针对特定应用的贝叶斯网络的 pythonic 实现
这就是我问这个问题的原因: 去年,我编写了一些 C++ 代码来计算特定类型模型(由贝叶斯网络描述)的后验概率。该模型运行得很好,其他一些人开始使用我的软件。现在我想改进我的模型。由于我已经为新模型编写了略有不同的推理算法,因此我决定使用 python,因为运行时并不是至关重要,而且 python 可以让我编写更优雅且易于管理的代码。
通常在这种情况下,我会在 python 中搜索现有的贝叶斯网络包,但我使用的推理算法是我自己的,而且我也认为这将是一个很好的机会来了解更多关于 python 中的良好设计。
我已经找到了一个很棒的用于网络图的 python 模块(networkx),它允许您将字典附加到每个节点和每个边。本质上,这可以让我给出节点和边的属性。
对于特定网络及其观察到的数据,我需要编写一个函数来计算模型中未分配变量的可能性。
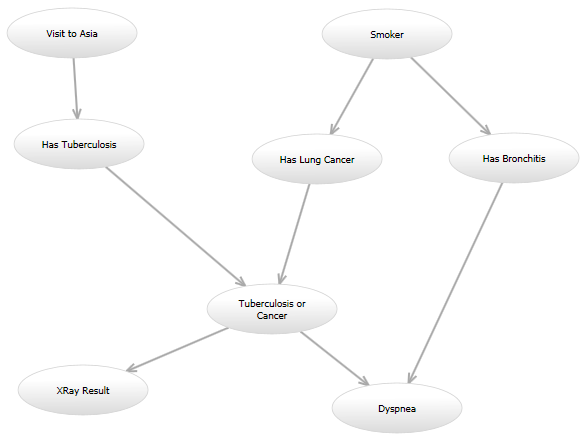
例如,在经典的“亚洲”网络中 (http://www.bayesserver.com/ Resources/Images/AsiaNetwork.png),在已知“X射线结果”和“呼吸困难”状态的情况下,我需要编写一个函数来计算其他变量具有特定值的可能性(根据某些模型) 。
这是我的编程问题: 我将尝试一些模型,将来我可能会想尝试另一种模型。例如,一种模型可能看起来与亚洲网络一模一样。在另一个模型中,可以将有向边从“访问亚洲”添加到“患有肺癌”。另一个模型可能使用原始有向图,但给定“结核或癌症”和“患有支气管炎”节点的“呼吸困难”节点的概率模型可能不同。所有这些模型都将以不同的方式计算可能性。
所有模型都会有很大的重叠;例如,如果所有输入均为“0”,则进入“Or”节点的多条边将始终生成“0”,否则生成“1”。但有些模型的节点采用某个范围内的整数值,而其他模型则采用布尔值。
过去,我一直在努力解决如何编写这样的事情。我不会撒谎;有相当数量的复制和粘贴代码,有时我需要将单个方法中的更改传播到多个文件。这次我真的想花时间以正确的方式来做这件事。
一些选择:
- 我已经以正确的方式这样做了。先写代码,再提问。复制和粘贴代码并为每个模型分配一个类会更快。世界是一个黑暗且混乱的地方......
- 每个模型都是其自己的类,也是通用贝叶斯网络模型的子类。这个通用模型将使用一些将被覆盖的函数。斯特鲁斯特鲁普会感到自豪。
- 在同一类中创建多个函数来计算不同的可能性。
- 编写一个通用的 BayesianNetwork 库,并将我的推理问题实现为该库读取的特定图形。节点和边应该被赋予诸如“Boolean”和“OrFunction”之类的属性,在给定父节点的已知状态的情况下,这些属性可用于计算不同结果的概率。这些属性字符串(例如“OrFunction”)甚至可以用于查找和调用正确的函数。也许几年后我会做出类似于 1988 年版 Mathematica 的东西!
非常感谢您的帮助。
更新: 面向对象的思想在这里很有帮助(每个节点都有一组指定的特定节点子类型的前驱节点,并且每个节点都有一个似然函数,用于计算给定前驱节点的状态等的不同结果状态的可能性)。哦哦!
This is why I'm asking this question:
Last year I made some C++ code to compute posterior probabilities for a particular type of model (described by a Bayesian network). The model worked pretty well and some other people started to use my software. Now I want to improve my model. Since I'm already coding slightly different inference algorithms for the new model, I decided to use python because runtime wasn't critically important and python may let me make more elegant and manageable code.
Usually in this situation I'd search for an existing Bayesian network package in python, but the inference algorithms I'm using are my own, and I also thought this would be a great opportunity to learn more about good design in python.
I've already found a great python module for network graphs (networkx), which allows you to attach a dictionary to each node and to each edge. Essentially, this would let me give nodes and edges properties.
For a particular network and it's observed data, I need to write a function that computes the likelihood of the unassigned variables in the model.
For instance, in the classic "Asia" network (http://www.bayesserver.com/Resources/Images/AsiaNetwork.png), with the states of "XRay Result" and "Dyspnea" known, I need to write a function to compute the likelihood that the other variables have certain values (according to some model).
Here is my programming question:
I'm going to try a handful of models, and in the future it's possible I'll want to try another model after that. For instance, one model might look exactly like the Asia network. In another model, a directed edge might be added from "Visit to Asia" to "Has Lung Cancer." Another model might use the original directed graph, but the probability model for the "Dyspnea" node given the "Tuberculosis or Cancer" and "Has Bronchitis" nodes might be different. All of these models will compute the likelihood in a different way.
All the models will have substantial overlap; for instance, multiple edges going into an "Or" node will always make a "0" if all inputs are "0" and a "1" otherwise. But some models will have nodes that take on integer values in some range, while others will be boolean.
In the past I've struggled with how to program things like this. I'm not going to lie; there's been a fair amount of copied and pasted code and sometimes I've needed to propagate changes in a single method to multiple files. This time I really want to spend the time to do this the right way.
Some options:
- I was already doing this the right way. Code first, ask questions later. It's faster to copy and paste the code and have one class for each model. The world is a dark and disorganized place...
- Each model is its own class, but also a subclass of a general BayesianNetwork model. This general model will use some functions that are going to be overridden. Stroustrup would be proud.
- Make several functions in the same class that compute the different likelihoods.
- Code a general BayesianNetwork library and implement my inference problems as specific graphs read in by this library. The nodes and edges should be given properties like "Boolean" and "OrFunction" which, given known states of the parent node, can be used to compute the probabilities of different outcomes. These property strings, like "OrFunction" could even be used to look up and call the right function. Maybe in a couple of years I'll make something similar to the 1988 version of Mathematica!
Thanks a lot for your help.
Update:
Object oriented ideas help a lot here (each node has a designated set of predecessor nodes of a certain node subtype, and each node has a likelihood function that computes its likelihood of different outcome states given the states of the predecessor nodes, etc.). OOP FTW!
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!






{kind=link}
发布评论
评论(4)
我在业余时间从事这类事情已经有一段时间了。我想我现在正在处理同一问题的第三个或第四个版本。我实际上正准备发布 Fathom 的另一个版本(https://github.com/davidrichards/fathom/wiki),其中包含动态贝叶斯模型和不同的持久层。
当我试图弄清楚我的答案时,它已经变得很长了。我对此表示歉意。以下是我解决这个问题的方法,这似乎回答了你的一些问题(有点间接):
我从 Judea Pearl 对贝叶斯网络中信念传播的分解开始。也就是说,它是一个图表,其中先验赔率(因果支持)来自父母,可能性(诊断支持)来自儿童。这样,基本类只是一个BeliefNode,就像您所描述的在BeliefNodes之间添加一个额外的节点,即LinkMatrix。通过这种方式,我可以根据我使用的 LinkMatrix 类型明确选择我正在使用的可能性类型。它可以更轻松地解释信念网络随后正在做什么,并使计算更简单。
我对基本 BeliefNode 所做的任何子类化或更改都是为了对连续变量进行分箱,而不是更改传播规则或节点关联。
我决定将所有数据保留在 BeliefNode 中,而仅将固定数据保留在 LinkedMatrix 中。这与确保我以最少的网络活动保持干净的信念更新有关。这意味着我的 BeliefNode 存储:
可以构建 LinkMatrix根据节点之间关系的性质,可以使用许多不同的算法。您描述的所有模型都只是您使用的不同类。也许最简单的方法是默认使用或门,然后如果节点之间有特殊关系,则选择其他方法来处理 LinkMatrix。
我使用 MongoDB 进行持久化和缓存。我在事件模型内访问这些数据,以实现速度和异步访问。这使得网络具有相当的性能,同时如果需要的话也有机会变得非常大。另外,由于我以这种方式使用 Mongo,我可以轻松地为同一知识库创建新的上下文。因此,举例来说,如果我有一个诊断树,那么诊断的一些诊断支持将来自患者的症状和测试。我所做的就是为该患者创造一个背景,然后根据该特定患者的证据传播我的信念。同样,如果医生说患者可能患有两种或多种疾病,那么我可以更改一些链接矩阵以不同的方式传播信念更新。
如果您不想在系统中使用 Mongo 之类的东西,但您计划让多个消费者处理知识库,那么您将需要采用某种缓存系统来确保您正在处理最新的内容- 随时更新节点。
我的工作是开源的,因此如果您愿意,可以跟随我的脚步。它都是 Ruby,所以它与 Python 类似,但不一定是直接替代品。我喜欢我的设计的一件事是,人类解释结果所需的所有信息都可以在节点本身中找到,而不是在代码中。这可以通过定性描述或网络结构来完成。
因此,这里有一些我与您的设计的重要区别:
一个重要的警告:我正在谈论的一些内容尚未发布。我一直在研究我正在谈论的内容,直到今天早上 2:00 左右,所以它绝对是最新的,并且肯定会得到我的定期关注,但尚未全部向公众开放。由于这是我的热情所在,如果您愿意,我很乐意回答任何问题或在项目上合作。
I've been working on this kind of thing in my spare time for quite a while. I think I'm on my third or fourth version of this same problem right now. I'm actually getting ready to release another version of Fathom (https://github.com/davidrichards/fathom/wiki) with dynamic bayesian models included and a different persistence layer.
As I've tried to make my answer clear, it's gotten quite long. I apologize for that. Here's how I've been attacking the problem, which seems to answer some of your questions (somewhat indirectly):
I've started with Judea Pearl's breakdown of belief propagation in a Bayesian Network. That is, it's a graph with prior odds (causal support) coming from parents and likelihoods (diagnostic support) coming from children. In this way, the basic class is just a BeliefNode, much like what you described with an extra node between BeliefNodes, a LinkMatrix. In this way, I explicitly choose the type of likelihood I'm using by the type of LinkMatrix I use. It makes it easier to explain what the belief network is doing afterwards as well as keeps the computation simpler.
Any subclassing or changes that I'd make to the basic BeliefNode would be for binning continuous variables, rather than changing propagation rules or node associations.
I've decided on keeping all data inside the BeliefNode, and only fixed data in the LinkedMatrix. This has to do with ensuring that I maintain clean belief updates with minimal network activity. This means that my BeliefNode stores:
The LinkMatrix can be constructed with a number of different algorithms, depending on the nature of the relationship between the nodes. All of the models that you're describing would just be different classes that you'd employ. Probably the easiest thing to do is default to an or-gate, and then choose other ways to handle the LinkMatrix if we have a special relationship between the nodes.
I use MongoDB for persistence and caching. I access this data inside of an evented model for speed and asynchronous access. This makes the network fairly performant while also having the opportunity to be very large if it needs to be. Also, since I'm using Mongo in this way, I can easily create a new context for the same knowledge base. So, for example, if I have a diagnostic tree, some of the diagnostic support for a diagnosis will come from a patient's symptoms and tests. What I do is create a context for that patient and then propagate my beliefs based on the evidence from that particular patient. Likewise, if a doctor said that a patient was likely experiencing two or more diseases, then I could change some of my link matrices to propagate the belief updates differently.
If you don't want to use something like Mongo for your system, but you are planning on having more than one consumer working on the knowledge base, you will need to adopt some sort of caching system to make sure that you are working on freshly-updated nodes at all times.
My work is open source, so you can follow along if you'd like. It's all Ruby, so it would be similar to your Python, but not necessarily a drop-in replacement. One thing that I like about my design is that all of the information needed for humans to interpret the results can be found in the nodes themselves, rather than in the code. This can be done in the qualitative descriptions, or in the structure of the network.
So, here are some important differences I have with your design:
One big caveat: some of what I'm talking about hasn't been released yet. I worked on the stuff I am talking about until about 2:00 this morning, so it's definitely current and definitely getting regular attention from me, but isn't all available to the public just yet. Since this is a passion of mine, I'd be happy to answer any questions or work together on a project if you'd like.
Mozart/Oz3 基于约束的推理系统解决了类似的问题:您用约束来描述您的问题有限域变量、约束传播者和分配者、成本函数。当无法进行更多推理但仍然存在未绑定变量时,它会使用成本函数来分割未绑定变量上的问题空间,这很可能会降低搜索成本:也就是说,如果 X 位于 [a,c] 之间,就是这样一个变量,并且 c (a < b < c) 是最有可能降低搜索成本的点,最终会得到两个问题实例,其中 X 位于 [a,b] 之间,而在另一个实例中,X 位于 [b ,c]。 Mozart 做得相当优雅,因为它将变量绑定具体化为第一类对象(这非常有用,因为 Mozart 普遍是并发和分布式的,可以将问题空间移动到不同的节点)。在其实现中,我怀疑它采用了写时复制策略。
您当然可以在基于图形的库中实现写时复制方案(提示:numpy 使用各种策略来最小化复制;如果您的图形表示基于它,则可以免费获得写时复制语义)并且达到你的目标。
The Mozart/Oz3 constraints-based inference system solves a similar problem: you describe your problem in terms of constraints on finite domain variables, constraint propagators and distributors, cost functions. When no more inference is possible but there are still unbound variables, it uses your cost functions to split the problem space on the unbound variable that most likely reduces search costs: that is, if X is between [a,c] is such a variable, and c (a < b < c) is the point most likely to reduce search cost, you end up with two problem instances where X is between [a,b] and, in the other instance, X is between [b,c]. Mozart does this rather elegantly since it reifies variable binding as a first class object (this is very useful, since Mozart is pervasively concurrent and distributed, to move a problem space to a different node). In its implementation, I suspect that it employs a copy-on-write strategy.
You can surely implement a copy-on-write scheme in a graph-based library (tip: numpy uses various strategies to minimize copying; if you base your graph representation on it, you may get copy-on-write semantics for free) and reach your goals.
我对贝叶斯网络不太熟悉,所以我希望以下内容有用:
过去,我使用高斯过程回归器(而不是高斯过程回归器)遇到了看似类似的问题
贝叶斯分类器。
我最终使用了继承,效果很好。所有特定于模型的参数均使用构造函数设置。 calculate() 函数是虚拟的。
级联不同的方法(例如,组合任意数量的其他方法的求和方法)也可以很好地工作。
I'm not too familiar with Bayesian Networks, so I hope the following is usefull:
In the past I had a seemingly similar problem with a Gaussian Process regressor, instead of a
bayesian classifier.
I ended up using inheritance, which worked out nicely. All model-specific paremeters are set with the constructor. The calculate() functions are virtual.
Cascading different methods (e.g. a sum-method which combines an arbitrary number of other methods) also works nicely that way.
我认为你需要问几个影响设计的问题。
如果大部分时间都花在现有模型上,并且新模型不太常见,那么继承可能是我会使用的设计。它使文档易于构建,并且使用它的代码也易于理解。
如果该库的主要目的是提供一个用于试验不同模型的平台,那么我将使用具有映射到函子的属性的图来基于父级计算事物。该库会更复杂,图形创建也会更复杂,但它会更强大,因为它允许您创建基于节点更改计算函子的混合图。
无论您的最终设计是什么,我都会从简单的一级实现设计开始。让它通过一组自动化测试,然后在完成后重构为更完整的设计。另外,不要忘记版本控制;-)
I think you need to ask a couple questions that influence the design.
If most of the time will be spent with existing models and new models will be less common, then inheritance is probably the design I would use. It makes the documentation easy to structure and the code that uses it will be easy to understand.
If the major purpose of the library is to provide a platform for experimenting with different models, then I would take the graph with properties that map to functors for computing things based on parents. The library would be more complex and graph creation would be more complex, but it would be far more powerful as it would allow you to do hybrid graphs that change the computation functor based on the nodes.
Regardless of what final design you work towards, I would start with a simple one class-one implementation design. Get it passing a set of automated tests, then refactor into the more full design after that is done. Also, don't forget version control ;-)