yacc 输出帮助
例如,如果我有这个语法
start : TKN id '{' '}' {cout<<$2<
-
包含 iostream,TKN 声明为 token,id 类型声明为 char *
-
as输入 我输入
tkn aaa { }
输出不应该是 aaa 吗?有时,它打印 } 和 0 有时它只是挂起
我想获取 id 的值,如何正确获取?
lex.l
%{
#include "yacc.hpp"
#include <math.h>
#include<iostream>
#include<string>
int rows = 1,tmp=0;
%}
Id [a-zA-Z_][0-9a-zA-Z_]*
%x String ...
%option c++
%option noyywrap
%%
{Id} {strcpy(yylval.strVal,yytext);cout<<"lex= "<<yytext<<endl;return Id;}//output line 1
...
yacc.y
%output ="yacc.cpp"
%defines
%verbose
%token Id
%token NAMESPACE
%union{
int iVal;
float fVal;
char* strVal;
class Symbol* symPtr;
class NS* nsPtr;
};
%token <iVal> INT_VAL;
%token <fVal> F_VAL;
%token <strVal> STR_VAL INT FLOAT STRING Id ;
%type <nsPtr> namespacedecl
%type <symPtr> ns_closer
%type <strVal> Q_ID
//-------------------------------------------
namespacedecl : NAMESPACE Q_ID '{' '}' {cout<<"ns= "<<$2<< endl ;} // output line 3
| NAMESPACE Q_ID '{' typedecl_closer '}' ;
Q_ID : Q_ID '.' Id {cout<<$3<< endl ;$$ = $3;}
| Id {$$ = $1;cout<<"qid="<<$$<<endl;} // output line 2
当然,文件比这个大,但是复制/粘贴所有内容都会让你迷路 ^^
如果有办法附加文件,请告诉我,因为我还是这里的新手,这会容易得多而不是复制/粘贴。
这是我运行时得到的:
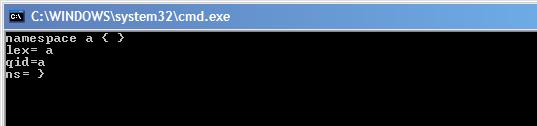
感谢您的回复
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!





发布评论
评论(2)
这取决于“id”规则返回的内容!
注:
惯例是终端标记全部大写 (TKN)。而非终结符是小写的(id)。根据这个约定,我希望 id 对于如何扩展有一个规则。
我怀疑你正在做的是:
这是一个指向 lex 缓冲区的指针。这是一个易失性缓冲区。您不不能依赖其内容保持不变(也不能依赖其被“\0”终止)。您需要做的是在识别令牌时复制该令牌。
根据新输入进行编辑:
在这些行中:
strcpy() 可能不好。
cout 是危险的,因为您不能依赖 yytext 以 '\0' 终止。
我会这样做:
不要乱搞 lex 中的 yacc 结构。它将您的 lex 文件与 yacc 紧密耦合(这不是不必要的)。只需返回令牌即可。然后 yacc 可以手动获取令牌值。
然后在 YACC 文件中:
对于每个具有长令牌的终端(Id),都有一个非终端用于解码终端并在 yacc 联合结构中生成正确的值。在这种情况下,我们的身份不是终端。它只是解码 Id 终端并正确设置令牌(此 Id 在联合结构中没有类型)。
另请注意:
另外:
这行:
看起来错误,但在不知道 INT、FLOAT 和 STRING 是什么的情况下很难分辨。我猜这些是关键字 int、float、string 的终端标记。在这种情况下,您不需要存储实际的令牌字符串。事实上,您知道它是 INT/FLOAT 或 STRING 就足够了。
这应该是:
It depends on what the 'id' rule returned!
Note:
The convention is that terminal tokens are all-caps (TKN). While non-terminal tokens are lowercase (id). By this convention I would expect id to have a rule on how it is expanded.
What I suspect you are doing is:
Which is a pointer into the lex buffer. This is a volatile buffer. You can NOT rely on its content remaining unchanged (nor can you rely on it being '\0' terminated). What you need to do is make a copy of the token at the point you identify it.
Edit based on new input:
In these lines:
The strcpy() is probably bad.
The cout is dangerious as you can not rely on yytext being '\0' terminated.
I would do:
Do not mess around with yacc structures in lex. It tightly couples your lex file to yacc (which is not not necessary). Just return the token. yacc can then get the token value manually.
Then in the YACC File:
For every terminal (Id) that has a long token have a non terminal for de-coding the terminal and generate the correct value in the yacc union structure. In this case we have the ident not terminal. It just decodes the Id terminal and gets the token set up correctly (this Id does not have a type in the union structure).
Also Note:
Additionally:
This line:
Looks wrong, though it is hard to tell without knowing what INT, FLOAT and STRING are. I am guessing these are the terminal tokens for the keywords int,float,string. In which case you do not need to store the actual token string. The fact that you know it is INT/FLOAT or STRING is enough.
This should be:
这在很大程度上取决于您的词法分析器为
id标记返回的 yylval,因为这是在标记移动时复制到解析器堆栈上的内容,因此$2所指的内容到评估规则的时间。据猜测,您有一个类似以下的 lex 规则: with
的解析器中 。在这种情况下,您将一个指针存储到 Flex 的内部扫描器缓冲区中,该缓冲区当时包含“aaa”,但会被稍后的标记覆盖,因此当操作运行时,$2 中的指针指向其他内容。您需要将字符串复制到不会被覆盖的地方,并将 yylval 设置为指向该位置。您可以使用 strdup(3) 将字符串复制到分配的缓冲区,这可以解决此问题,但可能会导致内存泄漏。
编辑
好吧,根据您的附加信息,您的程序没有崩溃是非常令人惊讶的——您将令牌文本
strcpy到yylval.strVal中,但您从未将 yylval.Strval 初始化为指向任何位置,因此您将其复制到某个随机内存位置。您需要将 yylval.strVal = malloc(strlen(yytext)+1); 之类的内容粘贴到 lex.l 操作中,以确保它指向有效的内存,或者只使用更简单且等效的调用strdup,因为它结合了 malloc 和 strcpy:This depends heavily on what your lexer returns as yylval for the
idtoken, as that is what get copied onto the parser stack when the token is shifted, and thus what$2refers to when the rule is evaluated. At a guess, you have a lex rule something like:with
in your parser. In this case, you're storing a pointer into flex's internal scanner buffer which contains 'aaa' at that instant, but will be overwritten by a later token, so by the time the action runs, the pointer in $2 points at something else. You need to copy the string somewhere where it won't be overwritten and set yylval to point at that. You could use strdup(3) to copy the string to a malloced buffer, which would solve this problem but might leave you with memory leaks.
edit
Well with your additional info, its quite surprising that your program doesn't crash -- you
strcpythe token text intoyylval.strVal, but you never initializeyylval.Strvalto point anywhere, so you're copying it into some random memory location. You need to stick something likeyylval.strVal = malloc(strlen(yytext)+1);into the lex.l action to ensure it points at valid memory, or just use the simpler and equivalent call to strdup, as that combines the malloc and strcpy: