如何使用 python 从 xlsx 文件加载数据
这是我的 xlsx 文件:
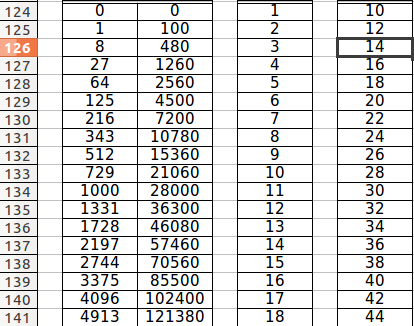
,我想将此数据更改为 dict像这样:
{
0:{
'a':1,
'b':100,
'c':2,
'd':10
},
1:{
'a':8,
'b':480,
'c':3,
'd':14
}
...
}
有人知道Python库可以做到这一点,并从第124行开始,到第141行结束,
谢谢
this is my xlsx file :
and i want to get change this data to a dict like this :
{
0:{
'a':1,
'b':100,
'c':2,
'd':10
},
1:{
'a':8,
'b':480,
'c':3,
'd':14
}
...
}
so did somebody know a python lib to do this , and start from the line 124, and end of the line 141 ,
thanks
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!




发布评论
评论(4)
xlrd 的选项:
(1) 你的 xlsx 文件看起来不是很大;将其另存为 xls。
(2) 使用
xlrd加上附加的 beta 测试模块xlsxrd(找到我的电子邮件地址并询问);该组合将无缝地从 xls 和 xlsx 文件读取数据(相同的 API;它检查文件内容以确定它是 xls、xlsx 还是冒名顶替者)。无论哪种情况,下面的(未经测试的)代码都应该满足您的要求:
Options with xlrd:
(1) Your xlsx file doesn't look very large; save it as xls.
(2) Use
xlrdplus the bolt-on beta-test modulexlsxrd(find my e-mail address and ask for it); the combination will read data from xls and xlsx files seamlessly (same APIs; it examines the file contents to determine whether it's xls, xlsx, or an imposter).In either case, something like the (untested) code below should do what you want:
假设您有这样的数据:
2014 年的许多潜在答案之一是:
现在数据是字典数组:
可以读取文档
Suppose you had the data like this:
One of many potential answers in 2014 is:
Now the data is an array of dictionaries:
Documentation can be read here
另一个选择是 openpyxl。我一直想尝试一下,但还没有时间,所以我不能说它有多好。
Another option is openpyxl. I've been meaning to try it out, but haven't gotten around to it yet, so I can't say how good it is.
这是仅使用标准库的非常非常粗略的实现。
Here's a very very rough implementation using just the standard library.