需要有关如何从 .docx/.doc 文件中提取数据然后将数据提取到 SQL Server 中的建议
我想为我的项目开发一个应用程序,它将加载往年的考试/练习卷(word文件),相应地检测各个部分,提取该部分中的问题和图像,然后将问题和图像存储到数据库。 (试卷预览位于这篇文章的底部)
所以我需要一些关于如何从Word文件中提取数据,然后将它们插入数据库的建议。目前我有一些方法可以做到这一点,但是我不知道当文件包含带有背景图像的文本框时如何实现它们。问题必须与图像联系起来。
方法一(利用ms office interop)
- 加载word文件->提取图像, 保存到文件夹 ->提取文本, 另存为.txt ->从 .txt 中提取文本然后存储在数据库中
问题:
- 如何检测该部分和问题?
- 如何将图像链接到问题?
从Word文件中提取文本(工作):
private object missing = Type.Missing;
private object sFilename = @"C:\temp\questionpaper.docx";
private object sFilename2 = @"C:\temp\temp.txt";
private object readOnly = true;
object fileFormat = Word.WdSaveFormat.wdFormatText;
private void button1_Click(object sender, EventArgs e)
{
Word.Application wWordApp = new Word.Application();
wWordApp.DisplayAlerts = Word.WdAlertLevel.wdAlertsNone;
Word.Document dFile = wWordApp.Documents.Open(ref sFilename,
ref missing, ref readOnly, ref missing, ref missing,
ref missing, ref missing, ref missing, ref missing,
ref missing, ref missing, ref missing, ref missing,
ref missing, ref missing, ref missing);
dFile.SaveAs(ref sFilename2, ref fileFormat, ref missing, ref missing,
ref missing, ref missing, ref missing, ref missing,ref missing,
ref missing,ref missing,ref missing,ref missing,ref missing,
ref missing,ref missing);
dFile.Close(ref missing, ref missing, ref missing);
}
从Word文件中提取图像(不适用于文本框中的图像):
private Word.Application wWordApp;
private int m_i;
private object missing = Type.Missing;
private object filename = @"C:\temp\questionpaper.docx";
private object readOnly = true;
private void CopyFromClipbordInlineShape(String imageIndex)
{
Word.InlineShape inlineShape = wWordApp.ActiveDocument.InlineShapes[m_i];
inlineShape.Select();
wWordApp.Selection.Copy();
Computer computer = new Computer();
if (computer.Clipboard.GetDataObject() != null)
{
System.Windows.Forms.IDataObject data = computer.Clipboard.GetDataObject();
if (data.GetDataPresent(System.Windows.Forms.DataFormats.Bitmap))
{
Image image = (Image)data.GetData(System.Windows.Forms.DataFormats.Bitmap, true);
image.Save("C:\\temp\\DoCremoveImage" + imageIndex + ".png", System.Drawing.Imaging.ImageFormat.Png);
}
}
}
private void button1_Click(object sender, EventArgs e)
{
wWordApp = new Word.Application();
wWordApp.Documents.Open(ref filename,
ref missing, ref readOnly, ref missing, ref missing,
ref missing, ref missing, ref missing, ref missing,
ref missing, ref missing, ref missing, ref missing,
ref missing, ref missing, ref missing);
try
{
for (int i = 1; i <= wWordApp.ActiveDocument.InlineShapes.Count; i++)
{
m_i = i;
CopyFromClipbordInlineShape(Convert.ToString(i));
}
}
finally
{
object save = false;
wWordApp.Quit(ref save, ref missing, ref missing);
wWordApp = null;
}
}
方法二
- 解压Word 文件 (.docx) ->复制 media(image) 文件夹,存储在某处 ->解析XML文件->将文本存储在数据库中
任何建议/帮助将不胜感激:D
单词文件预览: 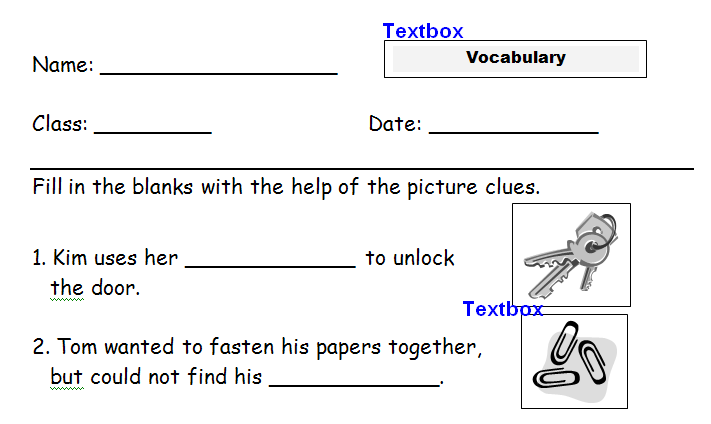 (备份链接:https://i.sstatic.net/YF1Ap.png)
(备份链接:https://i.sstatic.net/YF1Ap.png)
I'm suppose to develop an application for my project, it will load past-year examination / exercises paper (word file), detect the sections accordingly, extract the questions and images in that section, and then store the questions and images into the database. (Preview of the question paper is at the bottom of this post)
So I need some suggestions on how to extract data from a word file, then inserting them into a database. Currently I have a few methods to do so, however I have no idea how I could implement them when the file contains textboxes with background image. The question has to link with the image.
Method One (Make use of ms office interop)
- Load the word file -> Extract image,
save into a folder -> Extract text,
save as .txt -> Extract text from .txt then store in db
Questions:
- How do I detect the section and question?
- How do I link the image to the question?
Extract text from word file (Working):
private object missing = Type.Missing;
private object sFilename = @"C:\temp\questionpaper.docx";
private object sFilename2 = @"C:\temp\temp.txt";
private object readOnly = true;
object fileFormat = Word.WdSaveFormat.wdFormatText;
private void button1_Click(object sender, EventArgs e)
{
Word.Application wWordApp = new Word.Application();
wWordApp.DisplayAlerts = Word.WdAlertLevel.wdAlertsNone;
Word.Document dFile = wWordApp.Documents.Open(ref sFilename,
ref missing, ref readOnly, ref missing, ref missing,
ref missing, ref missing, ref missing, ref missing,
ref missing, ref missing, ref missing, ref missing,
ref missing, ref missing, ref missing);
dFile.SaveAs(ref sFilename2, ref fileFormat, ref missing, ref missing,
ref missing, ref missing, ref missing, ref missing,ref missing,
ref missing,ref missing,ref missing,ref missing,ref missing,
ref missing,ref missing);
dFile.Close(ref missing, ref missing, ref missing);
}
Extract image from word file (doesn't work on image inside textbox):
private Word.Application wWordApp;
private int m_i;
private object missing = Type.Missing;
private object filename = @"C:\temp\questionpaper.docx";
private object readOnly = true;
private void CopyFromClipbordInlineShape(String imageIndex)
{
Word.InlineShape inlineShape = wWordApp.ActiveDocument.InlineShapes[m_i];
inlineShape.Select();
wWordApp.Selection.Copy();
Computer computer = new Computer();
if (computer.Clipboard.GetDataObject() != null)
{
System.Windows.Forms.IDataObject data = computer.Clipboard.GetDataObject();
if (data.GetDataPresent(System.Windows.Forms.DataFormats.Bitmap))
{
Image image = (Image)data.GetData(System.Windows.Forms.DataFormats.Bitmap, true);
image.Save("C:\\temp\\DoCremoveImage" + imageIndex + ".png", System.Drawing.Imaging.ImageFormat.Png);
}
}
}
private void button1_Click(object sender, EventArgs e)
{
wWordApp = new Word.Application();
wWordApp.Documents.Open(ref filename,
ref missing, ref readOnly, ref missing, ref missing,
ref missing, ref missing, ref missing, ref missing,
ref missing, ref missing, ref missing, ref missing,
ref missing, ref missing, ref missing);
try
{
for (int i = 1; i <= wWordApp.ActiveDocument.InlineShapes.Count; i++)
{
m_i = i;
CopyFromClipbordInlineShape(Convert.ToString(i));
}
}
finally
{
object save = false;
wWordApp.Quit(ref save, ref missing, ref missing);
wWordApp = null;
}
}
Method Two
- Unzip the word file (.docx) -> Copy the media(image) folder, store somewhere -> Parse the XML file -> Store the text in db
Any suggestion/help would be greatly appreciated :D
Preview of the word file:
(backup link: https://i.sstatic.net/YF1Ap.png)
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!




发布评论
评论(1)
答案是选择#3 - OpenXML SDK。首先让我解释一下为什么您不想要上面列出的选择。
在服务器上运行 Office 不是一个好主意。微软明确表示不要这样做。它速度很慢,而且您会遇到“问题”,抛出异常或无法找到内容。
解析 XML 文件可以工作,但查找图像等所在位置的每种可能情况的 XPath 都会累加。您可能必须迭代位于每个部分末尾的部分,然后处理单元格中、文本框中、定位、内联等的所有情况。
如果您使用 OpenXML SDK,您将拥有一个 LINQ 接口,其中然后,您可以使用后代并获取图像中的所有内容(或您需要的任何内容)。它还为您提供 SectPr 节点的部分,以便您可以轻松地迭代部分。
The answer is choice #3 - the OpenXML SDK. First let me explain why you don't want the choices listed above.
Running Office on the server is a bad idea. Microsoft specifically says don't do it. It's slow and you will hit "issues" where it throws exceptions or just fails to find things.
Parsing the XML file will work but the XPath to find every possible case where the images, etc. are located adds up. You would probably have to iterate on sections, which come at the end of each section, then handle all cases of in a cell, in a textbox, positioned, inline, etc.
If you go with the OpenXML SDK you have a LINQ interface where you can then use the Descendents and get everything that is an image (or whatever you need). It also gives you sections by the SectPr node so you can easily iterate over sections.