Pytesser 不准确
简单的问题。当我通过 pytesser 运行 此 图像时,我得到 $+s。我该如何解决这个问题?
编辑
所以...我的代码生成与上面链接的图像类似的图像,只是数字不同,并且应该解决简单的数学问题,如果我能从其中得到所有内容,这显然是不可能的图片是 $+s
这是我当前使用的代码:
from pytesser import *
time.sleep(2)
i = 0
operator = "+"
while i < 100:
time.sleep(.1);
img = ImageGrab.grab((349, 197, 349 + 452, 197 + 180))
equation = image_to_string(img)
然后我将在 pytesser 工作后立即继续解析 equation...。
Simple question. When I run this image through pytesser, i get $+s. How can I fix that?
EDIT
So... my code generates images similar to the image linked above, just with different numbers, and is supposed to solve the simple math problem, which is obviously impossible if all I can get out of the picture is $+s
Here's the code I'm currently using:
from pytesser import *
time.sleep(2)
i = 0
operator = "+"
while i < 100:
time.sleep(.1);
img = ImageGrab.grab((349, 197, 349 + 452, 197 + 180))
equation = image_to_string(img)
Then I'm going to go on to parse equation... as soon as I get pytesser working.
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!






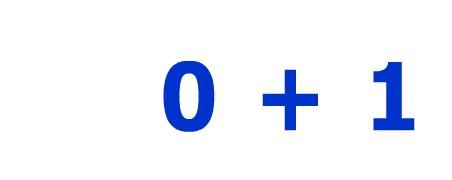{kind=link}
发布评论
评论(2)
试试我的小功能吧。我正在从
svn存储库运行tesseract,因此我的结果可能更准确。我在 Linux 上,所以在 Windows 上,我想你必须用
tesseract.exe替换tesseract才能使其工作。以及一个示例 Python 会话:
Try my little function. I'm running
tesseractfrom thesvnrepo, so my results might be more accurate.I'm on Linux, so on Windows, I'd imagine that you'll have to replace
tesseractwithtesseract.exeto make it work.And a sample Python session:
如果您使用的是 Linux,则使用 gocr 更准确。您可以使用它
并使用 stdout 中的 readlines 将输出结果操作为您想要的一切(即从 gocr 为特定变量创建输出)。
if you're in linux, use gocr is more accurate. you can use it through
and use readlines from stdout for manipulating output result to everything what you want (i.e creating output from gocr for specific variable).