如何提取汉字的笔画
我多次尝试创建一种算法来从汉字中提取笔画信息。我尝试了各种方法,但没有一个非常令人满意,可能是因为我对图形算法的了解有限。
基本上,我有以下数据:
汉字,可以是像素或矢量(黑色)
整体笔画的轮廓,以像素为单位(红色)
总体方向(蓝色箭头)。
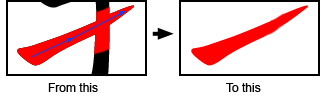
由此,我尝试提取笔划。如果您必须这样做,根据可用数据,您会使用什么方法?你能想到任何自动提取笔划的方法吗?
I've been trying many times to create an algorithm to extract stroke information from Chinese characters. I've tried various methods but none was very satisfying, probably because of my limited knowledge of graphics algorithms in general.
Basically, I have the following data:
The Chinese character, which can be either pixels or vector (in black)
The overall outline of the stroke, in pixels (in red)
An overall direction (the blue arrows).
From this, I'm trying to extract the stroke. If you had to do this, given the available data, what methods would you use? Can you think of any automatic way to extract the stroke?
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!




发布评论
评论(5)
我首先计算每个蓝色像素到最近的白色像素的距离。然后你可以保留所有比最近的白色像素更近的红色像素。之后可以使用一些过滤器来平滑效果(可能类似于 侵蚀,然后是关闭)。
I'd start with calculating the distance to the nearest white pixel from each blue pixel. Then you can keep all the red pixels which are closer than the nearest white pixel. The effect may be smoothed with some filter afterwards (maybe something like an erosion followed by a close).
您可能正在寻找内侧轴,也称为拓扑骨架。简而言之,您将解决找到与边缘上多个点等距的所有点的问题。您可能需要对结果曲线进行一些平滑或简化。
棘手的部分是分离多个笔画所共有的形状部分。我不相信有明确的方法可以做到这一点。也许将“公共区域”定义为以每个骨架交叉点为中心、与最近的边缘相切的圆?那么也许可以对间隙上的笔划宽度进行一些插值?
You might be looking for the medial axis, also known as the topological skeleton. In short, you will solve to find all points that are equidistant to more than one point on the edge. You may need to do some smoothing or simplification of the resultant curve.
The tricky part is separating the part of the shape that's common to more than one stroke. I'm not convinced that there's a well-defined way to do that. Perhaps define the "common region" as the circle centered on each skeleton intersection, tangent to the nearest edges? Then maybe some interpolation of stroke width across the gap?
我认为你不可能想出一个没有不正确情况的算法。有些汉字的某些部分是相同的,但笔画数并不相同。例如,从视觉角度(当然不是语言角度)来看,马在技术上还包括口。
我唯一的想法是将区域分成小区域并编写一个算法,尝试遵循笔画的设定顺序,但我无法想象这会很容易,并且根据字体,某些线条被扩展到它们不应该出现的区域。
还有一些字符由于其不寻常的布局而根本无法与算法很好地配合 - 只有遵循严格的笔画顺序规则才能获得正确的数字:示例包括凹和凸。
我不得不问——笔划计数是每个字符的基本信息——为什么你需要创建一个算法来计算它?进行字符识别并只需在自定义词典中查找该字符的笔画数不是更容易吗?
I don't think you can come up with an algorithm that doesn't have cases where it would be incorrect. There are parts of some characters that are the same but do not equate to the same stroke count. For example, 馬 technically also includes 口 from a visual standpoint (not lingusitical, of course).
The only idea I have is to sepearate the area into small regions and write an algorith that would attempt to follow the set order in which strokes are make, but I can't imagine that would be easy, and depending on the font, some lines are extended into regions they shouldn't be in.
There are also some characters that simply wouldn't work well with the algorithm due to their unusual layout - only by following the strict rules of the order of strokes can you get to the correct number: examples include 凹 and 凸.
I have to ask--stroke count is basic information for each character - why would you need to create an algorithm to count it? Wouldn't it be easier to do character recognition and just look up the stroke count for the character in a custom dictionary?
从蓝线和示例图像来看,我认为这三步方法可能适用于相当多的情况:
对于沿线的每个点,选择所有更接近的红色像素
到该点比最接近的白色像素。这将粗略地给出字符的笔划,但在两个笔划交叉的区域周围有凸起,并且您将排除笔划两端的一些像素。
要消除凸起,请隔离笔划的边缘像素,并计算霍夫变换 对于该边缘图像。从中选择两条最重要的行。这将为您提供(如果笔划足够直)沿着笔划边缘的两条线。消除笔划中在垂直方向上距离蓝线比这两条线更远的所有红色像素。现在(对于足够直的笔划)您所缺少的只是一些孤立的小像素块,这些像素块可能会在步骤 1 或步骤 2 中被消除,因此:
添加仅接触您的笔划的所有小的孤立的像素区域,并且没有字符的其他部分的笔划。如果您在步骤 2 中找到的线条太靠近蓝线,您还可以在步骤 1 和 2 之间执行此步骤。
From the blue line and the sample image I think this three step approach might work for quite a few cases:
For each point along the line, select all red pixels that are closer
to that point than the closest white pixel. This will roughly give you the stroke of the character, but with bulges around area's where two strokes cross, and you will exclude some pixels at both ends of the stroke.
To eliminate the bulges, isolate the edge pixels of the stroke, and compute the hough transform for that edge-image. Select the two most significant lines from that. This will give you (if the stroke is sufficiently straigh) two lines along the edges of the stroke. Eliminate all red pixels from your stroke that are further away from the blue line in a perpendicular direction than these two lines. Now (for a sufficiently straight stroke) all you are missing will be some small isolated lumps of pixels that hapened to be eliminated either in step 1 or step 2 so:
Add all small isolated regions of pixels that touch just your stroke, and no other part of the character to the stroke. If the lines you find in step 2 are too close to the blue line you could also perform this step between steps 1 and 2.
我认为最简单的可行方法是:
一次完成此操作后,您就可以制定更复杂的策略来选择良好的、依赖于细分市场的 T。
I think the simplest possible thing that can work is to:
Once you get this done, you can then work on more sophisticated strategies to select a good, segment dependent T.