matlab中的K均值算法
不使用kmeans(X,k)语法,如何在Matlab中实现K-means算法?
实际上问题不在于算法的实现。请看下图: 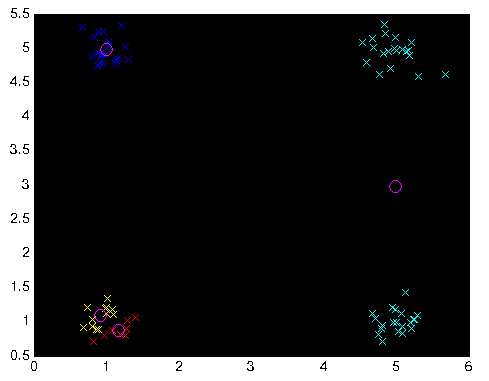
我实现了大多数网站提供的算法,例如 http://en.wikipedia.org/wiki/Kmeans
1. Give initial values to m1 .. mk
2. Assignment with closest mean
3. Update
我设置了 X 的 4 个观测值(200 个样本),我已经知道这 4 个观测值是从1 个簇。 因此,根据算法,上述显示图像的聚类是可以解释的,但事实并非如此。我认为4个初始值不应该随机选择。
我还运行一些其他源代码,例如 http://people.revoledu.com /kardi/tutorial/kMean/matlab_kMeans.htm。推导出相同的结果。您可以从 http://www.4shared.com/get/IfwUEUBD/ 下载我的观察结果Observation.html 并亲自查看结果。
How can we implement K-means algorithm in Matlab without using kmeans(X,k) syntax?
Actually the problem is not implementing the algorithm. please see the the image below:
I implemented the algorithm offered from most of sites e.g. http://en.wikipedia.org/wiki/Kmeans
1. Give initial values to m1 .. mk
2. Assignment with closest mean
3. Update
I set 4 observations of X (200 samples) which I knew already that these 4 observations are from 1 cluster.
hence, according to algorithm, the above clustering of shown image is explainable while that's not true. I think 4 initial values shouldn't select randomly.
I also run some other source code such as http://people.revoledu.com/kardi/tutorial/kMean/matlab_kMeans.htm. the same result deduced. you can download my observations from http://www.4shared.com/get/IfwUEUBD/Observation.html and see by yourself the result.
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!





发布评论
评论(2)
如果您想实现自己的 k-means 或(无论出于何种原因)不想使用 MATLAB k-means 语法,那么有几种方法:
阅读论文:“高效的 k-Means 聚类算法:
分析和实现”,还可以阅读一些其他资源,然后编写自己的代码。
搜索互联网,直到找到其他一些免费实现,以便您可以在代码中使用它。
您可能希望看到以下链接:
http://people.revoledu.com/kardi/tutorial/kMean/index.html
if you want to implement your own k-means or (for whatever reason) dont want to use the MATLAB k-means syntax then there are a couple of ways:
read the paper: "An Efficient k-Means Clustering Algorithm:
Analysis and Implementation", also read some other resources and then write your own code.
search the internet until you find some other free implementation so that you can use it in your code.
you may like to see the following link:
http://people.revoledu.com/kardi/tutorial/kMean/index.html
“不使用 kmeans(X,k) 语法”是指不提前指定 k(簇数)吗?这是不可能的,因为该算法依赖于提前了解簇的数量。如果您确实想在事先不知道集群数量的情况下执行集群,我会研究另一种算法,例如 DBSCAN算法。
如果您想要一个已经通过可用源代码实现的 K 均值算法,请查看 VLFeat 以获得可靠的实现。不过语法正是 kmeans(X,k) 。
By "without using kmeans(X,k) syntax" do you mean without specifying k, the number of clusters, in advance? This isn't possible as the algorithm relies on knowing the number of clusters ahead of time. If you really want to perform clustering without knowing the number of clusters in advance I'd look into another algorithm such as the DBSCAN algorithm.
If you want a K-means algorithm already implemented with source code available, check out VLFeat for a solid implementation. The syntax is exactly kmeans(X,k) though.