如何截断 grep 或 ack 返回的长匹配行
我想对通常有很长行的 HTML 文件运行 ack 或 grep。我不想看到很长的线反复换行。但我确实想查看包围与正则表达式匹配的字符串的长行的一部分。我怎样才能使用 Unix 工具的任意组合来获得这个?
I want to run ack or grep on HTML files that often have very long lines. I don't want to see very long lines that wrap repeatedly. But I do want to see just that portion of a long line that surrounds a string that matches the regular expression. How can I get this using any combination of Unix tools?
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!





发布评论
评论(11)
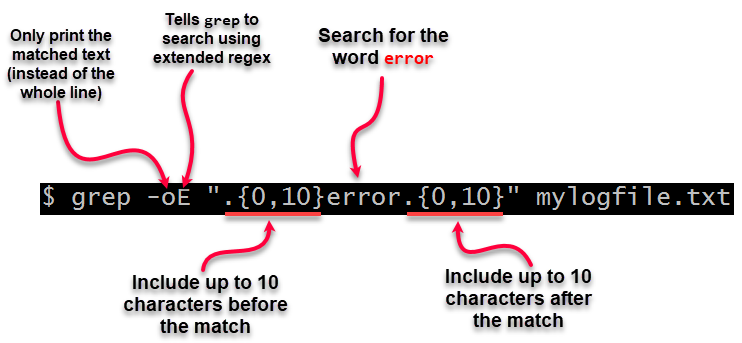
您可以使用 grep 选项
-oE,可能与将模式更改为".{0,10}.{0,10}" 结合使用为了查看周围的一些上下文:-o, --only-matching Show only the part of a matching line that matches PATTERN. -E, --extended-regexp Interpret pattern as an extended regular expression (i.e., force grep to behave as egrep).例如(来自@Renaud的评论):
或者,您可以尝试
-c:-c, --count Suppress normal output; instead print a count of matching lines for each input file. With the -v, --invert-match option (see below), count non-matching lines.You could use the grep options
-oE, possibly in combination with changing your pattern to".{0,10}<original pattern>.{0,10}"in order to see some context around it:-o, --only-matching Show only the part of a matching line that matches PATTERN. -E, --extended-regexp Interpret pattern as an extended regular expression (i.e., force grep to behave as egrep).For example (from @Renaud's comment):
Alternatively, you could try
-c:-c, --count Suppress normal output; instead print a count of matching lines for each input file. With the -v, --invert-match option (see below), count non-matching lines.通过
cut传送结果。我还在考虑添加一个--cut开关,这样你就可以说--cut=80并且只获得 80 列。Pipe your results thru
cut. I'm also considering adding a--cutswitch so you could say--cut=80and only get 80 columns.您可以使用 less 作为寻呼机来进行 ack 和截断长行:
ack --pager="less -S"这会保留长行,但将其保留在一行上而不是换行。要查看该行的更多内容,请使用箭头键向左/向右滚动。我有以下别名设置来执行此操作:
You could use less as a pager for ack and chop long lines:
ack --pager="less -S"This retains the long line but leaves it on one line instead of wrapping. To see more of the line, scroll left/right in less with the arrow keys.I have the following alias setup for ack to do this:
grep -oE ".{0,10}error.{0,10}" mylogfile.txt在无法使用
-E的异常情况下,请使用小写-e代替。说明:
grep -oE ".{0,10}error.{0,10}" mylogfile.txtIn the unusual situation where you cannot use
-E, use lowercase-einstead.Explanation:
要获取从 1 到 100 的字符。
您可能希望将范围基于当前终端,例如
To get characters from 1 to 100.
You might want to base the range off the current terminal, e.g.
我将以下内容放入
.bashrc中:然后,您可以在命令行上使用
grepl以及可用于grep的任何参数。使用箭头键查看较长线条的尾部。使用q退出。说明:
grepl() {:定义一个新函数,该函数将在每个(新)bash 控制台中可用。$(which grep):获取grep的完整路径。 (Ubuntu 为grep定义了一个别名,它相当于grep --color=auto。我们不需要那个别名,而是原来的grep.)--color=always:对输出进行着色。 (别名中的--color=auto不起作用,因为grep检测到输出被放入管道中,然后不会对其进行着色。)$@:将提供给grepl函数的所有参数放在这里。less:使用less显示行-R:显示颜色S:不要打断长行I put the following into my
.bashrc:You can then use
greplon the command line with any arguments that are available forgrep. Use the arrow keys to see the tail of longer lines. Useqto quit.Explanation:
grepl() {: Define a new function that will be available in every (new) bash console.$(which grep): Get the full path ofgrep. (Ubuntu defines an alias forgrepthat is equivalent togrep --color=auto. We don't want that alias but the originalgrep.)--color=always: Colorize the output. (--color=autofrom the alias won't work sincegrepdetects that the output is put into a pipe and won't color it then.)$@: Put all arguments given to thegreplfunction here.less: Display the lines usingless-R: Show colorsS: Don't break long lines摘自:http://www.topbug.net/blog/2016/08/18/truncate-long-matching-lines-of-grep-a-solution-that-preserves-color/
建议的方法
".{0,10}.{0,10}" 非常好,只是突出显示的颜色经常混乱。我创建了一个具有类似输出的脚本,但颜色也被保留:假设脚本保存为
grepl,则grepl 模式 file_with_long_lines应该显示匹配的行,但带有匹配字符串周围只有 10 个字符。Taken from: http://www.topbug.net/blog/2016/08/18/truncate-long-matching-lines-of-grep-a-solution-that-preserves-color/
The suggested approach
".{0,10}<original pattern>.{0,10}"is perfectly good except for that the highlighting color is often messed up. I've created a script with a similar output but the color is also preserved:Assuming the script is saved as
grepl, thengrepl pattern file_with_long_linesshould display the matching lines but with only 10 characters around the matching string.Silver Searcher (ag) 通过
--width NUM原生支持选项。它将用[...]替换其余较长的行。示例(在 120 个字符后截断):
在 ack3 中,计划有一个类似功能,但目前没有实施。
The Silver Searcher (ag) supports its natively via the
--width NUMoption. It will replace the rest of longer lines by[...].Example (truncate after 120 characters):
In ack3, a similar feature is planned but currently not implemented.
这就是我所做的:
在我的 .bash_profile 中,我覆盖 grep,以便它自动运行
tput rmam之前和tput smam之后,禁用换行,然后重新启用它。Here's what I do:
In my .bash_profile, I override grep so that it automatically runs
tput rmambefore andtput smamafter, which disabled wrapping and then re-enables it.如果您愿意,
ag也可以采用正则表达式技巧:agcan also take the regex trick, if you prefer it:bgrep如果行不一定适合内存grep仅当行适合内存时才有效,但 bgrep 也适用于不适合内存的大行't。我时不时地回到这个随机仓库: https://github.com/tmbinc/bgrep 安装:
使用:
示例输出:
我已经在不适合内存的文件上对其进行了测试,并且效果很好。
我在以下位置提供了更多详细信息:https: //unix.stackexchange.com/questions/223078/best-way-grep-a-big-binary-file/758528#758528
bgrepif lines don't necessarily fit into memorygreponly works if the lines fit into memory, but bgrep also works on huge lines that don't.I keep coming back to this random repo from time to time: https://github.com/tmbinc/bgrep Install:
Use:
Sample output:
I have tested it on files that don't fit into memory, and it worked just fine.
I've given further details at: https://unix.stackexchange.com/questions/223078/best-way-to-grep-a-big-binary-file/758528#758528