使用 Scrapy for Python 从 html 路径中提取数据
我的项目概述:
我正在尝试在 python 2.6 中创建一个简单的脚本,该脚本将从 Bing 地图获取交通时间数据。我使用 Scrapy 库模块包 (scrapy.org/) 来爬行每个网站并从 Bing 地图中提取数据。
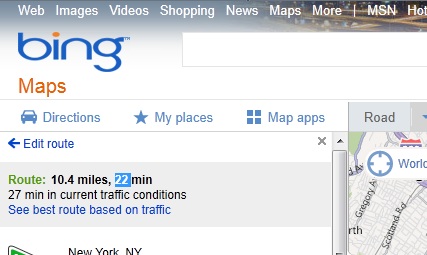
上面的图片显示了我想要的。 (现在突出显示的数据部分,但最终也需要下面的时间。)
我首先做了一个测试,看看起始网址是否会通过。然后使用输出日志打印 url 的输出(如果成功通过)。一旦成功,我的下一步就是尝试从网页中提取我需要的数据。
我一直在使用 Firebug、XPather 和 XPath Firefox Add-ons 来查找我想要提取的数据的 html 路径。此链接对于指导我正确编码路径非常有帮助(doc.scrapy.org/topics/selectors.html)。通过查看 firebug,这就是我想要提取的内容...
<span class="time">22 min</span>
并且 XPather 将其显示为该特定项目的路径。 ...
/div[@id='TaskHost_DrivingDirectionsSummaryContainer']/div[1]/span[3]
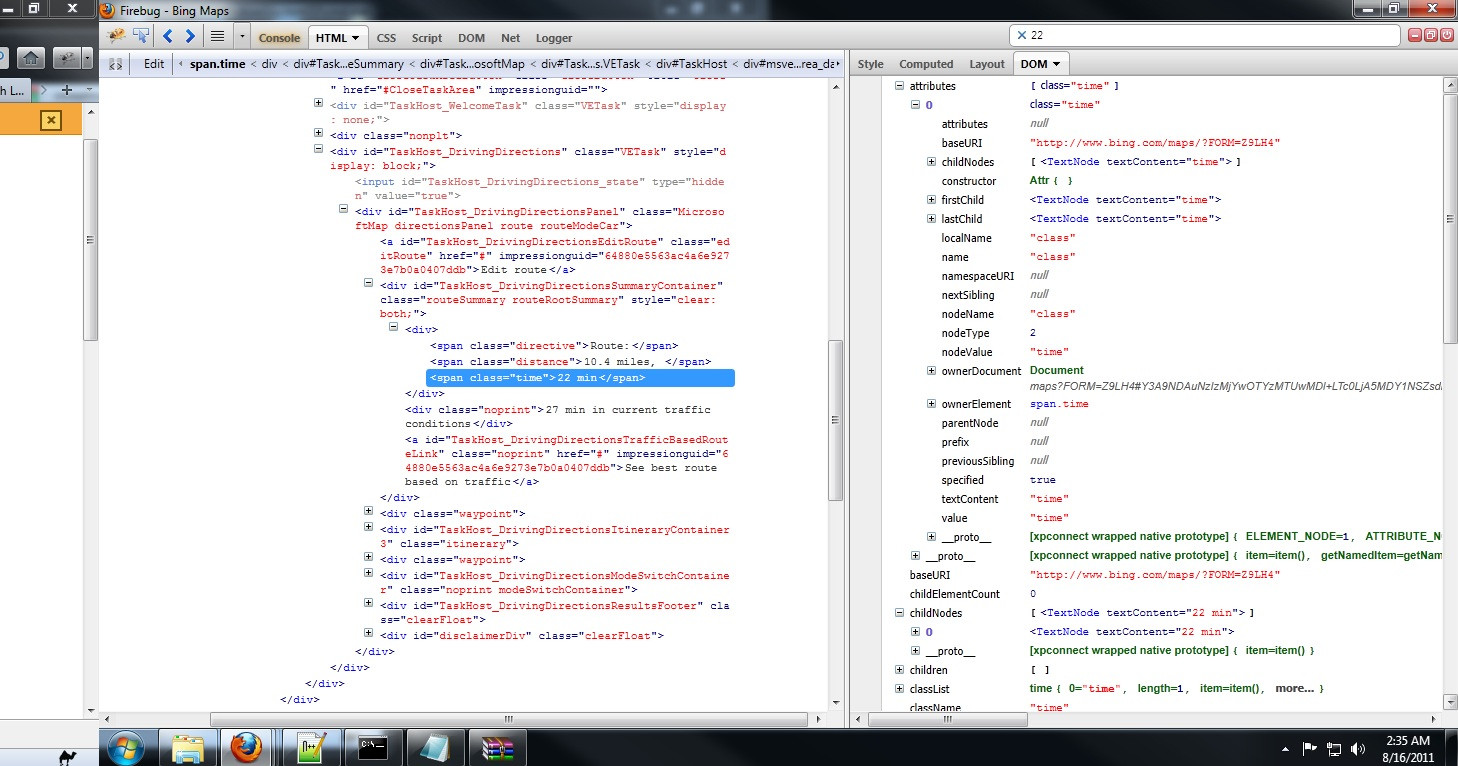
当我使用上面给定的路径在 cmd 中运行程序时,提取的数据打印为 [ ] ,当我将 /class='time' 添加到 span 末尾时,数据打印输出为 [u'False' ]。当仔细查看 firebug 的 DOM 窗口时,我注意到 class="time" 对于 get isID 为 false,并且 childNode 保存了我需要的数据。如何从childNode中提取数据?
下面是我到目前为止的代码
from scrapy import log # This module is useful for printing out debug information
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector, XPathSelectorList, XmlXPathSelector
import html5lib
class BingSpider(BaseSpider):
name = 'bing.com/maps'
allowed_domains = ["bing.com/maps"]
start_urls = [
"http://www.bing.com/maps/?FORM=Z9LH4#Y3A9NDAuNjM2MDAxNTg1OTk5OTh+LTc0LjkxMTAwMzExMiZsdmw9OCZzdHk9ciZydHA9cG9zLjQwLjcxNDU0OF8tNzQuMDA3MTI1X05ldyUyMFlvcmslMkMlMjBOWV9fX2VffnBvcy40MC43MzE5N18tNzQuMTc0MTg1MDAwMDAwMDRfTmV3YXJrJTJDJTIwTkpfX19lXyZtb2RlPUQmcnRvcD0wfjB+MH4="
]
def parse(self, response):
self.log('A response from %s just arrived!' % response.url)
x = HtmlXPathSelector(response)
time=x.select("//div[@id='TaskHost_DrivingDirectionsSummaryContainer']/div[1]/span[3]").extract()
print time
CMD输出
2011-09-05 17:43:01-0400 [scrapy] DEBUG: Enabled item pipelines:
2011-09-05 17:43:01-0400 [scrapy] DEBUG: Telnet console listening on 0.0.0.0:602
3
2011-09-05 17:43:01-0400 [scrapy] DEBUG: Web service listening on 0.0.0.0:6080
2011-09-05 17:43:01-0400 [bing.com] INFO: Spider opened
2011-09-05 17:43:02-0400 [bing.com] DEBUG: Crawled (200) <GET http://www.bing.co
m/maps/#Y3A9NDAuNzIzMjYwOTYzMTUwMDl+LTc0LjA5MDY1NSZsdmw9MTImc3R5PXImcnRwPXBvcy40
MC43MzE5N18tNzQuMTc0MTg1X05ld2FyayUyQyUyME5KX19fZV9+cG9zLjQwLjcxNDU0OF8tNzQuMDA3
MTI0OTk5OTk5OTdfTmV3JTIwWW9yayUyQyUyME5ZX19fZV8mbW9kZT1EJnJ0b3A9MH4wfjB+> (refer
er: None)
2011-09-05 17:43:02-0400 [bing.com] DEBUG: A response from http://www.bing.com/m
aps/ just arrived!
[]
2011-09-05 17:43:02-0400 [bing.com] INFO: Closing spider (finished)
2011-09-05 17:43:02-0400 [bing.com] INFO: Spider closed (finished)
Overview of my project:
I'm trying to create a simple script in python 2.6 that will get traffic time data from Bing Maps. The Scrapy library module package (scrapy.org/) is what I'm using to crawl through each website and extract data from Bing maps.
The picture above shows what i want. (the highlighted data part for now but ultimately the time below will be needed too.)
I first did a test to see if the start url would go though. and then used an output log to print the output of the url if it successfully went through. Once that worked, my next step was to try and extract the data i need from the webpage.
I have been using Firebug, XPather, and XPath Firefox Add-ons to find the html path of the data I want to extract. This link has been pretty helpful in guiding me in correctly coding the path's (doc.scrapy.org/topics/selectors.html). From looking at firebug, this is what i want to extract...
<span class="time">22 min</span>
and XPather shows this as the path for this particular item. ...
/div[@id='TaskHost_DrivingDirectionsSummaryContainer']/div[1]/span[3]
When i run the program in cmd with the given path above, the extracted data prints out as [ ] and when i add /class='time' to the end of span, the data print out is [u'False']. When looking at a bit closer in the DOM window of firebug, I noticed that class="time" is false for get isID and the the the childNode held the data i needed. How do i extract the data from the childNode?
Below is my code so far
from scrapy import log # This module is useful for printing out debug information
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector, XPathSelectorList, XmlXPathSelector
import html5lib
class BingSpider(BaseSpider):
name = 'bing.com/maps'
allowed_domains = ["bing.com/maps"]
start_urls = [
"http://www.bing.com/maps/?FORM=Z9LH4#Y3A9NDAuNjM2MDAxNTg1OTk5OTh+LTc0LjkxMTAwMzExMiZsdmw9OCZzdHk9ciZydHA9cG9zLjQwLjcxNDU0OF8tNzQuMDA3MTI1X05ldyUyMFlvcmslMkMlMjBOWV9fX2VffnBvcy40MC43MzE5N18tNzQuMTc0MTg1MDAwMDAwMDRfTmV3YXJrJTJDJTIwTkpfX19lXyZtb2RlPUQmcnRvcD0wfjB+MH4="
]
def parse(self, response):
self.log('A response from %s just arrived!' % response.url)
x = HtmlXPathSelector(response)
time=x.select("//div[@id='TaskHost_DrivingDirectionsSummaryContainer']/div[1]/span[3]").extract()
print time
CMD output
2011-09-05 17:43:01-0400 [scrapy] DEBUG: Enabled item pipelines:
2011-09-05 17:43:01-0400 [scrapy] DEBUG: Telnet console listening on 0.0.0.0:602
3
2011-09-05 17:43:01-0400 [scrapy] DEBUG: Web service listening on 0.0.0.0:6080
2011-09-05 17:43:01-0400 [bing.com] INFO: Spider opened
2011-09-05 17:43:02-0400 [bing.com] DEBUG: Crawled (200) <GET http://www.bing.co
m/maps/#Y3A9NDAuNzIzMjYwOTYzMTUwMDl+LTc0LjA5MDY1NSZsdmw9MTImc3R5PXImcnRwPXBvcy40
MC43MzE5N18tNzQuMTc0MTg1X05ld2FyayUyQyUyME5KX19fZV9+cG9zLjQwLjcxNDU0OF8tNzQuMDA3
MTI0OTk5OTk5OTdfTmV3JTIwWW9yayUyQyUyME5ZX19fZV8mbW9kZT1EJnJ0b3A9MH4wfjB+> (refer
er: None)
2011-09-05 17:43:02-0400 [bing.com] DEBUG: A response from http://www.bing.com/m
aps/ just arrived!
[]
2011-09-05 17:43:02-0400 [bing.com] INFO: Closing spider (finished)
2011-09-05 17:43:02-0400 [bing.com] INFO: Spider closed (finished)
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!




发布评论
评论(2)
当网站大量使用 JavaScript 时,您不能信任运行时获得的 XPath,因为那是 JavaScript 代码运行后获得的 XPath,而 Scrapy 不运行 JavaScript 代码。
您应该:
打开网络浏览器开发人员工具的“网络”选项卡。
在网站上执行获取所需数据的步骤,同时您在“网络”选项卡上观看网站执行的相应请求。
尝试使用 Scrapy 重现这些步骤(请求)。
另请参阅调试蜘蛛。
When a website uses JavaScript in a significant way, you cannot trust the XPath you get at runtime, because that is the XPath you get after the JavaScript code has run, and Scrapy does not run JavaScript code.
You should:
Open the Network tab of the developer tools of your web browser.
Perform on the website the steps to get to the desired data, while you watch the corresponding requests performed by the website on the Network tab.
Try to reproduce those steps (requests) with Scrapy.
See also Debugging Spiders.
对于所有抓取目的,请使用 BeautifulSoup
For all scrapping purposes use BeautifulSoup