Python:Matplotlib - 多个数据集的概率图
我有几个数据集(分布)如下:
set1 = [1,2,3,4,5]
set2 = [3,4,5,6,7]
set3 = [1,3,4,5,8]
如何使用上面的数据集绘制散点图,其中 y 轴是概率(即集合中分布的百分位数: 0%-100% )和 x -axis 是数据集名称吗? 在 JMP 中,它称为“分位数图”。
像附图一样的东西: 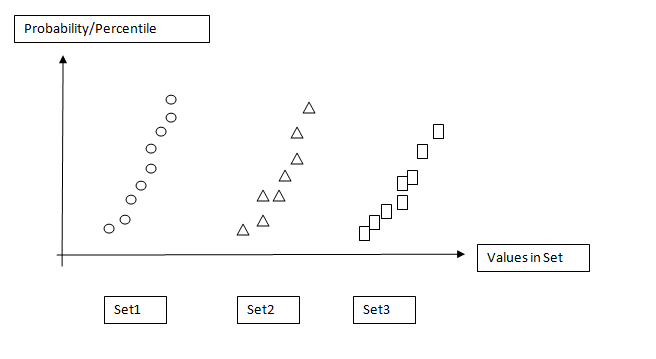
请赐教。谢谢。
[编辑]
我的数据采用 csv 格式,如下所示:
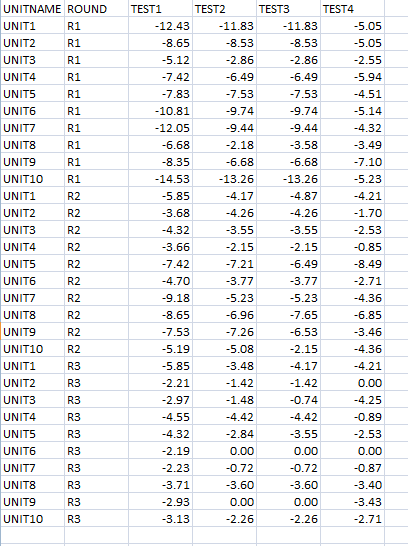
使用 JMP 分析工具,我可以绘制概率分布图(QQ-plot/正态分位数图,如下图所示):
我相信 Joe Kington 几乎已经解决了我的问题,但是我想知道如何将原始 csv 数据处理成概率或百分位数数组。
我这样做是为了在 Python 中自动进行一些统计分析,而不是依赖 JMP 进行绘图。
I have several data sets (distribution) as follows:
set1 = [1,2,3,4,5]
set2 = [3,4,5,6,7]
set3 = [1,3,4,5,8]
How do I plot a scatter plot with the data sets above with the y-axis being the probability (i.e. the percentile of the distribution in set: 0%-100% ) and the x-axis being the data set names?
in JMP, it is called 'Quantile Plot'.
Something like image attached:
Please educate. Thanks.
[EDIT]
My data is in csv as such:
Using JMP analysis tool, I'm able to plot the probability distribution plot (QQ-plot/Normal Quantile Plot as figure far below):
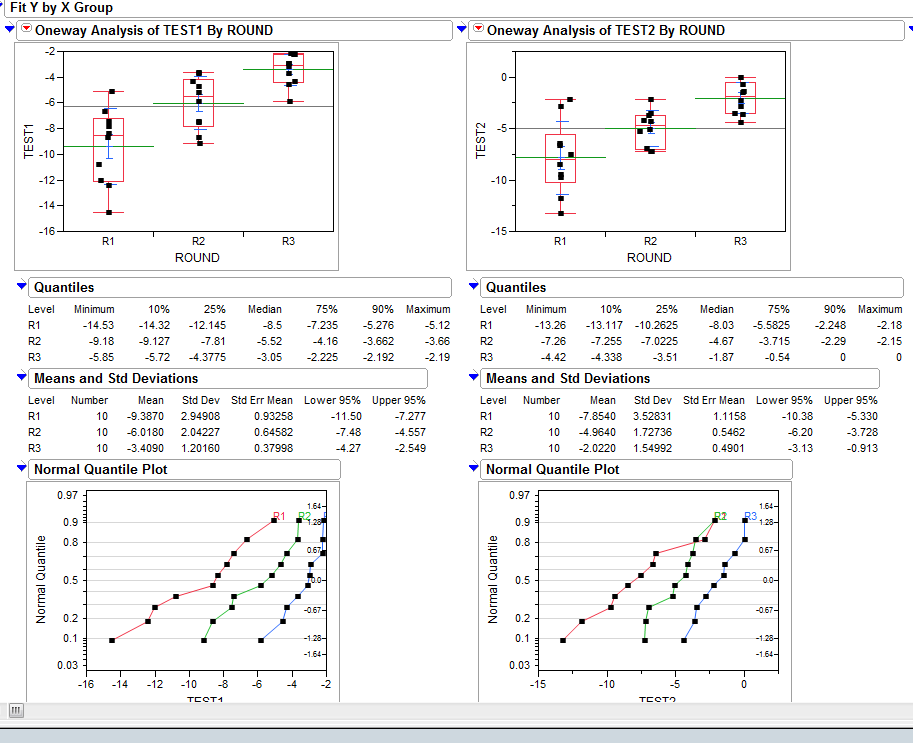
I believe Joe Kington almost has my problem solved but, I'm wondering how to process the raw csv data into arrays of probalility or percentiles.
I doing this to automate some stats analysis in Python rather than depending on JMP for plotting.
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!





发布评论
评论(1)
我不完全清楚你想要什么,所以我会猜测,在这里......
你希望“概率/百分位数”值成为累积直方图?
那么对于一个单一的情节,你会有这样的东西吗? (如上面所示,用标记绘制它,而不是更传统的步骤图...)
如果这大致就是您想要的单个绘图,则有多种方法可以在一个图形上绘制多个绘图。最简单的方法就是使用子图。
在这里,我们将生成一些数据集,并将它们绘制在具有不同符号的不同子图上...
如果我们如果希望它看起来像一个连续的图,我们可以将子图挤压在一起并关闭一些边界。只需在调用
plt.show()之前添加以下内容希望有帮助无论如何,有一点!
编辑:如果您想要百分位值,而不是累积直方图(我真的不应该使用 100 作为样本大小!),这很容易做到。
只需执行以下操作(使用
numpy.percentile而不是手动标准化事物):I'm not entirely clear on what you want, so I'm going to guess, here...
You want the "Probability/Percentile" values to be a cumulative histogram?
So for a single plot, you'd have something like this? (Plotting it with markers as you've shown above, instead of the more traditional step plot...)
If that's roughly what you want for a single plot, there are multiple ways of making multiple plots on a figure. The easiest is just to use subplots.
Here, we'll generate some datasets and plot them on different subplots with different symbols...
If we want this to look like one continuous plot, we can just squeeze the subplots together and turn off some of the boundaries. Just add the following in before calling
plt.show()Hopefully that helps a bit, at any rate!
Edit: If you want percentile values, instead a cumulative histogram (I really shouldn't have used 100 as the sample size!), it's easy to do.
Just do something like this (using
numpy.percentileinstead of normalizing things by hand):