将 PostgreSQL 的 PL/pgSQL 输出保存到 CSV 文件
将 PL/pgSQL 输出从 PostgreSQL 数据库保存到 CSV 文件的最简单方法是什么?
我正在使用带有 pgAdmin III 的 PostgreSQL 8.4 和运行查询的 PSQL 插件。
What is the easiest way to save PL/pgSQL output from a PostgreSQL database to a CSV file?
I'm using PostgreSQL 8.4 with pgAdmin III and PSQL plugin where I run queries from.
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!





发布评论
评论(21)
JackDB(网络浏览器中的数据库客户端)使这一切变得非常简单。特别是如果您使用 Heroku。
它允许您连接到远程数据库并对其运行 SQL 查询。
sp; sp; sp; sp; sp; sp; 来源
(来源:jackdb.com)
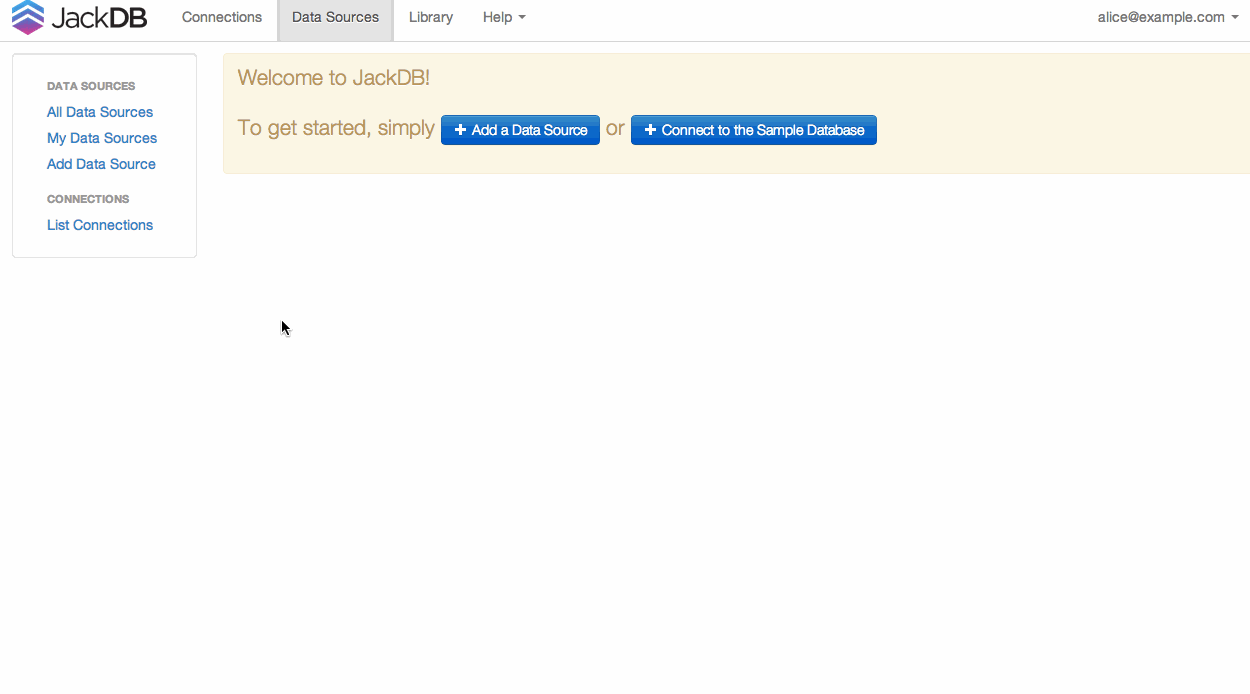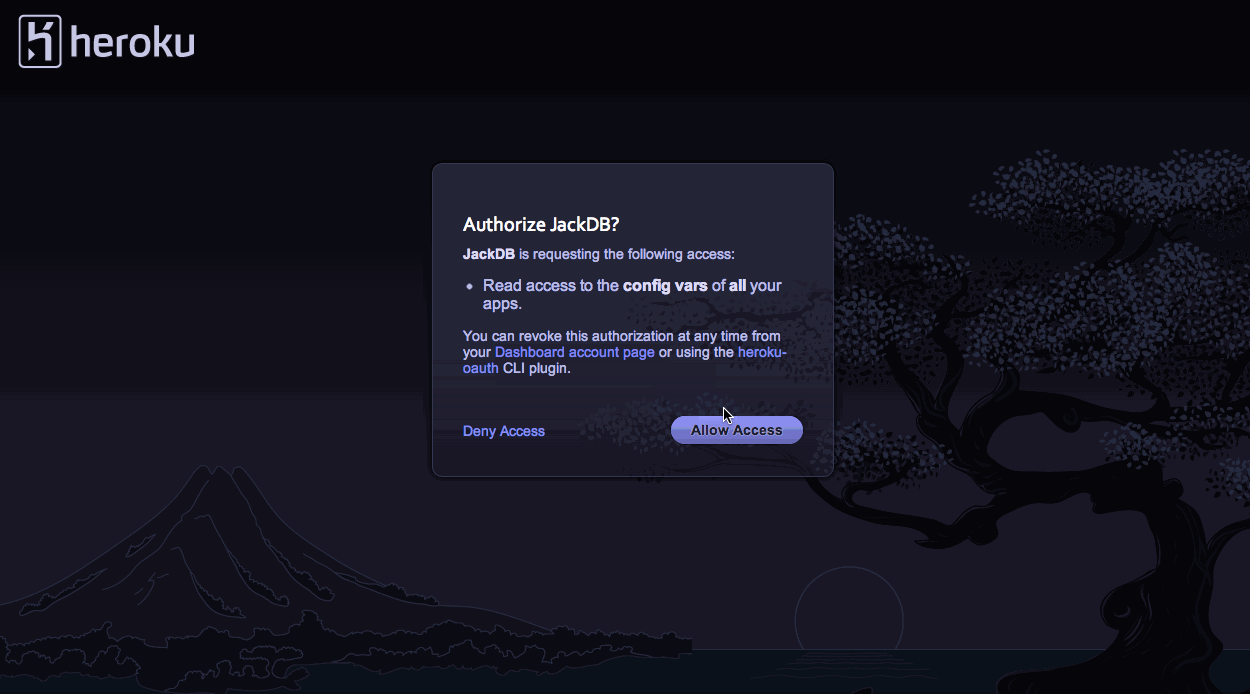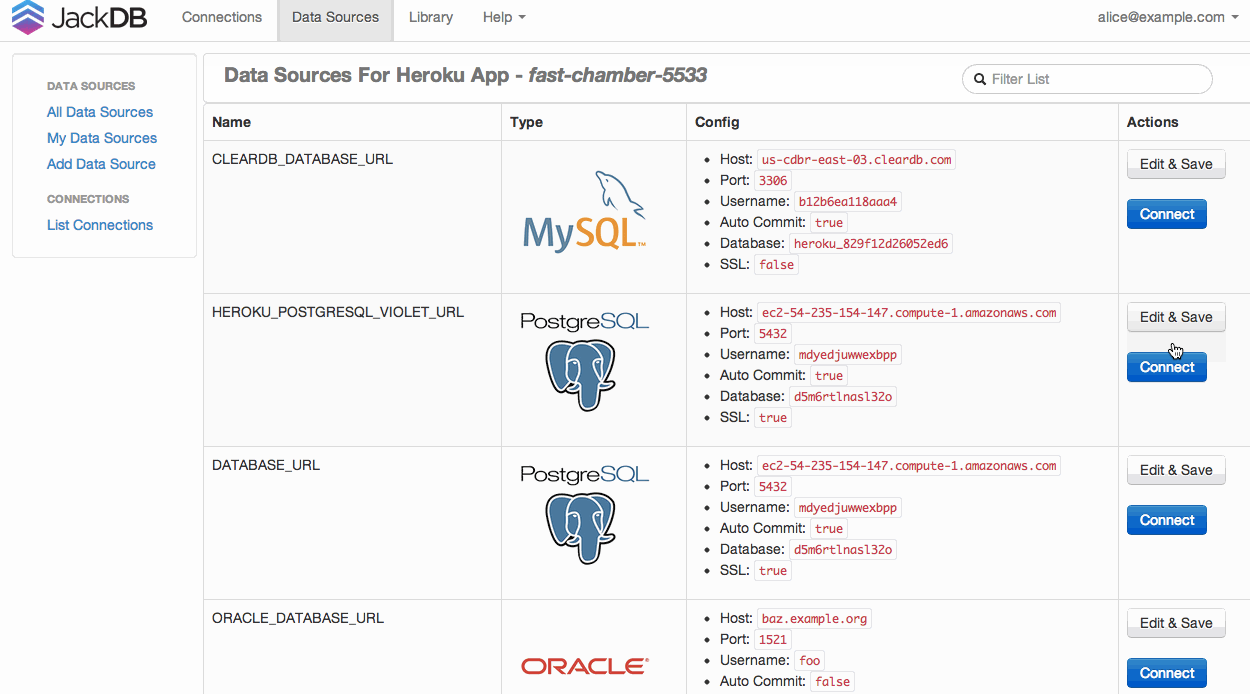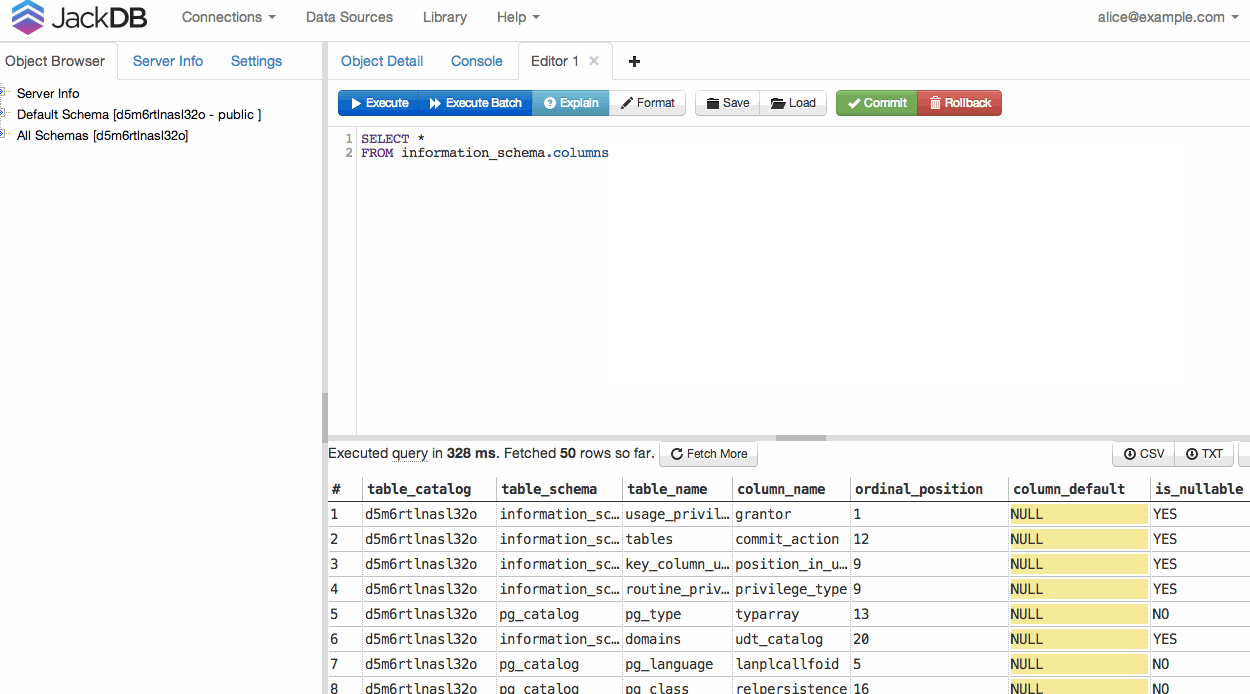
连接数据库后,您可以运行查询并导出到 CSV 或 TXT(请参见右下角)。
注意: 我与 JackDB 没有任何关系。我目前使用他们的免费服务,并认为这是一个很棒的产品。
JackDB, a database client in your web browser, makes this really easy. Especially if you're on Heroku.
It lets you connect to remote databases and run SQL queries on them.
Source

(source: jackdb.com)
Once your DB is connected, you can run a query and export to CSV or TXT (see bottom right).
Note: I'm in no way affiliated with JackDB. I currently use their free services and think it's a great product.
根据 @skeller88 的要求,我将我的评论重新发布为答案,这样那些没有阅读每条回复的人就不会迷失它......
DataGrip 的问题在于它会控制你的钱包。它不是免费的。请尝试 dbeaver.io 上的 DBeaver 社区版。它是一款面向 SQL 程序员、DBA 和分析师的 FOSS 多平台数据库工具,支持所有流行的数据库:MySQL、PostgreSQL、SQLite、Oracle、DB2、SQL Server、Sybase、MS Access、Teradata、Firebird、Hive、Presto 等。
DBeaver 社区版使得连接数据库、发出查询来检索数据,然后下载结果集以将其保存为 CSV、JSON、SQL 或其他常见数据格式变得非常简单。它是 TOAD for Postgres、TOAD for SQL Server 或 Toad for Oracle 的可行的 FOSS 竞争对手。
我与 DBeaver 没有任何关系。我喜欢它的价格和功能,但我希望他们能够更多地开放 DBeaver/Eclipse 应用程序,并使向 DBeaver/Eclipse 添加分析小部件变得容易,而不是要求用户支付年度订阅费用来直接在其中创建图形和图表该应用程序。我的 Java 编码技能已经生疏,我不想花几周时间重新学习如何构建 Eclipse 小部件,却发现 DBeaver 已经禁用了向 DBeaver 社区版添加第三方小部件的功能。
DBeaver 用户是否了解创建分析小部件以添加到 DBeaver 社区版中的步骤?
Per the request of @skeller88, I am reposting my comment as an answer so that it doesn't get lost by people who don't read every response...
The problem with DataGrip is that it puts a grip on your wallet. It is not free. Try the community edition of DBeaver at dbeaver.io. It is a FOSS multi-platform database tool for SQL programmers, DBAs and analysts that supports all popular databases: MySQL, PostgreSQL, SQLite, Oracle, DB2, SQL Server, Sybase, MS Access, Teradata, Firebird, Hive, Presto, etc.
DBeaver Community Edition makes it trivial to connect to a database, issue queries to retrieve data, and then download the result set to save it to CSV, JSON, SQL, or other common data formats. It's a viable FOSS competitor to TOAD for Postgres, TOAD for SQL Server, or Toad for Oracle.
I have no affiliation with DBeaver. I love the price and functionality, but I wish they would open up the DBeaver/Eclipse application more and made it easy to add analytics widgets to DBeaver / Eclipse, rather than requiring users to pay for the annual subscription to create graphs and charts directly within the application. My Java coding skills are rusty and I don't feel like taking weeks to relearn how to build Eclipse widgets, only to find that DBeaver has disabled the ability to add third-party widgets to the DBeaver Community Edition.
Do DBeaver users have insight as to the steps to create analytics widgets to add into the Community Edition of DBeaver?
您想要将生成的文件放在服务器上还是客户端上?
服务器端
如果你想要一些易于重用或自动化的东西,你可以使用 Postgresql 的内置 复制 命令。例如
这种方法完全在远程服务器上运行 - 它无法写入您的本地PC。它还需要作为 Postgres“超级用户”(通常称为“root”)运行,因为 Postgres 无法阻止它对该计算机的本地文件系统做一些令人讨厌的事情。
这实际上并不意味着您必须作为超级用户进行连接(自动化这将带来另一种安全风险),因为您可以使用
CREATE FUNCTION的SECURITY DEFINER选项,以创建一个运行的函数尽管您是超级用户。关键的部分是你的函数是用来执行额外的检查,而不仅仅是绕过安全性 - 因此你可以编写一个导出你需要的确切数据的函数,或者你可以编写一些可以接受各种选项的东西,只要它们满足严格的白名单。您需要检查两件事:
我已经编写了 扩展此方法的博客文章,包括导出(或导入)满足严格条件的文件和表的函数的一些示例。
客户端
另一种方法是在客户端进行文件处理,即在您的应用程序或脚本中。 Postgres 服务器不需要知道您要复制到哪个文件,它只是吐出数据,然后客户端将其放在某个地方。
其底层语法是 COPY TO STDOUT 命令,像 pgAdmin 这样的图形工具会在一个漂亮的对话框中为您包装它。
psql命令行客户端有一个特殊的“元命令”,称为\copy,它接受所有与“真实”COPY 相同的选项,但在客户端内部运行:请注意,没有终止
;,因为元命令由换行符终止,与 SQL 命令不同。来自文档 :
您的应用程序编程语言可能也支持推送或获取数据,但您通常不能在标准中使用
COPY FROM STDIN/TO STDOUTSQL语句,因为没有办法连接输入/输出流。 PHP 的 PostgreSQL 处理程序(不是 PDO)包括非常基本的pg_copy_from和pg_copy_to函数,用于复制到 PHP 数组或从 PHP 数组复制,这对于大型数据集可能效率不高。Do you want the resulting file on the server, or on the client?
Server side
If you want something easy to re-use or automate, you can use Postgresql's built in COPY command. e.g.
This approach runs entirely on the remote server - it can't write to your local PC. It also needs to be run as a Postgres "superuser" (normally called "root") because Postgres can't stop it doing nasty things with that machine's local filesystem.
That doesn't actually mean you have to be connected as a superuser (automating that would be a security risk of a different kind), because you can use the
SECURITY DEFINERoption toCREATE FUNCTIONto make a function which runs as though you were a superuser.The crucial part is that your function is there to perform additional checks, not just by-pass the security - so you could write a function which exports the exact data you need, or you could write something which can accept various options as long as they meet a strict whitelist. You need to check two things:
GRANTs in the database, but the function is now running as a superuser, so tables which would normally be "out of bounds" will be fully accessible. You probably don’t want to let someone invoke your function and add rows on the end of your “users” table…I've written a blog post expanding on this approach, including some examples of functions that export (or import) files and tables meeting strict conditions.
Client side
The other approach is to do the file handling on the client side, i.e. in your application or script. The Postgres server doesn't need to know what file you're copying to, it just spits out the data and the client puts it somewhere.
The underlying syntax for this is the
COPY TO STDOUTcommand, and graphical tools like pgAdmin will wrap it for you in a nice dialog.The
psqlcommand-line client has a special "meta-command" called\copy, which takes all the same options as the "real"COPY, but is run inside the client:Note that there is no terminating
;, because meta-commands are terminated by newline, unlike SQL commands.From the docs:
Your application programming language may also have support for pushing or fetching the data, but you cannot generally use
COPY FROM STDIN/TO STDOUTwithin a standard SQL statement, because there is no way of connecting the input/output stream. PHP's PostgreSQL handler (not PDO) includes very basicpg_copy_fromandpg_copy_tofunctions which copy to/from a PHP array, which may not be efficient for large data sets.解决办法有以下几种:
1
psql命令psql -d dbname -t -A -F"," -c "select * from users" > output.csv这有一个很大的优点,您可以通过 SSH 使用它,例如
ssh postgres@host 命令- 使您能够获得2 个 postgres
copy命令< code>COPY (SELECT * from users) To '/tmp/output.csv' With CSV;
3 psql 交互式(或不)
所有这些都可以在脚本中使用,但我更喜欢#1。
4 pgadmin 但这不可编写脚本。
There are several solutions:
1
psqlcommandpsql -d dbname -t -A -F"," -c "select * from users" > output.csvThis has the big advantage that you can using it via SSH, like
ssh postgres@host command- enabling you to get2 postgres
copycommandCOPY (SELECT * from users) To '/tmp/output.csv' With CSV;3 psql interactive (or not)
All of them can be used in scripts, but I prefer #1.
4 pgadmin but that's not scriptable.
在终端(连接到数据库时)将输出设置为 cvs 文件
1) 将字段分隔符设置为
',':2) 设置输出格式不对齐:
3) 仅显示元组:
4) 设置输出:
5) 执行查询:
6) 输出:
然后您将能够在此位置找到您的 csv 文件:
使用
scp命令复制它或使用 nano 进行编辑:In terminal (while connected to the db) set output to the cvs file
1) Set field seperator to
',':2) Set output format unaligned:
3) Show only tuples:
4) Set output:
5) Execute your query:
6) Output:
You will then be able to find your csv file in this location:
Copy it using the
scpcommand or edit using nano:CSV 导出统一
此信息并未得到很好的体现。由于这是我第二次需要导出此内容,因此我会将其放在这里以提醒自己。
实际上,最好的方法(从 postgres 中获取 CSV)是使用 COPY ... TO STDOUT 命令。尽管您不想按照此处答案中所示的方式进行操作。正确的命令使用方法是:
只记住一个命令!
它非常适合在 ssh 上使用:
它非常适合在 docker 内部通过 ssh 使用:
它在本地计算机上甚至很棒:
或者在本地计算机上的 docker 内部?:
或者在 kubernetes 集群上,在 docker 中,通过 HTTPS??:
如此多才多艺,很多逗号!
你甚至吗?
是的,我做到了,这是我的注释:
使用
/copy的COPYses可以在运行
psql命令的任何系统上有效地执行文件操作,就像执行该命令的用户< a href="https://wiki.postgresql.org/wiki/COPY" rel="noreferrer">1。如果您连接到远程服务器,则可以轻松地将执行psql的系统上的数据文件复制到远程服务器或从远程服务器复制数据文件。COPY作为后端进程用户帐户(默认postgres)在服务器上执行文件操作,相应地检查并应用文件路径和权限。如果使用 TO STDOUT,则会绕过文件权限检查。如果
psql未在您希望生成的 CSV 最终驻留的系统上执行,则这两个选项都需要后续文件移动。根据我的经验,当您主要使用远程服务器时,这是最有可能的情况。通过 ssh 配置 TCP/IP 隧道到远程系统以进行简单的 CSV 输出更为复杂,但对于其他输出格式(二进制),最好通过隧道连接进行
/copy,执行本地psql。同样,对于大型导入,将源文件移动到服务器并使用 COPY 可能是性能最高的选项。PSQL 参数
使用 psql 参数,您可以像 CSV 一样格式化输出,但有一些缺点,例如必须记住禁用寻呼机并且无法获取标头:
其他工具
不,我只想从我的服务器中获取 CSV,而不需要编译和/或安装工具。
CSV Export Unification
This information isn't really well represented. As this is the second time I've needed to derive this, I'll put this here to remind myself if nothing else.
Really the best way to do this (get CSV out of postgres) is to use the
COPY ... TO STDOUTcommand. Though you don't want to do it the way shown in the answers here. The correct way to use the command is:Remember just one command!
It's great for use over ssh:
It's great for use inside docker over ssh:
It's even great on the local machine:
Or inside docker on the local machine?:
Or on a kubernetes cluster, in docker, over HTTPS??:
So versatile, much commas!
Do you even?
Yes I did, here are my notes:
The COPYses
Using
/copyeffectively executes file operations on whatever system thepsqlcommand is running on, as the user who is executing it1. If you connect to a remote server, it's simple to copy data files on the system executingpsqlto/from the remote server.COPYexecutes file operations on the server as the backend process user account (defaultpostgres), file paths and permissions are checked and applied accordingly. If usingTO STDOUTthen file permissions checks are bypassed.Both of these options require subsequent file movement if
psqlis not executing on the system where you want the resultant CSV to ultimately reside. This is the most likely case, in my experience, when you mostly work with remote servers.It is more complex to configure something like a TCP/IP tunnel over ssh to a remote system for simple CSV output, but for other output formats (binary) it may be better to
/copyover a tunneled connection, executing a localpsql. In a similar vein, for large imports, moving the source file to the server and usingCOPYis probably the highest-performance option.PSQL Parameters
With psql parameters you can format the output like CSV but there are downsides like having to remember to disable the pager and not getting headers:
Other Tools
No, I just want to get CSV out of my server without compiling and/or installing a tool.
新版本 - psql 12 - 将支持
--csv。用法:
New version - psql 12 - will support
--csv.Usage:
如果您对特定表的所有列以及标题感兴趣,您可以使用
简单一点,是等效的。
这比据我所知
If you're interested in all the columns of a particular table along with headers, you can use
This is a tiny bit simpler than
which, to the best of my knowledge, are equivalent.
我必须使用 \COPY 因为我收到错误消息:
所以我使用:
并且它正在运行
I had to use the \COPY because I received the error message:
So I used:
and it is functioning
我正在使用 AWS Redshift,它不支持 COPY TO 功能。
不过,我的 BI 工具支持制表符分隔的 CSV,因此我使用了以下内容:
I'm working on AWS Redshift, which does not support the
COPY TOfeature.My BI tool supports tab-delimited CSVs though, so I used the following:
psql可以为您执行此操作:请参阅
man psql以获取有关此处使用的选项的帮助。psqlcan do this for you:See
man psqlfor help on the options used here.在 pgAdmin III 中,有一个选项可以从查询窗口导出到文件。在主菜单中是“查询”->“查询”。执行到文件或者有一个按钮可以执行相同的操作(它是带有蓝色软盘的绿色三角形,而不是仅运行查询的纯绿色三角形)。如果您没有从查询窗口运行查询,那么我会执行 IMSoP 建议的操作并使用复制命令。
In pgAdmin III there is an option to export to file from the query window. In the main menu it's Query -> Execute to file or there's a button that does the same thing (it's a green triangle with a blue floppy disk as opposed to the plain green triangle which just runs the query). If you're not running the query from the query window then I'd do what IMSoP suggested and use the copy command.
如果您有更长的查询并且喜欢使用 psql,则将查询放入文件并使用以下命令:
If you have longer query and you like to use psql then put your query to a file and use the following command:
我编写了一个名为
psql2csv的小工具,它封装了COPY查询 TO STDOUT模式,生成正确的 CSV。它的界面类似于psql。假定查询是 STDIN 的内容(如果存在)或最后一个参数。除以下参数外,所有其他参数都转发到 psql:
I've written a little tool called
psql2csvthat encapsulates theCOPY query TO STDOUTpattern, resulting in proper CSV. It's interface is similar topsql.The query is assumed to be the contents of STDIN, if present, or the last argument. All other arguments are forwarded to psql except for these:
我尝试了几种方法,但很少有人能够为我提供所需的带有标题详细信息的 CSV。
这对我有用。
I tried several things but few of them were able to give me the desired CSV with header details.
Here is what worked for me.
从 Postgres 12 开始,您可以更改输出格式:
允许使用以下格式:
如果您想导出请求的结果,可以使用
\o filename功能。例子 :
Since Postgres 12, you can change the output format :
The following formats are allowed :
If you want to export the result of a request, you can use the
\o filenamefeature.Example :
要下载列名称为 HEADER 的 CSV 文件,请使用以下命令:
To Download CSV file with column names as HEADER use this command:
我发现 psql --csv 创建了一个包含 UTF8 字符的 CSV 文件,但缺少 UTF8 字节顺序标记 (0xEF 0xBB 0xBF)。如果不考虑这一点,此 CSV 文件的默认导入将损坏国际字符,例如 CJK 字符。
为了解决这个问题,我设计了以下脚本:
通过这种方式,我可以编写 CSV 创建过程的脚本以实现自动化,并允许我在单个源文件中简洁地维护脚本。
I found that
psql --csvcreates a CSV file with UTF8 characters but it is missing the UTF8 Byte Order Mark (0xEF 0xBB 0xBF). Without taking it into account, the default import of this CSV file will corrupt international characters such as CJK characters.To fix it, I devised the following script:
Doing it this way, lets me script the CSV creation process for automation and allows me to succinctly maintain the script in a single source file.
当您的查询太长且无法内联写入时,可以使用如下临时表:
When your query is too long and you can't write it inline, you can use a temporary table like this :
如果您使用的是 AWS,例如 AWS RDS,则可以使用 PGAdmin。我所做的是创建一个具有所需输出的临时表:
然后在 PGAdmin 中,它有一个导出到 CSV 的选项:
在那里,您可以指定保存位置以及格式:
然后它会直接保存到您的计算机上。请记住,AWS RDS 向您隐藏了其运行的底层计算,因此您无权访问底层服务器(EC2 或 Fargate 实例)。换句话说,您无法通过 ssh 访问它。不过,您可以访问 postgres cli 并从 PGAdmin 连接到它,并且使用新的 PGAdmin 界面,可以轻松导出到 csv。
If you are using AWS, such as AWS RDS, then you can use PGAdmin. What I do is create a temporary table with the desired output:
Then in PGAdmin, it has an export to CSV Option:
There, you can specify where to save it and in what format:
And then it saves right to your computer. Remember AWS RDS hides the underlying compute it runs on from you, so you do not have access to the underlying server (EC2 or Fargate instance). In other words, you cannot ssh into it. You can access the postgres cli though and connect to it from PGAdmin and with the new PGAdmin interface, it makes it easy to export to csv.