优化下一个和上一个元素的查询
我正在寻找在不运行完整查询的情况下检索记录的下一条和上一条记录的最佳方法。我已经有了一个完全实施的解决方案,并且想知道是否有更好的方法来做到这一点。
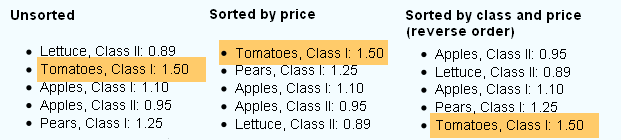
假设我们正在为一个虚构的蔬菜水果商构建一个网站。除了 HTML 页面之外,他每周还想在他的网站上发布特价商品列表。他希望这些优惠驻留在实际的数据库表中,并且用户必须能够通过三种方式对优惠进行排序。
每个项目还必须有一个详细信息页面,其中包含有关报价的更多文本信息以及“上一个”和“下一个”按钮。 “上一个”和“下一个”按钮需要指向相邻条目取决于用户为列表选择的排序。
(来源:pekkagaiser.com)
显然,在第一个示例中,“西红柿,I 类”的“下一个”按钮必须是“苹果,1 类”,在第二个示例中必须是“梨,I 类”,而在第三个示例中则没有。
详细信息视图中的任务是确定下一个和上一个项目,而不是每次都运行查询,将列表的排序顺序作为唯一可用的信息(假设我们通过 GET 参数获取该信息) ?sort=offeroftheweek_price,并忽略安全隐患)。
显然,简单地将下一个和上一个元素的 ID 作为参数传递是我想到的第一个解决方案。毕竟,此时我们已经知道了 ID。但是,这不是这里的一个选项 - 它可以在这个简化的示例中工作,但不适用于我的许多现实世界用例。
我当前在 CMS 中的方法是使用我命名为“排序缓存”的方法。加载列表后,我将项目位置存储在名为 sortingcache 的表中的记录中。
name (VARCHAR) items (TEXT)
offeroftheweek_unsorted Lettuce; Tomatoes; Apples I; Apples II; Pears
offeroftheweek_price Tomatoes;Pears;Apples I; Apples II; Lettuce
offeroftheweek_class_asc Apples II;Lettuce;Apples;Pears;Tomatoes
显然,items 列实际上填充了数字 ID。
在详细信息页面中,我现在访问相应的 sortingcache 记录,获取 items 列,展开它,搜索当前项目 ID,并返回上一个和下一个邻居。
array("current" => "Tomatoes",
"next" => "Pears",
"previous" => null
);
这显然很昂贵,仅适用于有限数量的记录并创建冗余数据,但我们假设在现实世界中,创建列表的查询非常昂贵(确实如此),在每个详细视图中运行它是不可能的问题,并且需要一些缓存。
我的问题:
您认为这是找出不同查询顺序的相邻记录的好做法吗?
您知道在性能和简单性方面更好的做法吗?你知道有什么东西可以让这个完全过时吗?
在编程理论中,这个问题有一个名称吗?
“排序缓存”这个名称对于这项技术来说是否合适且可以理解?
是否有任何公认的常见模式可以解决此问题?它们叫什么?
注意:我的问题不是关于构建列表或如何显示详细视图。这些只是例子。我的问题是当无法重新查询时确定记录的邻居的基本功能,以及实现该目标的最快且最便宜的方法。
如果有不清楚的地方,请发表评论,我会澄清。
开始赏金 - 也许有更多关于此的信息。
I am looking for the best way to retrieve the next and previous records of a record without running a full query. I have a fully implemented solution in place, and would like to know whether there are any better approaches to do this out there.
Let's say we are building a web site for a fictitious greengrocer. In addition to his HTML pages, every week, he wants to publish a list of special offers on his site. He wants those offers to reside in an actual database table, and users have to be able to sort the offers in three ways.
Every item also has to have a detail page with more, textual information on the offer and "previous" and "next" buttons. The "previous" and "next" buttons need to point to the neighboring entries depending on the sorting the user had chosen for the list.
(source: pekkagaiser.com)
Obviously, the "next" button for "Tomatoes, Class I" has to be "Apples, class 1" in the first example, "Pears, class I" in the second, and none in the third.
The task in the detail view is to determine the next and previous items without running a query every time, with the sort order of the list as the only available information (Let's say we get that through a GET parameter ?sort=offeroftheweek_price, and ignore the security implications).
Obviously, simply passing the IDs of the next and previous elements as a parameter is the first solution that comes to mind. After all, we already know the ID's at this point. But, this is not an option here - it would work in this simplified example, but not in many of my real world use cases.
My current approach in my CMS is using something I have named "sorting cache". When a list is loaded, I store the item positions in records in a table named sortingcache.
name (VARCHAR) items (TEXT)
offeroftheweek_unsorted Lettuce; Tomatoes; Apples I; Apples II; Pears
offeroftheweek_price Tomatoes;Pears;Apples I; Apples II; Lettuce
offeroftheweek_class_asc Apples II;Lettuce;Apples;Pears;Tomatoes
obviously, the items column is really populated with numeric IDs.
In the detail page, I now access the appropriate sortingcache record, fetch the items column, explode it, search for the current item ID, and return the previous and next neighbour.
array("current" => "Tomatoes",
"next" => "Pears",
"previous" => null
);
This is obviously expensive, works for a limited number of records only and creates redundant data, but let's assume that in the real world, the query to create the lists is very expensive (it is), running it in every detail view is out of the question, and some caching is needed.
My questions:
Do you think this is a good practice to find out the neighbouring records for varying query orders?
Do you know better practices in terms of performance and simplicity? Do you know something that makes this completely obsolete?
In programming theory, is there a name for this problem?
Is the name "Sorting cache" is appropriate and understandable for this technique?
Are there any recognized, common patterns to solve this problem? What are they called?
Note: My question is not about building the list, or how to display the detail view. Those are just examples. My question is the basic functionality of determining the neighbors of a record when a re-query is impossible, and the fastest and cheapest way to get there.
If something is unclear, please leave a comment and I will clarify.
Starting a bounty - maybe there is some more info on this out there.
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!






{kind=link}
发布评论
评论(11)
我也曾因这个而做过噩梦。即使对于 10k 项的列表,您当前的方法似乎也是最佳解决方案。在 http 会话中缓存列表视图的 ID,然后使用它来显示(针对当前用户个性化的)上一个/下一个。这很有效,尤其是当有太多方法可以过滤和排序初始项目列表而不仅仅是 3 种时。
此外,通过存储整个 ID 列表,您可以显示
“you are at X out of Y”可用性增强文本。顺便说一下,这就是 JIRA 也是如此。
直接回答您的问题:
I've had nightmares with this one as well. Your current approach seems to be the best solution even for lists of 10k items. Caching the IDs of the list view in the http session and then using that for displaying the (personalized to current user) previous/next. This works well especially when there are too many ways to filter and sort the initial list of items instead of just 3.

Also, by storing the whole IDs list you get to display a
"you are at X out of Y"usability enhancing text.By the way, this is what JIRA does as well.
To directly answer your questions:
一般来说,我对索引中的数据进行非规范化。它们可能存储在同一行中,但我几乎总是检索结果 ID,然后对数据进行单独的旅行。这使得缓存数据变得非常简单。在延迟低且带宽高的 PHP 中,这一点并不那么重要,但当您拥有高延迟、低带宽的应用程序(例如 AJAX 网站,其中大部分网站是用 JavaScript 呈现的)时,这种策略非常有用。
我总是单独缓存结果列表和结果本身。如果有任何因素影响列表查询的结果,则会刷新列表结果的缓存。如果有任何因素影响结果本身,则会刷新这些特定结果。这使我可以更新其中任何一个,而无需重新生成所有内容,从而实现有效的缓存。
由于我的结果列表很少改变,因此我同时生成所有列表。这可能会使初始响应稍微慢一些,但它简化了缓存刷新(所有列表都存储在单个缓存条目中)。
因为我缓存了整个列表,所以无需重新访问数据库即可轻松查找相邻项目。幸运的是,这些项目的数据也将被缓存。在 JavaScript 中对数据进行排序时,这尤其方便。如果我已经在客户端缓存了一份副本,我可以立即使用。
具体回答您的问题:
另外,当您缓存内容时,请尽可能以最通用的级别缓存它们。有些内容可能是特定于用户的(例如搜索查询的结果),而其他内容可能与用户无关,例如浏览目录。两者都可以从缓存中受益。目录查询可能很频繁,每次都会节省一点,而搜索查询可能会很昂贵,几次就会节省很多。
In general, I denormalize the data from the indexes. They may be stored in the same rows, but I almost always retrieve my result IDs, then make a separate trip for the data. This makes caching the data very simple. It's not so important in PHP where the latency is low and the bandwidth high, but such a strategy is very useful when you have a high latency, low bandwidth application, such as an AJAX website where much of the site is rendered in JavaScript.
I always cache the lists of results, and the results themselves separately. If anything affects the results of a list query, the cache of the list results is refreshed. If anything affects the results themselves, those particular results are refreshed. This allows me to update either one without having to regenerate everything, resulting in effective caching.
Since my lists of results rarely change, I generate all the lists at the same time. This may make the initial response slightly slower, but it simplifies cache refreshing (all the lists get stored in a single cache entry).
Because I have the entire list cached, it's trivial to find neighbouring items without revisiting the database. With luck, the data for those items will also be cached. This is especially handy when sorting data in JavaScript. If I already have a copy cached on the client, I can resort instantly.
To answer your questions specifically:
Also, when you cache things, cache them at the most generic level possible. Some stuff might be user specific (such as results for a search query), where others might be user agnostic, such as browsing a catalog. Both can benefit from caching. The catalog query might be frequent and save a little each time, and the search query may be expensive and save a lot a few times.
我不确定我是否理解正确,所以如果没有,请告诉我;)
假设给定的是排序列表的查询和该列表中的当前偏移量,即我们有一个
$query< /code> 和$n。最小化查询的一个非常明显的解决方案是一次获取所有数据:
该语句按当前排序顺序从数据库中获取上一个、当前和下一个元素,并将相关信息放入相应的变量中。
但由于这个解决方案太简单了,我想我误解了一些东西。
I'm not sure whether I understood right, so if not, just tell me ;)
Let's say, that the givens are the query for the sorted list and the current offset in that list, i.e. we have a
$queryand an$n.A very obvious solution to minimize the queries, would be to fetch all the data at once:
That statement fetches the previous, the current and the next elements from the database in the current sorting order and puts the associated information into the corresponding variables.
But as this solution is too simple, I assume I misunderstood something.
做到这一点的方法有很多,就像众所周知的剥猫皮一样。这是我的一些。
如果您的原始查询很昂贵(正如您所说的那样),那么创建另一个表(可能是内存表),用您昂贵且很少运行的主查询的结果填充它。
然后可以在每个视图上查询第二个表,并且排序就像设置适当的排序顺序一样简单。
根据需要,使用第一个表的结果重新填充第二个表,从而保持数据最新,但最大限度地减少昂贵查询的使用。
或者,如果您想避免连接到数据库,那么您可以将所有数据存储在 php 数组中并使用 memcached 存储它。这将非常快,并且只要您的列表不是太大,就会节省资源。并且可以轻松排序。
直流
There are as many ways to do this as to skin the proverbial cat. So here are a couple of mine.
If your original query is expensive, which you say it is, then create another table possibly a memory table populating it with the results of your expensive and seldom run main query.
This second table could then be queried on every view and the sorting is as simple as setting the appropriate sort order.
As is required repopulate the second table with results from the first table, thus keeping the data fresh, but minimising the use of the expensive query.
Alternately, If you want to avoid even connecting to the db then you could store all the data in a php array and store it using memcached. this would be very fast and provided your lists weren't too huge would be resource efficient. and can be easily sorted.
DC
基本假设:
如果站点每天都在变化,我建议所有页面都在一夜之间静态生成。对每个排序顺序的一个查询会迭代并生成所有相关页面。即使存在动态元素,您也有可能通过包含静态页面元素来解决它们。这将提供最佳的页面服务并且没有数据库负载。事实上,您可能会生成单独的页面和包含在页面中的上一个/下一个元素。有 200 种排序方式可能会更疯狂,但有 3 种排序方式我是它的忠实粉丝。
如果由于某种原因这不可行,我会求助于记忆。 Memcache 在这类事情上很受欢迎(双关语!)。当某些内容被推送到数据库时,您可以发出触发器以使用正确的值更新缓存。执行此操作的方式与您的更新项目存在于 3 个链接列表中的方式相同 - 根据需要重新链接(this.next.prev = this.prev 等)。由此,只要您的缓存没有溢出,您就可以以主键方式从内存中提取简单值。
此方法将在选择和更新/插入方法上进行一些额外的编码,但应该相当少。最后,您将查找
[1 类西红柿的 id].price.next。如果该密钥在您的缓存中,那就太好了。如果没有,则插入缓存并显示。抱歉,我的拖尾答案有点无用,但我认为我的叙事解决方案应该非常有用。
Basic assumptions:
If the site changes on a daily basis, I suggest that all the pages are statically generated overnight. One query for each sort-order iterates through and makes all the related pages. Even if there are dynamic elements, odds are that you can address them by including the static page elements. This would provide optimal page service and no database load. In fact, you could possibly generate separate pages and prev / next elements that are included into the pages. This may be crazier with 200 ways to sort, but with 3 I'm a big fan of it.
If for some reason this isn't feasible, I'd resort to memorization. Memcache is popular for this sort of thing (pun!). When something is pushed to the database, you can issue a trigger to update your cache with the correct values. Do this in the same way you would if as if your updated item existed in 3 linked lists -- relink as appropriate (this.next.prev = this.prev, etc). From that, as long as your cache doesn't overfill, you'll be pulling simple values from memory in a primary key fashion.
This method will take some extra coding on the select and update / insert methods, but it should be fairly minimal. In the end, you'll be looking up
[id of tomatoes class 1].price.next. If that key is in your cache, golden. If not, insert into cache and display.Sorry my tailing answers are kind of useless, but I think my narrative solutions should be quite useful.
您可以将排序列表的行号保存到视图,您可以访问 (current_rownum-1) 和 (current_rownum+1) 下列表中的上一项和下一项) 行号。
You could save the row numbers of the ordered lists into views, and you could reach the previous and next items in the list under (current_rownum-1) and (current_rownum+1) row numbers.
问题/数据结构被命名为双向图,或者你可以说你有几个链接列表。
如果您将其视为链接列表,则只需为每个排序和上一个/下一个键向项目表添加字段即可。但 DB 人员会为此杀了你,就像 GOTO 一样。
如果您将其视为(双向)图,您就会同意杰西卡的答案。主要问题是订单更新是昂贵的操作。
如果将一项位置更改为新顺序 A、C、B、D,则必须更新 4 行。
The problem / datastructur is named bi-directional graph or you could say you've got several linked lists.
If you think of it as a linked list, you could just add fields to the items table for every sorting and prev / next key. But the DB Person will kill you for that, it's like GOTO.
If you think of it as a (bi-)directional graph, you go with Jessica's answer. The main problem there is that order updates are expensive operations.
If you change one items position to the new order A, C, B, D, you will have to update 4 rows.
如果我误解了,请道歉,但我认为您想保留用户访问服务器之间的有序列表。如果是这样,您的答案很可能在于您的缓存策略和技术,而不是数据库查询/模式优化。
我的方法是在第一次检索数组后对其进行序列化(),然后将其缓存到单独的存储区域中;无论是 memcached/ APC/ 硬盘驱动器/ mongoDb/ 等,并通过会话数据单独为每个用户保留其缓存位置详细信息。实际的存储后端自然取决于阵列的大小,您无需详细了解该大小,但 memcached 在多个服务器上可以很好地扩展,而 mongo 甚至可以以稍大的延迟成本进行扩展。
您也没有指出现实世界中有多少种排序排列;例如,您是否需要为每个用户缓存单独的列表,或者您可以全局缓存每个排序排列,然后通过 PHP 过滤掉您不需要的内容吗?在您给出的示例中,我只是缓存这两个排列,并将需要 unserialize() 的两个排列存储在会话数据中。
当用户返回站点时,检查缓存数据的生存时间值,如果仍然有效则重新使用它。我还会在 INSERT/UPDATE/DELETE 上运行一个触发器,用于特殊优惠,只需在单独的表中设置时间戳字段。这将立即表明缓存是否已过时,并且需要以非常低的查询成本重新运行查询。仅使用触发器设置单个字段的好处是无需担心从该表中删除旧的/冗余的值。
这是否合适取决于返回数据的大小、修改的频率以及服务器上可用的缓存技术。
Apologies if I have misunderstood, but I think you want to retain the ordered list between user accesses to the server. If so, your answer may well lie in your caching strategy and technologies rather than in database query/ schema optimization.
My approach would be to serialize() the array once its first retrieved, and then cache that in to a separate storage area; whether that's memcached/ APC/ hard-drive/ mongoDb/ etc. and retain its cache location details for each user individually through their session data. The actual storage backend would naturally be dependent upon the size of the array, which you don't go into much detail about, but memcached scales great over multiple servers and mongo even further at a slightly greater latency cost.
You also don't indicate how many sort permutations there are in the real-world; e.g. do you need to cache separate lists per user, or can you globally cache per sort permutation and then filter out what you don't need via PHP?. In the example you give, I'd simply cache both permutations and store which of the two I needed to unserialize() in the session data.
When the user returns to the site, check the Time To Live value of the cached data and re-use it if still valid. I'd also have a trigger running on INSERT/ UPDATE/ DELETE for the special offers that simply sets a timestamp field in a separate table. This would immediately indicate whether the cache was stale and the query needed to be re-run for a very low query cost. The great thing about only using the trigger to set a single field is that there's no need to worry about pruning old/ redundant values out of that table.
Whether this is suitable would depend upon the size of the data being returned, how frequently it was modified, and what caching technologies are available on your server.
因此,您有两个任务:
问题是什么?
PS:如果有序列表可能太大,您只需要实现 PAGER 功能。可能有不同的实现,例如您可能希望将“LIMIT 5”添加到查询中并提供“Show next 5”按钮。当按下此按钮时,会添加“WHERE 价格<0.89 LIMIT 5”等条件。
So you have two tasks:
What is the problem?
PS: if ordered list may be too big you just need PAGER functionality implemented. There could be different implementations, e.g. you may wish to add "LIMIT 5" into query and provide "Show next 5" button. When this button is pressed, condition like "WHERE price < 0.89 LIMIT 5" is added.
这是一个想法。当杂货商插入/更新新报价时,而不是当最终用户选择要查看的数据时,您可以将昂贵的操作转移到更新。这看起来像是处理排序数据的非动态方式,但它可能会提高速度。而且,正如我们所知,性能和其他编码因素之间总是需要权衡。
创建一个表来保存每个报价和每个排序选项的下一个和上一个。 (或者,如果您始终具有三个排序选项,则可以将其存储在报价表中 - 查询速度是非规范化数据库的一个很好的理由)
因此您将拥有以下列:
当从数据库查询商品详细信息页面的详细信息时,NextID 和 PrevID 将成为结果的一部分。因此,每个详细信息页面只需要一个查询。
每次插入、更新或删除报价时,您都需要运行一个过程来验证排序类型表的完整性/准确性。
Here is an idea. You could offload the expensive operations to an update when the grocer inserts/updates new offers rather than when the end user selects the data to view. This may seem like a non-dynamic way to handle the sort data, but it may increase speed. And, as we know, there is always a trade off between performance and other coding factors.
Create a table to hold next and previous for each offer and each sort option. (Alternatively, you could store this in the offer table if you will always have three sort options -- query speed is a good reason to denormalize your database)
So you would have these columns:
When the detail information for the offer detail page is queried from the database, the NextID and PrevID would be part of the results. So you would only need one query for each detail page.
Each time an offer is inserted, updated or deleted, you would need to run a process which validates the integrity/accuracy of the sorttype table.
我的想法与杰西卡的有些相似。但是,您不是存储下一个和上一个排序项的链接,而是存储每种排序类型的排序顺序。要查找上一条或下一条记录,只需获取 SortX=currentSort++ 或 SortX=currentSort-- 的行。
示例:
此解决方案的查询时间非常短,并且占用的磁盘空间比杰西卡的想法更少。但是,我相信您已经意识到,更新一行数据的成本明显更高,因为您必须重新计算和存储所有排序顺序。但是,根据您的情况,如果数据更新很少,特别是如果它们总是批量发生,那么此解决方案可能是最好的。
即
希望这有用。
I have an idea somewhat similar to Jessica's. However, instead of storing links to the next and previous sort items, you store the sort order for each sort type. To find the previous or next record, just get the row with SortX=currentSort++ or SortX=currentSort--.
Example:
This solution would yield very short query times, and would take up less disk space than Jessica's idea. However, as I'm sure you realize, the cost of updating one row of data is notably higher, since you have to recalculate and store all sort orders. But still, depending on your situation, if data updates are rare and especially if they always happen in bulk, then this solution might be the best.
i.e.
Hope this is useful.