是什么导致了 python 中 map.pool 的使用被挂起?
我正在运行一个命令行程序,并通过管道输入文本作为参数:
somecommand.exe < someparameters_tin.txt
它运行一段时间(通常是一小时到几个小时),然后将结果写入多个文本文件中。我正在尝试编写一个脚本来同时启动其中几个,使用多核机器上的所有核心。在其他操作系统上,我会分叉,但这在 Windows 的许多脚本语言中都没有实现。 Python 的多处理看起来可能会成功,所以我想尝试一下,尽管我根本不了解 python。我希望有人能告诉我我做错了什么。
我编写了一个脚本(如下),我指向一个目录,如果找到可执行文件和输入文件,并使用 pool.map 和 n 池以及使用 call 的函数启动它们。我看到的是,最初(启动第一组 n 个进程)似乎很好,100% 使用 n 个核心。但随后我发现进程处于空闲状态,没有使用或仅使用了百分之几的 CPU。那里总是有 n 个进程,但它们没有做太多事情。当他们去写入输出数据文件时,似乎会发生这种情况,一旦启动,一切都会陷入困境,总体核心利用率范围从几个百分点到偶尔达到 50-60% 的峰值,但永远不会接近 100%。
如果我可以附加它(编辑:我不能,至少现在),这是进程的运行时间图。较低的曲线是当我打开 n 个命令提示符并手动保持 n 个进程同时运行时,轻松地将计算机保持在 100% 附近。 (该线是有规律的,在 32 个不同的进程中改变参数,从接近 0 小时缓慢增加到 0.7 小时。)上面的线是该脚本的某些版本的结果 - 运行时间平均增加了约 0.2 小时,并且是更难以预测,就像我在底线中添加了 0.2 + 一个随机数。
这是情节的链接: 运行时图
编辑:现在我想我可以添加该图。 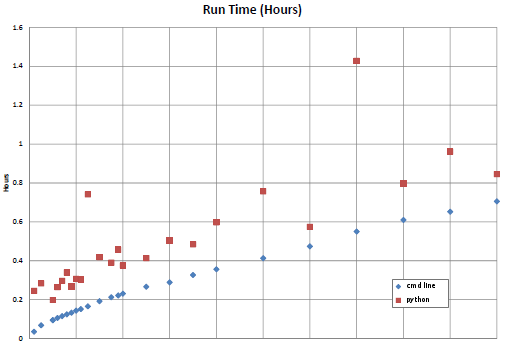
我做错了什么?
from multiprocessing import Pool, cpu_count, Lock
from subprocess import call
import glob, time, os, shlex, sys
import random
def launchCmd(s):
mypid = os.getpid()
try:
retcode = call(s, shell=True)
if retcode < 0:
print >>sys.stderr, "Child was terminated by signal", -retcode
else:
print >>sys.stderr, "Child returned", retcode
except OSError, e:
print >>sys.stderr, "Execution failed:", e
if __name__ == '__main__':
# ******************************************************************
# change this to the path you have the executable and input files in
mypath = 'E:\\foo\\test\\'
# ******************************************************************
startpath = os.getcwd()
os.chdir(mypath)
# find list of input files
flist = glob.glob('*_tin.txt')
elist = glob.glob('*.exe')
# this will not act as expected if there's more than one .exe file in that directory!
ex = elist[0] + ' < '
print
print 'START'
print 'Path: ', mypath
print 'Using the executable: ', ex
nin = len(flist)
print 'Found ',nin,' input files.'
print '-----'
clist = [ex + s for s in flist]
cores = cpu_count()
print 'CPU count ', cores
print '-----'
# ******************************************************
# change this to the number of processes you want to run
nproc = cores -1
# ******************************************************
pool = Pool(processes=nproc, maxtasksperchild=1) # start nproc worker processes
# mychunk = int(nin/nproc) # this didn't help
# list.reverse(clist) # neither did this, or randomizing the list
pool.map(launchCmd, clist) # launch processes
os.chdir(startpath) # return to original working directory
print 'Done'
I have a command line program I'm running and I pipe in text as arguments:
somecommand.exe < someparameters_tin.txt
It runs for a while (typically a good fraction of an hour to several hours) and then writes results in a number of text files. I'm trying to write a script to launch several of these simultaneously, using all the cores on a many core machine. On other OSs I'd fork, but that's not implemented in many scripting languages for Windows. Python's multiprocessing looks like it might do the trick so I thought I'd give it a try, although I don't know python at all. I'm hoping someone can tell me what I'm doing wrong.
I wrote a script (below) which I point to a directory, if finds the executable and input files, and launches them using pool.map and a pool of n, and a function using call. What I see is that initially (with the first set of n processes launched) it seems fine, using n cores 100%. But then I see the processes go idle, using no or only a few percent of their CPUs. There are always n processes there, but they aren't doing much. It appears to happen when they go to write the output data files, and once it starts everything bogs down, and overall core utilization ranges from a few percent to occasional peaks of 50-60%, but never gets near 100%.
If I can attach it (edit: I can't, at least for now) here's a plot of run times for the processes. The lower curve was when I opened n command prompts and manually kept n processes going at a time, easily keeping the computer near 100%. (The line is regular, slowly increasing from near 0 to 0.7 hours across 32 different processes varying a parameter.) The upper line is the result of some version of this script -- the runs times are inflated by about 0.2 hours on average and are much less predictable, like I'd taken the bottom line and added 0.2 + a random number.
Here's a link to the plot:
Run time plot
Edit: and now I think I can add the plot.
What am I doing wrong?
from multiprocessing import Pool, cpu_count, Lock
from subprocess import call
import glob, time, os, shlex, sys
import random
def launchCmd(s):
mypid = os.getpid()
try:
retcode = call(s, shell=True)
if retcode < 0:
print >>sys.stderr, "Child was terminated by signal", -retcode
else:
print >>sys.stderr, "Child returned", retcode
except OSError, e:
print >>sys.stderr, "Execution failed:", e
if __name__ == '__main__':
# ******************************************************************
# change this to the path you have the executable and input files in
mypath = 'E:\\foo\\test\\'
# ******************************************************************
startpath = os.getcwd()
os.chdir(mypath)
# find list of input files
flist = glob.glob('*_tin.txt')
elist = glob.glob('*.exe')
# this will not act as expected if there's more than one .exe file in that directory!
ex = elist[0] + ' < '
print
print 'START'
print 'Path: ', mypath
print 'Using the executable: ', ex
nin = len(flist)
print 'Found ',nin,' input files.'
print '-----'
clist = [ex + s for s in flist]
cores = cpu_count()
print 'CPU count ', cores
print '-----'
# ******************************************************
# change this to the number of processes you want to run
nproc = cores -1
# ******************************************************
pool = Pool(processes=nproc, maxtasksperchild=1) # start nproc worker processes
# mychunk = int(nin/nproc) # this didn't help
# list.reverse(clist) # neither did this, or randomizing the list
pool.map(launchCmd, clist) # launch processes
os.chdir(startpath) # return to original working directory
print 'Done'
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!








{kind=link}
发布评论
评论(2)
这些进程是否有可能尝试写入公共文件?在 Linux 下,它可能会正常工作,破坏数据,但不会减慢速度;但在 Windows 下,一个进程可能会获取该文件,而所有其他进程可能会挂起,等待该文件变得可用。
如果您用一些使用 CPU 但不写入磁盘的愚蠢任务替换实际任务列表,问题是否会重现?例如,您可能有计算某个大文件的 md5sum 的任务;一旦文件被缓存,其他任务将是纯 CPU 的,然后是单行输出到 stdout。或者计算一些昂贵的函数之类的。
Is there any chance that the processes are trying to write to a common file? Under Linux it would probably just work, clobbering data but not slowing down; but under Windows one process might get the file and all the other processes might hang waiting for the file to become available.
If you replace your actual task list with some silly tasks that use CPU but don't write to disk, does the problem reproduce? For example, you could have tasks that compute the md5sum of some large file; once the file was cached the other tasks would be pure CPU and then a single line output to stdout. Or compute some expensive function or something.
我认为我知道这一点。当您调用
map时,它会将任务列表分成每个进程的“块”。默认情况下,它使用足够大的块,以便可以向每个进程发送一个。这是基于所有任务需要大约相同的时间来完成的假设。根据您的情况,完成这些任务可能需要不同的时间。因此,一些工作人员先于其他工作人员完成工作,而这些 CPU 则处于闲置状态。如果是这样的话,那么这应该按预期工作:
效率较低,但这应该意味着每个工作人员在完成时会获得更多任务,直到它们全部完成。
I think I know this. When you call
map, it breaks the list of tasks into 'chunks' for each process. By default, it uses chunks large enough that it can send one to each process. This works on the assumption that all the tasks take about the same length of time to complete.In your situation, presumably the tasks can take very different amounts of time to complete. So some workers finish before others, and those CPUs sit idle. If that's the case, then this should work as expected:
Less efficient, but it should mean that each worker gets more tasks as it finishes until they're all complete.