我正在开发一个简单的博客/书签平台,并尝试添加 tags-explorer/drill-down 功能 delicious 允许用户过滤指定特定标签列表的帖子。
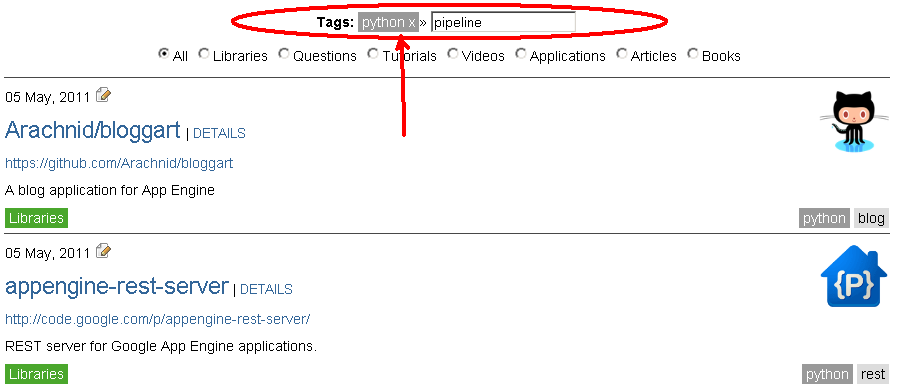
像这样的东西:
帖子在数据存储中使用此简化模型表示:
class Post(db.Model):
title = db.StringProperty(required = True)
link = db.LinkProperty(required = True)
description = db.StringProperty(required = True)
tags = db.ListProperty(str)
created = db.DateTimeProperty(required = True, auto_now_add = True)
帖子的标签存储在 ListProperty 并且,为了检索带有特定标签列表的帖子列表,Post 模型公开了以下静态方法:
@staticmethod
def get_posts(limit, offset, tags_filter = []):
posts = Post.all()
for tag in tags_filter:
if tag:
posts.filter('tags', tag)
return posts.fetch(limit = limit, offset = offset)
这很有效,尽管我没有过多强调它。
当我尝试向 get_posts 方法添加“排序”顺序以保持结果按 "-created" 日期排序时,问题就出现了:
@staticmethod
def get_posts(limit, offset, tags_filter = []):
posts = Post.all()
for tag in tags_filter:
if tag:
posts.filter('tags', tag)
posts.order("-created")
return posts.fetch(limit = limit, offset = offset)
排序顺序添加了一个索引每个标签都要过滤,导致可怕的索引爆炸问题。
最后一件事让事情变得更加复杂,get_posts 方法应该提供某种分页机制。
您知道解决这个问题的策略/想法/解决方法/技巧吗?
I'm developing a simple Blogging/Bookmarking platform and I'm trying to add a tags-explorer/drill-down feature a là delicious to allow users to filter the posts specifying a list of specific tags.
Something like this:
Posts are represented in the datastore with this simplified model:
class Post(db.Model):
title = db.StringProperty(required = True)
link = db.LinkProperty(required = True)
description = db.StringProperty(required = True)
tags = db.ListProperty(str)
created = db.DateTimeProperty(required = True, auto_now_add = True)
Post's tags are stored in a ListProperty and, in order to retrieve the list of posts tagged with a specific list of tags, the Post model exposes the following static method:
@staticmethod
def get_posts(limit, offset, tags_filter = []):
posts = Post.all()
for tag in tags_filter:
if tag:
posts.filter('tags', tag)
return posts.fetch(limit = limit, offset = offset)
This works well, although I've not stressed it too much.
The problem raises when I try to add a "sorting" order to the get_posts method to keep the result ordered by "-created" date:
@staticmethod
def get_posts(limit, offset, tags_filter = []):
posts = Post.all()
for tag in tags_filter:
if tag:
posts.filter('tags', tag)
posts.order("-created")
return posts.fetch(limit = limit, offset = offset)
The sorting order adds an index for each tag to filter, leading to the dreaded exploding indexes problem.
One last thing that makes this thing more complicated is that the get_posts method should provide some pagination mechanism.
Do you know any Strategy/Idea/Workaround/Hack to solve this problem?





发布评论
评论(4)
如果你把关系颠倒了怎么办?您将拥有一个带有帖子列表的标签实体,而不是带有标签列表的帖子。
要搜索标签,您可以执行
tags = Tag.all().filter('tag IN', ['python','blog','async'])这有望为您提供 3 或更多标签实体,每个实体都有一个使用该标签的帖子列表。然后,您可以执行
post_union = set(tags[0].posts).intersection(tags[1].posts, Tags[2].posts)来查找包含所有标签的帖子集。然后你可以获取这些帖子并按创建顺序排列它们(我认为)。
Posts.all().filter('__key__ IN', post_union).order("-created")注意:这段代码是我想不到的,我不记得你是否可以这样操作集合。
编辑:@Yasser 指出你只能对 << 进行 IN 查询。 30 项。
相反,您可以让每个帖子的键名称以创建时间开头。然后,您可以对通过第一个查询检索到的键进行排序,然后只需执行
Posts.get(sorted_posts)即可。不知道这将如何扩展到具有数百万个帖子和/或标签的系统。
Edit2:我的意思是集合交集,而不是并集。
What if you inverted the relationship? Instead of a post with a list of tags you would have a tag entity with a list of posts.
To search for tags you would do
tags = Tag.all().filter('tag IN', ['python','blog','async'])This would give you hopefully 3 or more Tag entities, each with a list of posts that are using that tag. You could then do
post_union = set(tags[0].posts).intersection(tags[1].posts, tags[2].posts)to find the set of posts that have all tags.Then you could fetch those posts and order them by created (I think).
Posts.all().filter('__key__ IN', post_union).order("-created")Note: This code is off the top of my head, I can't remember if you can manipulate sets like that.
Edit: @Yasser pointed out that you can only do IN queries for < 30 items.
Instead you could have the key name for each post start with the creation time. Then you could sort the keys you retrieved via the first query and just do
Posts.get(sorted_posts).Don't know how this would scale to a system with millions of posts and/or tags.
Edit2: I meant set intersection, not union.
这个问题听起来类似于:
正如 Robert Kluin 在上一篇中指出的,您也可以考虑使用类似于Google I/O 演示文稿中所述的“关系索引”模式< /a>.
根据您期望通过标签查询返回的页面数量,可以在内存中进行排序,也可以通过将日期字符串表示形式作为
Articlekey_name更新为 < code>StringListProperty 并在 Robert Kluin 和 Wooble 在
#appengineIRC 频道上发表评论。This question sounds similar to:
As pointed by Robert Kluin in the last one, you could also consider using a pattern similar to "Relation Index" as described in this Google I/O presentation.
Depending on how many Page you expect back by Tags query, sorting could either be made in memory or by making the date string representation part of
Articlekey_nameUpdated with
StringListPropertyand sorting notes after Robert Kluin and Wooble comments on#appengineIRC channel.一种解决方法可能是这样的:
使用 | 等分隔符对帖子的标签进行排序和连接。并在存储帖子时将它们存储为 StringProperty。当您收到 Tags_filter 时,您可以对它们进行排序和连接,以为帖子创建单个 StringProperty 过滤器。显然,这将是一个 AND 查询,而不是一个 OR 查询,但这就是您当前的代码似乎也在做的事情。
编辑:正如正确指出的那样,这只会匹配精确的标签列表而不是部分标签列表,这显然不是很有用。
编辑:如果您使用标签的布尔占位符(例如 b1、b2、b3 等)对 Post 模型进行建模,会怎么样。定义新标签时,您可以将其映射到下一个可用占位符,例如 blog=b1、python=b2、async=b3并将映射保存在单独的实体中。将标签分配给帖子后,您只需将其等效占位符值切换为 True 即可。
这样,当您收到 tag_filter 集时,您可以从地图构建查询,例如
可以为您提供带有标签
python和blog的所有帖子。One workaround could be this:
Sort and concatenate a post's tags with a delimiter like | and store them as a StringProperty when storing a post. When you receive the tags_filter, you can sort and concatenate them to create a single StringProperty filter for the posts. Obviously this would be an AND query and not an OR query but thats what your current code seems to be doing as well.
EDIT: as rightly pointed out, this would only match exact tag list not partial tag list, which is obviously not very useful.
EDIT: what if you model your Post model with boolean placeholders for tags e.g. b1, b2, b3 etc. When a new tag is defined, you can map it to the next available placeholder e.g. blog=b1, python=b2, async=b3 and keep the mapping in a separate entity. When a tag is assigned to a post, you just switch its equivalent placeholder value to True.
This way when you receive a tag_filter set, you can construct your query from the map e.g.
can give you all the posts which have tags
pythonandblog.因此,请使用可排序的日期字符串作为实体的主键:
...
现在,您甚至不必在查询中包含排序顺序,尽管按键显式排序不会有什么坏处。
要记住的事情:
So use a sortable date string for the primary key of the entity:
...
Now, you don't even have to include a sort order in your queries, although it won't hurt to explicitly sort by key.
Things to remember: