如何利用我的 haskell 并行代码中的并行性?
我刚刚说过使用 Haskell 半显式并行性与 GHC 6.12 进行工作。我编写了以下 haskell 代码来并行计算列表上 4 个元素上的 fibonnaci 函数的映射,同时计算两个元素上的函数 sumEuler 的映射。
import Control.Parallel
import Control.Parallel.Strategies
fib :: Int -> Int
fib 0 = 0
fib 1 = 1
fib n = fib (n-1) + fib (n-2)
mkList :: Int -> [Int]
mkList n = [1..n-1]
relprime :: Int -> Int -> Bool
relprime x y = gcd x y == 1
euler :: Int -> Int
euler n = length (filter (relprime n) (mkList n))
sumEuler :: Int -> Int
sumEuler = sum . (map euler) . mkList
-- parallel initiation of list walk
mapFib :: [Int]
mapFib = map fib [37, 38, 39, 40]
mapEuler :: [Int]
mapEuler = map sumEuler [7600, 7600]
parMapFibEuler :: Int
parMapFibEuler = (forceList mapFib) `par` (forceList mapEuler `pseq` (sum mapFib + sum mapEuler))
-- how to evaluate in whnf form by forcing
forceList :: [a] -> ()
forceList [] = ()
forceList (x:xs) = x `pseq` (forceList xs)
main = do putStrLn (" sum : " ++ show parMapFibEuler)
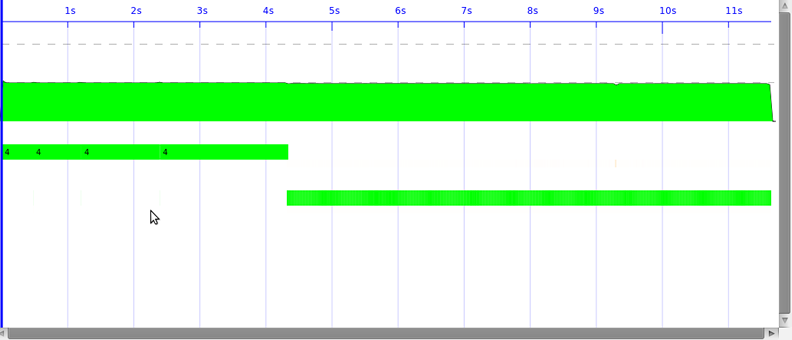
为了并行改进我的程序,我用 par 和 pseq 以及一个 forcing 函数重写了它来强制 whnf 评估。我的问题是,通过查看线程范围,我似乎没有获得任何并行性。事情变得更糟,因为我没有获得任何加速。
这就是为什么我有这两个问题
问题 1 我如何修改我的代码以利用任何并行性?
问题 2 我如何编写程序才能使用策略(parMap、parList、rdeepseq 等...)?
策略的首次改进
根据他的贡献
parMapFibEuler = (mapFib, mapEuler) `using` s `seq` (sum mapFib + sum mapEuler) where
s = parTuple2 (seqList rseq) (seqList rseq)
,并行性出现在线程范围中,但不足以显着加速

I've just stated working in haskell semi-explicit parallelism with GHC 6.12. I've write the following haskell code to compute in parallel the map of the fibonnaci function upon 4 elements on a list, and in the same time the map of the function sumEuler upon two elements.
import Control.Parallel
import Control.Parallel.Strategies
fib :: Int -> Int
fib 0 = 0
fib 1 = 1
fib n = fib (n-1) + fib (n-2)
mkList :: Int -> [Int]
mkList n = [1..n-1]
relprime :: Int -> Int -> Bool
relprime x y = gcd x y == 1
euler :: Int -> Int
euler n = length (filter (relprime n) (mkList n))
sumEuler :: Int -> Int
sumEuler = sum . (map euler) . mkList
-- parallel initiation of list walk
mapFib :: [Int]
mapFib = map fib [37, 38, 39, 40]
mapEuler :: [Int]
mapEuler = map sumEuler [7600, 7600]
parMapFibEuler :: Int
parMapFibEuler = (forceList mapFib) `par` (forceList mapEuler `pseq` (sum mapFib + sum mapEuler))
-- how to evaluate in whnf form by forcing
forceList :: [a] -> ()
forceList [] = ()
forceList (x:xs) = x `pseq` (forceList xs)
main = do putStrLn (" sum : " ++ show parMapFibEuler)
to improve my program in parallel I rewrote it with par and pseq and a forcing function to force whnf evaluation. My problem is that by looking in the threadscope it appear that i didn't gain any parallelism. Things are worse because i didn't gain any speedup.
That why I have theses two questions
Question 1 How could I modify my code to exploit any parallelism ?
Question 2 How could I write my program in order to use Strategies (parMap, parList, rdeepseq and so on ...) ?
First improvement with Strategies
according to his contribution
parMapFibEuler = (mapFib, mapEuler) `using` s `seq` (sum mapFib + sum mapEuler) where
s = parTuple2 (seqList rseq) (seqList rseq)
the parallelism appears in the threadscope but not enough to have a significant speedup
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!






发布评论
评论(4)
您在这里看不到任何并行性的原因是因为您的火花已被垃圾收集。使用 +RTS -s 运行程序并注意这一行:
火花已被“修剪”,这意味着被垃圾收集器删除。在 GHC 7 中,我们对 Spark 的语义进行了更改,如果程序的其余部分没有引用 Spark,那么它现在会被垃圾收集 (GC);详细信息请参阅“不再使用 Seq”论文。
为什么你的情况下 Spark 会被 GC 处理?看代码:
这里的火花是表达式
forkList mapFib。请注意,程序的其余部分不需要该表达式的值;它仅作为par的参数出现。 GHC 知道这不是必需的,因此它会被垃圾收集。最近对parallel 包进行的更改的全部目的是让您轻松避免这个熊陷阱。一个好的经验法则是直接使用
Control.Parallel.Strategies而不是par和pseq。我首选的编写方法是,但遗憾的是,这不适用于 GHC 7.0.2,因为 Spark
sum mapFib作为静态表达式(CAF)浮动,并且运行时不会不要认为指向静态表达式的火花值得保留(我会解决这个问题)。当然,这在真实的程序中不会发生!因此,让我们让程序更加现实一点,并击败 CAF 优化:现在我与 GHC 7.0.2 获得了良好的并行性。但是,请注意@John 的评论也适用:通常您希望寻找更细粒度的并行性,以便让 GHC 使用您的所有处理器。
The reason you aren't seeing any parallelism here is because your spark has been garbage collected. Run the program with
+RTS -sand note this line:the spark has been "pruned", which means removed by the garbage collector. In GHC 7 we made a change to the semantics of sparks, such that a spark is now garbage collected (GC'd) if it is not referred to by the rest of the program; the details are in the "Seq no more" paper.
Why is the spark GC'd in your case? Look at the code:
the spark here is the expression
forkList mapFib. Note that the value of this expression is not required by the rest of the program; it only appears as an argument topar. GHC knows that it isn't required, so it gets garbage collected.The whole point of the recent changes to the
parallelpackage were to let you easily avoid this bear trap. A good Rule of Thumb is to useControl.Parallel.Strategiesrather thanparandpseqdirectly. My preferred way to write this would bebut sadly this doesn't work with GHC 7.0.2, because the spark
sum mapFibis floated out as a static expression (a CAF), and the runtime doesn't think sparks that point to static expressions are worth keeping (I'll fix this). This wouldn't happen in a real program, of course! So let's make the program a bit more realistic and defeat the CAF optimisation:Now I get good parallelism with GHC 7.0.2. However, note that @John's comments also apply: generally you want to look for more fine-grained parallelism so as to let GHC use all your processors.
你的并行性太粗略了,无法产生太多有益的效果。可以高效并行完成的最大工作块在
sumEuler中,因此您应该在其中添加par注释。尝试将sumEuler更改为:parMap来自Control.Parallel.Strategies;它表达了一个可以并行完成的映射。第一个参数,具有Strategy a类型的rseq,用于强制计算到特定点,否则由于惰性而不会完成任何工作。rseq适用于大多数数字类型。在这里向
fib添加并行性没有什么用处,下面关于fib 40没有足够的工作使其值得。除了 threadscope 之外,使用
-s标志运行程序也很有用。 查找类似以下的行:在输出中 每个火花都是工作队列中可能并行执行的一个条目。转换的火花实际上是并行完成的,而修剪的火花意味着主线程在工作线程有机会这样做之前到达它们。如果修剪的数量很高,则意味着您的并行表达式太细粒度。如果火花总数较低,则表明您没有尝试并行执行足够的操作。
最后,我认为
parMapFibEuler最好写成:mapEuler太短了,无法在这里有效地表达任何并行性,特别是当euler已经执行时并联。我怀疑它是否会对mapFib产生实质性影响。如果列表mapFib和mapEuler更长,这里的并行性会更有用。您可以使用parBuffer来代替parList,它对于列表使用者来说效果很好。使用 GHC 7.0.2,进行这两项更改将运行时间从 12 秒缩短到 8 秒。
Your parallelism is far too course-grained to have much beneficial effect. The largest chunks of work that can be done in parallel efficiently are in
sumEuler, so that's where you should add yourparannotations. Try changingsumEulerto:parMapis fromControl.Parallel.Strategies; it expresses a map that can be done in parallel. The first argument,rseqhaving typeStrategy a, is used to force the computation to a specific point, otherwise no work would be done, due to laziness.rseqis fine for most numeric types.It's not useful to add parallelism to
fibhere, below aboutfib 40there isn't enough work to make it worthwhile.In addition to threadscope, it's useful to run your program with the
-sflag. Look for a line like:in the output. Each spark is an entry in a work queue to possibly be performed in parallel. Converted sparks are actually done in parallel, while pruned sparks mean that the main thread got to them before a worker thread had the chance to do so. If the pruned number is high, it means your parallel expressions are too fine-grained. If the total number of sparks is low, you aren't trying to do enough in parallel.
Finally, I think
parMapFibEuleris better written as:mapEuleris simply too short to have any parallelism usefully expressed here, especially aseuleris already performed in parallel. I'm doubtful that it makes a substantial difference formapFibeither. If the listsmapFibandmapEulerwere longer, parallelism here would be more useful. Instead ofparListyou may be able to useparBuffer, which tends to work well for list consumers.Making these two changes cuts the runtime from 12s to 8s for me, with GHC 7.0.2.
嗯...也许?
即在后台生成
mapFib并计算mapEuler,并且仅在其之后 (mapEuler) 执行其总和的(+)。实际上我想你可以做类似的事情:
关于第二个问题:
据我所知,策略 - 是将数据结构与
par和seq结合起来的“策略”。您可以编写
forceList = withStrategy (seqList rseq)您也可以编写如下代码:
即应用于两个列表的元组的策略将强制并行评估它们,但每个列表将被迫按顺序评估。
Hmmm... Maybe?
I.e. spawn
mapFibin background and calculatemapEulerand only after it (mapEuler) do(+)of their sums.Actually I guess you can do something like:
About Q2:
As I know strategies - is the "strategies" to combine data-structures with those
parandseq.You can write your
forceList = withStrategy (seqList rseq)As well you can write your code like:
I.e. strategy applied to tuple of two lists will force their evaulation in parallel, but each list will be forced to be evaluated sequentially.
首先,我假设您知道您的
fib定义很糟糕,并且您这样做只是为了使用并行包。您似乎在错误的级别上寻求并行性。并行化
mapFib和mapEuler不会带来很好的加速,因为计算mapFib需要更多工作。您应该做的是并行计算这些非常昂贵的元素中的每一个,这稍微细一些,但也不过分:此外,我最初使用 Control.Parallel.Strategies 而不是 Control.Parallel,但后来开始喜欢它,因为它更可读并避免像你这样的问题,人们会期望并行性,并且必须眯着眼睛才能弄清楚为什么你没有得到任何并行性。
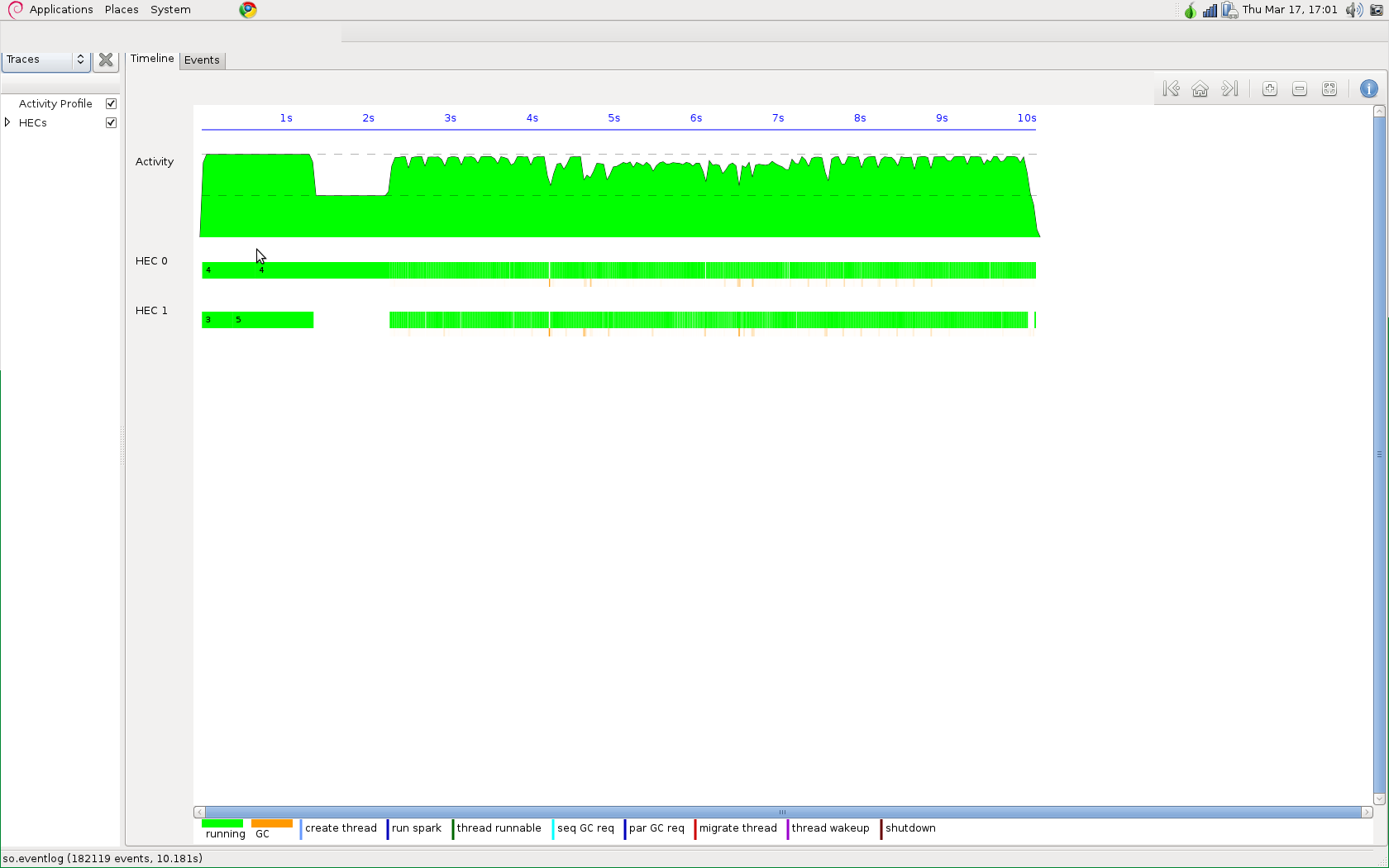
最后,您应该始终发布您如何编译以及如何运行您期望并行化的代码。例如:
产量:
First off, I assume you know your
fibdefinition is awful and you're just doing this to play with the parallel package.You seem to be going for parallelism at the wrong level. Parallelizing
mapFibandmapEulerwon't give a good speed-up because there is more work to computemapFib. What you should do is compute each of these very expensive elements in parallel, which is slightly finer grain but not overly so:Also, I originally fought using Control.Parallel.Strategies over Control.Parallel but have come to like it as it is more readable and avoids issues like yours where one would expect parallelism and have to squint at it to figure out why you aren't getting any.
Finally, you should always post how you compile and how you run code you're expecting to be parallelized. For example:
Yields:
