是否有一个 python 模块可以在网络上抓取图像、标题和任何链接的描述?
我正在寻找什么,应该给我这样的东西 -> 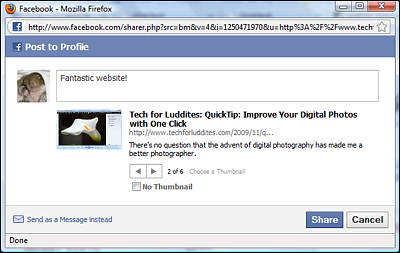
What I'm looking for, should give me something like this ->
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!
我正在寻找什么,应该给我这样的东西 ->
What I'm looking for, should give me something like this ->
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!
接受 或继续使用网站,即表示您同意使用 Cookies 和您的相关数据。




发布评论
评论(4)
有许多可用的 API 可以完成您的任务(更准确地说是您在问题中描述的任务,而不是图像:))。我个人使用 diffbot,这是我在阅读 这个。但请注意,由于网页的性质,这种“内容”提取并不总是成功。相反,它依赖于启发法和培训,因此可能不足以满足您的特定目的......
There are many APIs available that can accomplish your task (more precisely the task you describe on your question, not the image :) ). I personally use diffbot, which I discovered after reading this. Beware though, for this kind of "content" extraction does not always end with success, because of the nature of web pages. Instead, it relies on heuristics and training and thus may not suffice for your specific purposes...
如果您想要页面的完整屏幕截图,则类似于 https://stackoverflow.com/questions/1041371/alexa- api 可以帮助你吗?
否则,如果您只想从页面中获取一些关键图像..
您可以使用 mechanize 来帮助您。当您连接到网页时,您可以使用以下方式搜索页面上的所有链接:
其中 br 是您的浏览器对象。
您可以在此处查看示例:
下载所有链接(相关文档)在使用 Python 的网页上,
如果您打印 dir(link),它将显示各种属性,例如 link.text 和 link.url。此外,您可以导入 urlparse.urlsplit 并在 url 上使用它。您可以将浏览器定向到 URL 并抓取图像,如上例所示。
If you're wanting an entire screenshot of the page then something like https://stackoverflow.com/questions/1041371/alexa-api may help you?
Otherwise if you're just wanting to get a few key images from the page..
you could use mechanize to assit you. When you connect to a webpage you can search through all the links on the page using:
where br is your browser object.
You can see an example here:
Download all the links(related documents) on a webpage using Python
if you print dir(link) it will show you various properties such as link.text and link.url. furthermore you can import urlparse.urlsplit and use it on the url. You can direct the browser towards the URL and scrape the images as shown in the above example.
您确实应该使用搜索引擎对页面及其中的图像进行解释。
您可以使用 bing API 上的 python 包装器 或 xGoogle 库。
请注意,xGoogle 库会像浏览器一样冒充 google,并且可能不会被认可使用 Google 数据的方式。
You should really use a search engines interpretation of the page and the images in it.
You could use, the python wrapper on the bing API, or the xGoogle library.
Beware the xGoogle library fakes to google as if a browser and may not be endorsed way to consume Google's data.
这一个应该有帮助:http://palewi.re/posts/2008/04/20/python-recipe-grab-a-page-scrape-a-table-download-a-file/
向您学习如何抓取内容和图像并存储它。
This one should help: http://palewi.re/posts/2008/04/20/python-recipe-grab-a-page-scrape-a-table-download-a-file/
Learns you how to scrape content and images and store it.