如何在 R 中构建和重新编码混乱的分类数据?
我正在努力解决如何最好地构建混乱的分类数据,这些数据来自 我需要清理数据集。
编码方案
我正在分析大学科学课程考试的数据。我们正在研究以下模式 学生的反应,我们开发了一个编码方案来表示这些事物 学生正在做他们的答案。编码方案的子集如下所示。

请注意,每个主代码 (1, 2, 3) 中都嵌套有非唯一子代码 (a, b, .. .)。
原始数据是什么样的
我已经创建了实际数据的匿名原始子集,您可以查看它 此处。 我的部分问题是那些对数据进行编码的人注意到一些学生显示 多种模式。编码人员的解决方案是创建足够的列(reason1、reason2、 ...)以多种模式容纳学生。这变得很重要,因为顺序 (reason1, reason2) 是任意的 - 两个学生(例如我的学生 41 和学生 42) 正确应用“依赖关系”的数据集)都应在分析中注册, 不管 3a 是否出现在 reason 列或 reason2 列中。
如何最好地构建学生数据?
我的部分问题是,在原始数据中,并非所有学生显示相同的 图案,或者相同数量、相同顺序的图案。有些学生可能只做一项 一件事情,别人可能会做好几件。因此,示例学生的抽象表示可能 如下所示:

请注意,在上面的示例中,student002 和 student003 均已编码作为“1b”,尽管我故意将顺序显示为不同的,以反映
我的(实际)问题
- 我应该将
reason1、reason2、...连接到一列中吗? - 如何在 R 中(重新)编码
原因以反映某些学生的多重性?
谢谢
,我意识到这个问题既与良好的数据概念化有关,也与 R 的特定功能有关,但我认为在这里提出这个问题是合适的。如果你觉得我问这个问题不合适,请在评论中告诉我,stackoverflow 会自动用悲伤的表情淹没我的收件箱。如果我不够具体,请告诉我,我会尽力说得更清楚。
I'm struggling with how to best structure categorical data that's messy, and comes from a dataset I'll need to clean.
The Coding Scheme
I'm analyzing data from a university science course exam. We're looking at patterns in
student responses, and we developed a coding scheme to represent the kinds of things
students are doing in their answers. A subset of the coding scheme is shown below.
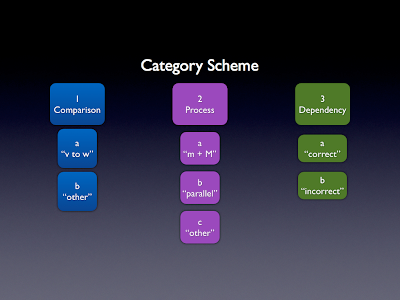
Note that within each major code (1, 2, 3) are nested non-unique sub-codes (a, b, ...).
What the Raw Data Looks Like
I've created an anonymized, raw subset of my actual data which you can view here.
Part of my problem is that those who coded the data noticed that some students displayed
multiple patterns. The coders' solution was to create enough columns (reason1, reason2,
...) to hold students with multiple patterns. That becomes important because the order
(reason1, reason2) is arbitrary--two students (like student 41 and student 42 in my
dataset) who correctly applied "dependency" should both register in an analysis, regardless of
whether 3a appears in the reason column or the reason2 column.
How Can I Best Structure Student Data?
Part of my problem is that in the raw data, not all students display the same
patterns, or the same number of them, in the same order. Some students may do just one
thing, others may do several. So, an abstracted representation of example students might
look like this:

Note in the example above that student002 and student003 both are coded as "1b", although I've deliberately shown the order as different to reflect the reality of my data.
My (Practical) Questions
- Should I concatenate
reason1,reason2,...into one column? - How can I (re)code the
reasons in R to reflect the multiplicity for some students?
Thanks
I realize this question is as much about good data conceptualization as it is about specific features of R, but I thought it would be appropriate to ask it here. If you feel it's inappropriate for me to ask the question, please let me know in the comments, and stackoverflow will automatically flood my inbox with sadface emoticons. If I haven't been specific enough, please let me know and I'll do my best to be clearer.
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!




发布评论
评论(3)
让它变得“长”:
下一步做什么将取决于您想要进行的分析类型。但长格式对于像您这样的不规则数据很有用。
Make it "long":
What to do next will depend on the kind of analysis you would like to do. But the long format is the useful for irregular data such as yours.
如果您想考虑不同的原因,您应该使用 plyr 中的 ddply 并在所有列上拆分,如果您想忽略它们,请不要在拆分中使用这些列。不过,您需要先清理一些问号和额外的东西。
you should use ddply from plyr and split on all of the columns if you want to take into account the different reasons, if you want to ignore them don't use those columns in the split. You'll need to clean up some of the question marks and extra stuff first though.
您试图回答的(更大的)问题是什么?为什么您对这些信息感兴趣?
您是否只是想找到诸如“如果学生这样做,那么他们也可能这样做”之类的模式?
如果是这种情况,我会考虑将数据集分成较小的随机样本进行分析,以减少误报的风险。
不过有趣的问题!
What's the (bigger picture) question you're attempting to answer? Why is this information interesting to you?
Are you just trying to find patterns such as 'if the student does this, then they also likely do this'?
Something I'd consider if that's the case - split the data set into smaller random samples for your analysis to reduce the risk of false positives.
Interesting problem though!