Scrapy - 如何管理cookie/会话
我对 cookie 如何与 Scrapy 一起工作以及如何管理这些 cookie 有点困惑。
这基本上是我想做的事情的简化版本: 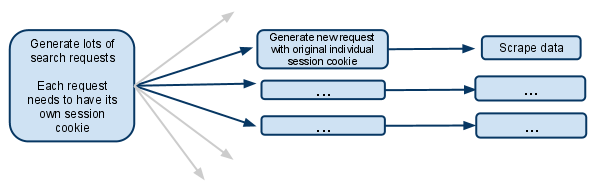
网站的工作方式:
当您访问该网站时,您会获得一个会话 cookie。
当您进行搜索时,网站会记住您搜索的内容,因此当您执行转到下一页结果之类的操作时,它知道它正在处理的搜索。
我的脚本:
我的蜘蛛的起始网址为 searchpage_url
搜索页面由 parse() 请求,搜索表单响应传递给 search_generator()
search_generator() 然后使用 FormRequest 和搜索表单响应产生大量搜索请求。
每个 FormRequest 以及后续子请求都需要拥有自己的会话,因此需要拥有自己的单独 cookiejar 和会话 cookie。
我已经看过文档中讨论阻止 cookie 合并的元选项的部分。这实际上意味着什么?这是否意味着发出请求的蜘蛛将在其余生中拥有自己的 cookiejar?
如果 cookie 位于每个蜘蛛级别,那么当生成多个蜘蛛时它如何工作?是否可以只让第一个请求生成器生成新的蜘蛛,并确保从那时起只有该蜘蛛处理未来的请求?
我假设我必须禁用多个并发请求..否则一个蜘蛛将在同一会话cookie下进行多次搜索,并且未来的请求将仅与最近进行的搜索相关?
我很困惑,任何澄清都会受到极大的欢迎!
编辑:
我刚刚想到的另一种选择是完全手动管理会话 cookie,并将其从一个请求传递到另一个请求。
我想这意味着禁用cookie..然后从搜索响应中获取会话cookie,并将其传递给每个后续请求。
在这种情况下你应该这样做吗?
I'm a bit confused as to how cookies work with Scrapy, and how you manage those cookies.
This is basically a simplified version of what I'm trying to do:
The way the website works:
When you visit the website you get a session cookie.
When you make a search, the website remembers what you searched for, so when you do something like going to the next page of results, it knows the search it is dealing with.
My script:
My spider has a start url of searchpage_url
The searchpage is requested by parse() and the search form response gets passed to search_generator()
search_generator() then yields lots of search requests using FormRequest and the search form response.
Each of those FormRequests, and subsequent child requests need to have it's own session, so needs to have it's own individual cookiejar and it's own session cookie.
I've seen the section of the docs that talks about a meta option that stops cookies from being merged. What does that actually mean? Does it mean the spider that makes the request will have its own cookiejar for the rest of its life?
If the cookies are then on a per Spider level, then how does it work when multiple spiders are spawned? Is it possible to make only the first request generator spawn new spiders and make sure that from then on only that spider deals with future requests?
I assume I have to disable multiple concurrent requests.. otherwise one spider would be making multiple searches under the same session cookie, and future requests will only relate to the most recent search made?
I'm confused, any clarification would be greatly received!
EDIT:
Another options I've just thought of is managing the session cookie completely manually, and passing it from one request to the other.
I suppose that would mean disabling cookies.. and then grabbing the session cookie from the search response, and passing it along to each subsequent request.
Is this what you should do in this situation?

如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

发布评论
评论(6)

from scrapy.http.cookies import CookieJar
...
class Spider(BaseSpider):
def parse(self, response):
'''Parse category page, extract subcategories links.'''
hxs = HtmlXPathSelector(response)
subcategories = hxs.select(".../@href")
for subcategorySearchLink in subcategories:
subcategorySearchLink = urlparse.urljoin(response.url, subcategorySearchLink)
self.log('Found subcategory link: ' + subcategorySearchLink), log.DEBUG)
yield Request(subcategorySearchLink, callback = self.extractItemLinks,
meta = {'dont_merge_cookies': True})
'''Use dont_merge_cookies to force site generate new PHPSESSID cookie.
This is needed because the site uses sessions to remember the search parameters.'''
def extractItemLinks(self, response):
'''Extract item links from subcategory page and go to next page.'''
hxs = HtmlXPathSelector(response)
for itemLink in hxs.select(".../a/@href"):
itemLink = urlparse.urljoin(response.url, itemLink)
print 'Requesting item page %s' % itemLink
yield Request(...)
nextPageLink = self.getFirst(".../@href", hxs)
if nextPageLink:
nextPageLink = urlparse.urljoin(response.url, nextPageLink)
self.log('\nGoing to next search page: ' + nextPageLink + '\n', log.DEBUG)
cookieJar = response.meta.setdefault('cookie_jar', CookieJar())
cookieJar.extract_cookies(response, response.request)
request = Request(nextPageLink, callback = self.extractItemLinks,
meta = {'dont_merge_cookies': True, 'cookie_jar': cookieJar})
cookieJar.add_cookie_header(request) # apply Set-Cookie ourselves
yield request
else:
self.log('Whole subcategory scraped.', log.DEBUG)


Scrapy 有一个 下载器中间件 CookiesMiddleware 实现支持cookie。您只需要启用它即可。它模仿浏览器中 cookiejar 的工作方式。
- 当请求通过
CookiesMiddleware时,它会读取该域的 cookie 并将其设置在标头Cookie上。 - 当响应返回时,
CookiesMiddleware读取响应头Set-Cookie上服务器发送的 cookie。并将其保存/合并到 mw 上的 cookiejar 中。
我已经看过文档中讨论阻止 cookie 合并的元选项的部分。这实际上意味着什么?这是否意味着发出请求的蜘蛛将在其余生中拥有自己的 cookiejar?
如果 cookie 位于每个蜘蛛级别,那么当生成多个蜘蛛时它如何工作?
每个蜘蛛都有其唯一的下载中间件。所以蜘蛛有单独的饼干罐。
通常,来自一台 Spider 的所有请求都会共享一个 cookiejar。但是 CookiesMiddleware 可以选择自定义此行为
Request.meta["dont_merge_cookies"] = True告诉 mw 这个请求不会读取Cookie来自cookiejar。并且不要将 resp 中的Set-Cookie合并到 cookiejar 中。这是一个请求级别开关。CookiesMiddleware支持多个 cookiejar。您必须控制在请求级别使用哪个 cookiejar。Request.meta["cookiejar"] = custom_cookiejar_name。
请查看CookiesMiddleware的文档和相关源代码。


有几个 Scrapy 扩展提供了更多处理会话的功能:
- scrapy-sessions 允许您将静态定义的配置文件(代理和用户代理)附加到您的会话、处理 Cookie 并按需轮换配置文件
- scrapy-dynamic-sessions 几乎相同,但允许您随机选择代理和用户代理并处理由于任何错误而导致的重试请求
绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!




三年后,我认为这正是您所寻找的:
http://doc.scrapy.org/en /latest/topics/downloader-middleware.html#std:reqmeta-cookiejar
只需在蜘蛛的 start_requests 方法中使用类似的内容即可:
并记住,对于后续请求,您每次都需要显式重新附加 cookiejar:
Three years later, I think this is exactly what you were looking for:
http://doc.scrapy.org/en/latest/topics/downloader-middleware.html#std:reqmeta-cookiejar
Just use something like this in your spider's start_requests method:
And remember that for subsequent requests, you need to explicitly reattach the cookiejar each time: