MySQL 对于重音字符太聪明了
我想,通常人们的目标是让他们的程序像这样运行,但就我而言,这与我想要的完全相反。
不知何故,我的 MySQL 数据库能够将不同的重音字符读取为相同的。例如,shī、shí、shǐ、shì 和 shi 都是同样的事情。当我寻找一个时,我也会找到其他的。证明图片:
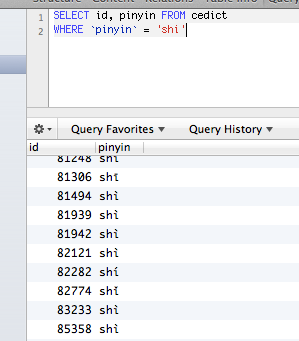
这不是我想要的,因为对我来说这些值非常不同。基本上,图片上的查询必须返回空行,因为该表中没有任何带有 shi (不带重音符号)的条目。
我的表类型是 InnoDB,排序规则是 utf8_general_ci 。
I guess, normally people would be aiming to make their programme behave like this, but in my case this is completely opposite from what I want.
Somehow, my MySQL database is able to read different accented characters as identical. For instance, shī, shí, shǐ, shì and shi are all the same thing to it. When I search for one, I’ll get the others as well. Proofpic:
This is not what I want, since for me those values are very different. Basically, the query on the pic must return empty rows, because there is no a single entry in that table with shi (without an accent).
My tables type is InnoDB, collation is utf8_general_ci.
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!



发布评论
评论(1)
使用
utf8_bin排序规则。您不必更改整个列的排序规则,您只需在每个查询的基础上使用它您还可以尝试不同的排序规则,这可能更适合您(
utf8_bin适用于二进制级别,因此即使如果两个具有不同字节码的 unicode 字符相同,则会将它们视为不同)。Use
utf8_bincollation. You don't have to change collation of entire column, you can just use it on per query basisYou can also experiment with different collations which might work better for you (
utf8_binworks on binery level, so even if two unicode characters with different byte codes are the same, it will see them as different).