有多少个“实体”?都在这个层次结构之下。嵌套集/邻接(英格兰境内有多少个 POI)
开发语言和数据库:PHP/MySQL
我有一个表geo_places,其中包含大约 800 万个地理位置。
这些地方都是分层的,我使用
- parent_id(邻接)、
- lft/rgt(嵌套集)
- 和ancestry(枚举)。
现在,我有一个名为 entities 的“兴趣点”表,它被分配给一个地理位置,并且我针对每个实体记录:
lft中位置的值code>geo_places- 和地理位置的实际
ID。
现在我需要一种方法来提供一个目录列表,其中包含某个位置下所有位置的有效计数(但无论如何我都会缓存它)。
例如,如果我选择欧洲,那么我应该看到所有具有欧洲 Parent_id 的地方,以及其下方的实体数量。请记住,一个地方不会直接分配给欧洲,但可能会分配给意大利的一个小村庄(这是欧洲的孩子)。
您知道它是欧洲的孩子,因为:
- 意大利小村庄的
lft值介于lft和rgt值之间位置 - 或者因为祖先映射到该地方。
例如,欧洲的祖先路径为 /1,ID 为 5。(1 表示“世界”)。然后意大利的小村庄会有 /1/5/234/28924/124128
其中 1 = 世界 5 = 欧洲 234 = 意大利 28924 = 贝加莫等等...
无论如何,这就是我的方式已经构建了数据集,并且我已经使用了分层结构的混合,以便使我的查询更加高效(对于那些想知道为什么我支持嵌套集、邻接集的人来说)并枚举..这是因为我通过这种方式获得了所有结构中最好的)。
这是我正在尝试做的一个例子。 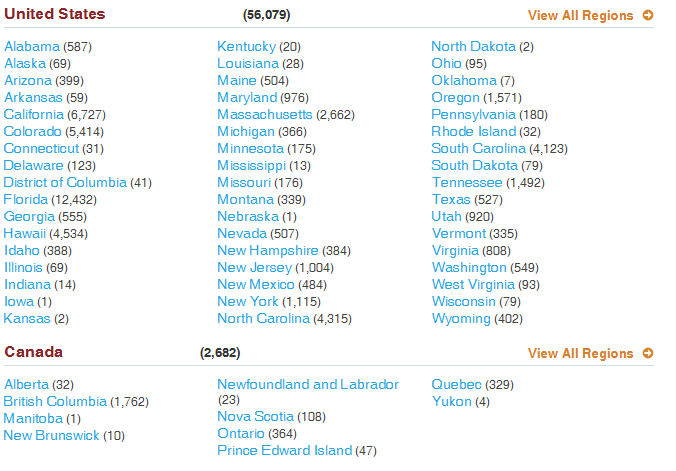
我很灵活,可以根据需要更改管理位置的方式。但是,这也是一个多租户应用程序,因此我想尝试避免保存针对 geo_places 的计数(如果可以避免的话)。
简单地说: 选择一个位置...然后显示所有已分配给该位置或该位置的子位置的兴趣点的位置。
有什么建议吗?
Development language and DB: PHP/MySQL
I have a table geo_places with something like 8 million geographical locations.
These places are all hierarchical, and I use
- parent_id (adjacency),
- lft/rgt (nested set)
- and ancestry (enumerated).
Now, I have "points of interest" table called entities which are assigned to a geographical location, and I record against each entity the:
lftvalue of the location in thegeo_places- and the actual
IDof the geographical location.
Now I need a way to provide a directory listing with count EFIFICNETLY (but I will be caching this anyway), of all the places which are beneath a location.
For example, if I take Europe, then I should see all places which have a parent_id of Europe, and then also the amount of entities below it. Keeping in mind that a place does not get assigned directly to Europe, but might be assigned to a small village in Italy (which is a child of Europe).
You know that it is a child of Europe either because:
- the
lftvalue of the small village in Italy is between thelftandrgtvalue of the location - Or because the ancestry maps to the place.
For example, Europe would have an ancestry path of /1 and an ID of 5. (The 1 would signify the "World"). And then the small village in Italty would have /1/5/234/28924/124128
where 1 = World 5 = Europe 234 = Italy 28924 = Bergamo etc etc...
Anyway, this is how I have structured the dataset, and I have already been using a mixture of the hierarchical structures in order to make my queries a lot more efficient (for those of you wondering why am I am supporting nested set, adjacency and enumerated.. it's because I get the best of all structures this way).
This is an example of what I am trying to do.
I am flexible and can change how I manage locations if neccessary. However, this is also a multi tenant application, so I would like to try and avoid saving counts against the geo_places if it can be avoided.
So simply put:
Pick a location... then show all locations which have points of interest assigned either to that location, or a child of that location.
Any recommendations?
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!



发布评论
评论(1)
这是一种解决方案:
您可以将
1替换为您想要查找其后代的位置。使用
entities中的 10 万个实体和geo_places中的 800 万行进行了测试。关于
lft和rgt以及woeid的索引。This is one solution:
You would subtitute
1for the place that you want to find the descendant of.Tested with 100k entities in
entitiesand 8million rows ingeo_places.Index on
lftandrgtandwoeid.