Node.js / Coffeescript 在数学密集型算法上的性能
我正在尝试使用 node.js 来构建一些服务器端逻辑,并实现了描述的钻石方形算法的版本 这里 在coffeescript 和Java 中。鉴于我听到的所有对 Node.js 和 V8 性能的赞扬,我希望 Node.js 不会落后于 java 版本太多。
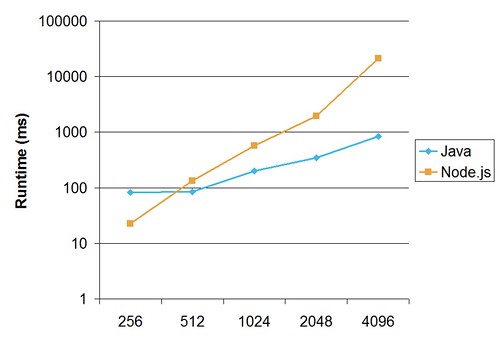
然而,在 4096x4096 地图上,Java 在 1 秒内完成,但 node.js/coffeescript 在我的机器上花费了 20 秒以上......
这些是我的完整结果。 x 轴是网格大小。对数和线性图表:


这是因为有我的 Coffeescript 实现有问题,或者这仍然是 Node.js 的本质?
脚本
genHeightField = (sz) ->
timeStart = new Date()
DATA_SIZE = sz
SEED = 1000.0
data = new Array()
iters = 0
# warm up the arrays to tell the js engine these are dense arrays
# seems to have neligible effect when running on node.js though
for rows in [0...DATA_SIZE]
data[rows] = new Array();
for cols in [0...DATA_SIZE]
data[rows][cols] = 0
data[0][0] = data[0][DATA_SIZE-1] = data[DATA_SIZE-1][0] =
data[DATA_SIZE-1][DATA_SIZE-1] = SEED;
h = 500.0
sideLength = DATA_SIZE-1
while sideLength >= 2
halfSide = sideLength / 2
for x in [0...DATA_SIZE-1] by sideLength
for y in [0...DATA_SIZE-1] by sideLength
avg = data[x][y] +
data[x + sideLength][y] +
data[x][y + sideLength] +
data[x + sideLength][y + sideLength]
avg /= 4.0;
data[x + halfSide][y + halfSide] =
avg + Math.random() * (2 * h) - h;
iters++
#console.log "A:" + x + "," + y
for x in [0...DATA_SIZE-1] by halfSide
y = (x + halfSide) % sideLength
while y < DATA_SIZE-1
avg =
data[(x-halfSide+DATA_SIZE-1)%(DATA_SIZE-1)][y]
data[(x+halfSide)%(DATA_SIZE-1)][y]
data[x][(y+halfSide)%(DATA_SIZE-1)]
data[x][(y-halfSide+DATA_SIZE-1)%(DATA_SIZE-1)]
avg /= 4.0;
avg = avg + Math.random() * (2 * h) - h;
data[x][y] = avg;
if x is 0
data[DATA_SIZE-1][y] = avg;
if y is 0
data[x][DATA_SIZE-1] = avg;
#console.log "B: " + x + "," + y
y += sideLength
iters++
sideLength /= 2
h /= 2.0
#console.log iters
console.log (new Date() - timeStart)
genHeightField(256+1)
genHeightField(512+1)
genHeightField(1024+1)
genHeightField(2048+1)
genHeightField(4096+1)
Java
import java.util.Random;
class Gen {
public static void main(String args[]) {
genHeight(256+1);
genHeight(512+1);
genHeight(1024+1);
genHeight(2048+1);
genHeight(4096+1);
}
public static void genHeight(int sz) {
long timeStart = System.currentTimeMillis();
int iters = 0;
final int DATA_SIZE = sz;
final double SEED = 1000.0;
double[][] data = new double[DATA_SIZE][DATA_SIZE];
data[0][0] = data[0][DATA_SIZE-1] = data[DATA_SIZE-1][0] =
data[DATA_SIZE-1][DATA_SIZE-1] = SEED;
double h = 500.0;
Random r = new Random();
for(int sideLength = DATA_SIZE-1;
sideLength >= 2;
sideLength /=2, h/= 2.0){
int halfSide = sideLength/2;
for(int x=0;x<DATA_SIZE-1;x+=sideLength){
for(int y=0;y<DATA_SIZE-1;y+=sideLength){
double avg = data[x][y] +
data[x+sideLength][y] +
data[x][y+sideLength] +
data[x+sideLength][y+sideLength];
avg /= 4.0;
data[x+halfSide][y+halfSide] =
avg + (r.nextDouble()*2*h) - h;
iters++;
//System.out.println("A:" + x + "," + y);
}
}
for(int x=0;x<DATA_SIZE-1;x+=halfSide){
for(int y=(x+halfSide)%sideLength;y<DATA_SIZE-1;y+=sideLength){
double avg =
data[(x-halfSide+DATA_SIZE-1)%(DATA_SIZE-1)][y] +
data[(x+halfSide)%(DATA_SIZE-1)][y] +
data[x][(y+halfSide)%(DATA_SIZE-1)] +
data[x][(y-halfSide+DATA_SIZE-1)%(DATA_SIZE-1)];
avg /= 4.0;
avg = avg + (r.nextDouble()*2*h) - h;
data[x][y] = avg;
if(x == 0) data[DATA_SIZE-1][y] = avg;
if(y == 0) data[x][DATA_SIZE-1] = avg;
iters++;
//System.out.println("B:" + x + "," + y);
}
}
}
//System.out.print(iters +" ");
System.out.println(System.currentTimeMillis() - timeStart);
}
}
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!




发布评论
评论(4)
正如其他回答者所指出的,JavaScript 的数组是您正在执行的操作类型的主要性能瓶颈。因为它们是动态的,所以访问元素自然比使用 Java 的静态数组慢得多。
好消息是 JavaScript 中的静态类型数组出现了一个新兴标准,某些浏览器已经支持该标准。虽然 Node 本身尚不支持,但您可以使用库轻松添加它们:https://github。 com/tlrobinson/v8-typed-array
通过 npm 安装
typed-array后,这是我对代码的修改版本:其中的关键行是
data[ 的声明行]。通过行
data[rows] = new Array(DATA_SIZE)(基本上与原始行相同),我得到了基准数字:并且通过行
data[rows] = new Float32Array(DATA_SIZE) ),我明白了,一个小小的改变就能将运行时间减少大约 1/3,即速度提高 50%!
它仍然不是 Java,但这是一个相当大的改进。预计 Node/V8 的未来版本将进一步缩小性能差距。
警告: 需要注意的是,普通的 JS 数字是双精度的,即 64 位浮点数。因此,使用 Float32Array 会降低精度,这有点像苹果和橘子的比较——我不知道使用 32 位数学有多少性能改进,以及有多少改进。来自更快的数组访问。
Float64Array是 V8 规范的一部分,但尚未在 v8-typed-array 库。)As other answerers have pointed out, JavaScript's arrays are a major performance bottleneck for the type of operations you're doing. Because they're dynamic, it's naturally much slower to access elements than it is with Java's static arrays.
The good news is that there is an emerging standard for statically typed arrays in JavaScript, already supported in some browsers. Though not yet supported in Node proper, you can easily add them with a library: https://github.com/tlrobinson/v8-typed-array
After installing
typed-arrayvia npm, here's my modified version of your code:The key line in there is the declaration of
data[rows].With the line
data[rows] = new Array(DATA_SIZE)(essentially equivalent to the original), I get the benchmark numbers:And with the line
data[rows] = new Float32Array(DATA_SIZE), I getSo that one small change cuts the running time down by about 1/3, i.e. a 50% speed increase!
It's still not Java, but it's a pretty substantial improvement. Expect future versions of Node/V8 to narrow the performance gap further.
Caveat: It's got to be mentioned that normal JS numbers are double-precision, i.e. 64-bit floats. Using
Float32Arraywill thus reduce precision, making this a bit of an apples-and-oranges comparison—I don't know how much of the performance improvement is from using 32-bit math, and how much is from faster array access. AFloat64Arrayis part of the V8 spec, but isn't yet implemented in the v8-typed-array library.)如果您正在寻找这样的算法的性能,那么咖啡/js 和 Java 都是错误的语言。 Javascript 对于此类问题尤其糟糕,因为它没有数组类型 - 数组只是哈希映射,其中键必须是整数,这显然不会像真正的数组那么快。您想要的是用 C 语言编写此算法并从节点调用该算法(请参阅 http: //nodejs.org/docs/v0.4.10/api/addons.html)。除非您真的擅长手动优化机器代码,否则优秀的 C 语言将轻松超越任何其他语言。
If you're looking for performance in algorithms like this, both coffee/js and Java are the wrong languages to be using. Javascript is especially poor for problems like this because it does not have an array type - arrays are just hash maps where keys must be integers, which obviously will not be as quick as a real array. What you want is to write this algorithm in C and call that from node (see http://nodejs.org/docs/v0.4.10/api/addons.html). Unless you're really good at hand-optimizing machine code, good C will easily outstrip any other language.
暂时忘记 Coffeescript,因为那不是问题的根源。无论如何,当节点运行该代码时,该代码都会被写入常规的旧 JavaScript。
就像任何其他 javascript 环境一样,node 是单线程的。 V8 引擎速度非常快,但对于某些类型的应用程序,您可能无法超过 jvm 的速度。
我首先建议在转向 CS 之前尝试直接在 js 中纠正钻石算法。查看您可以进行哪些类型的速度优化。
事实上,我现在也对这个问题感兴趣,并且打算考虑这样做。
编辑 #2 这是我第二次重写,进行了一些优化,例如预填充数据数组。它的速度并没有明显加快,但代码更加简洁。
Forget about Coffeescript for a minute, because that's not the root of the problem. That code just gets written to regular old javascript anyway when node runs it.
Just like any other javascript environment, node is single-threaded. The V8 engine is bloody fast, but for certain types of applications you might not be able to exceed the speed of the jvm.
I would first suggest trying to right out your diamond algorithm directly in js before moving to CS. See what kinds of speed optimizations you can make.
Actually, I'm kind of interested in this problem now too and am going to take a look at doing this.
Edit #2 This is my 2nd re-write with some optimizations such as pre-populating the data array. Its not significantly faster, but the code is a bit cleaner.
我一直认为,当人们将 javascript 运行时描述为“快”时,他们的意思是相对于其他解释型动态语言。与 ruby、python 或smalltalk 进行比较会很有趣。将 JavaScript 与 Java 进行比较并不是一个公平的比较。
为了回答你的问题,我相信你所看到的结果表明了你可以期望比较这两种截然不同的语言。
I have always assumed that when people described javascript runtime's as 'fast' they mean relative to other interpreted, dynamic languages. A comparison to ruby, python or smalltalk would be interesting. Comparing JavaScript to Java is not a fair comparison.
To answer your question, I believe that the results you are seeing are indicative of what you can expect comparing these two vastly different languages.