful options to consider. Even once we have the distinct vertex chains(A, D),(B, E), and(C, F), the next choice is similarly uneventful and arbitrary. There are four possibilities given that the smallest possible distance between vertices on the fourth iteration is1 + ɛ:(A, B), (D, E), (B, C), (E, F). The distance between vertices for all of the points above is1 + ɛ. The choice of(D, E)is arbitrary. Any of the other three vertex pairings would have worked just as well. But notice what happens during iteration5--our possible choices for vertex pairings have been tightly narrowed. Specifically, the vertex chains(A, D, E, B)and(C, F), which have endpoints(A, B)and(C, F), respectively, allow for only four possible vertex pairings:(A, C), (A, F), (B, C), (B, F). Even if it may seem obvious, it is worth explicitly noting that neitherDnorEwere viable vertex candidates above--neither vertex is included in the endpoint,(A, B), of the vertex chain of which they are vertices, namely(A, D, E, B). There is no arbitrary choice at this stage. There are no ties in the distance between vertices in the pairs above. The(B, C)pairing results in the smallest distance between vertices:1 + ɛ. Once verticesBandChave been connected by an edge, all iterations have been completed and we are left with a single vertex chain:(A, D, E, B, C, F). ConnectingAandFgives us a cycle and concludes the process.The total distance traveled across
(A, D, E, B, C, F)is as follows:The distance above evaluates to
5 - ɛ + √(5ɛ^2 + 6ɛ + 5)as opposed to the total distance traveled by just going around the boundary (the right-hand figure in the image above where all edges are colored in red):6 + 2ɛ. Asɛ -> 0, we see that5 + √5 ≈ 7.24 > 6where6was the necessary amount of travel. Hence, we end up traveling aboutfarther than is necessary by using the
ClosestPairheuristic in this case.