以下替代方案永远无法实现:2
我正在尝试创建一个非常简单的语法来学习使用 ANTLR,但我收到以下消息:
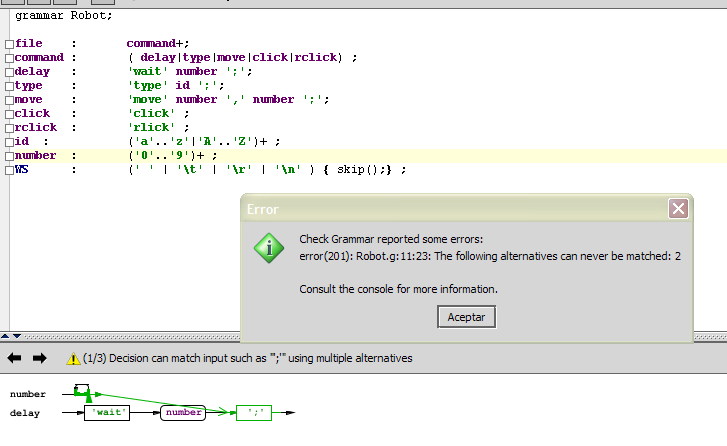
“永远无法达到以下替代方案:2”
这是我的语法尝试:
grammar Robot;
file : command+;
command : ( delay|type|move|click|rclick) ;
delay : 'wait' number ';';
type : 'type' id ';';
move : 'move' number ',' number ';';
click : 'click' ;
rclick : 'rlick' ;
id : ('a'..'z'|'A'..'Z')+ ;
number : ('0'..'9')+ ;
WS : (' ' | '\t' | '\r' | '\n' ) { skip();} ;
我正在使用IDEA 的 ANTLRWorks 插件:
I'm trying to create a very simple grammar to learn to use ANTLR but I get the following message:
"The following alternatives can never be reached: 2"
This is my grammar attempt:
grammar Robot;
file : command+;
command : ( delay|type|move|click|rclick) ;
delay : 'wait' number ';';
type : 'type' id ';';
move : 'move' number ',' number ';';
click : 'click' ;
rclick : 'rlick' ;
id : ('a'..'z'|'A'..'Z')+ ;
number : ('0'..'9')+ ;
WS : (' ' | '\t' | '\r' | '\n' ) { skip();} ;
I'm using ANTLRWorks plugin for IDEA:
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!





发布评论
评论(1)
解析器规则内的
..(范围)与词法分析器规则内的含义不同。在词法分析器规则中,它意味着:“从 char X 到 char Y”,在解析器规则中,它匹配“从标记 M 到标记 N”。由于您将number设置为解析器规则,因此它不会执行您认为的操作(因此会收到一条模糊的错误消息)。解决方案:将
number改为词法分析器规则(因此,将其大写:Number):如您所见,我还制作了
id,相反,click和rclick词法分析器规则。如果您不确定解析器规则和词法分析器规则之间有什么区别,请说出来,我将对此答案添加解释。The
..(range) inside parser rules means something different than inside lexer rules. Inside lexer rules, it means: "from char X to char Y", and inside parser rule it matches "from token M to token N". And since you madenumbera parser rule, it does not do what you think it does (and are therefor receiving an obscure error message).The solution: make
numbera lexer rule instead (so, capitalize it:Number):And as you can see, I also made
id,clickandrclicklexer rules instead. If you're not sure what the difference is between parser- and lexer rules, please say so and I'll add an explanation to this answer.