解决8字谜题的有效方法是什么?
8 拼图是一块有 9 个位置的方板,由 8 个编号的图块和一个间隙填充。在任何时候,与间隙相邻的图块都可以移动到间隙中,从而创建新的间隙位置。换句话说,间隙可以与相邻(水平和垂直)的图块交换。游戏的目标是从任意配置的图块开始,然后移动它们以使编号的图块按升序排列,或者沿着棋盘的周边运行,或者从左到右排序,其中 1 在左上角-手的位置。
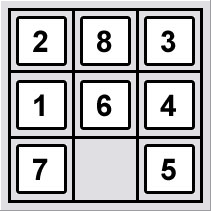
我想知道什么方法可以有效解决这个问题?
The 8-puzzle is a square board with 9 positions, filled by 8 numbered tiles and one gap. At any point, a tile adjacent to the gap can be moved into the gap, creating a new gap position. In other words the gap can be swapped with an adjacent (horizontally and vertically) tile. The objective in the game is to begin with an arbitrary configuration of tiles, and move them so as to get the numbered tiles arranged in ascending order either running around the perimeter of the board or ordered from left to right, with 1 in the top left-hand position.
I was wondering what approach will be efficient to solve this problem?
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!





发布评论
评论(6)
我将尝试重写之前的答案,并详细说明为什么它是最佳的。
直接取自 wikipedia 的 A* 算法是
所以让我在这里填写所有详细信息。
heuristic_estimate_of_distance是函数 Σ d(xi),其中 d(.) 是每个方格 xi 与其目标状态的曼哈顿距离。因此,该设置
的
heuristic_estimate_of_distance为 1+2+1=4,因为 8,5 中的每一个距离其目标位置 1,d(.)=1,7 距离其目标 2状态 d(7)=2。A* 搜索的节点集被定义为起始位置,后跟所有可能的合法位置。也就是说,起始位置 x 如上所述:
然后函数 neighbor_nodes(x) 产生 2 个可能的合法移动:
函数 dist_ Between(x,y) ) 定义为从状态
x转换到y所发生的方块移动次数。出于算法的目的,在 A* 中这通常等于 1。closeset和openset都是 A* 算法特有的,可以使用标准数据结构(我相信优先级队列)来实现。came_from是一个使用的数据结构使用函数
reconstruct_path重建找到的解决方案,其详细信息可以在维基百科上找到。如果您不想记住解决方案,则无需实施此解决方案。最后,我将讨论最优性问题。考虑 A* 维基百科文章的摘录:
“如果启发式函数 h 是可接受的,这意味着它永远不会高估达到目标的实际最小成本,那么如果我们不使用封闭式,A* 本身就是可接受的(或最佳的)如果使用闭集,则 h 也必须是单调的(或一致的),A* 才是最优的,这意味着对于任何一对相邻节点 x 和 y,其中 d(x,y) 表示 的长度。他们之间的边缘,我们必须有:
h(x) <= d(x,y) +h(y)"
因此足以表明我们的启发式是可接受的且单调的。对于前者(可接受性),请注意,给定任何配置,我们的启发式(所有启发式的总和)距离)估计每个方格不仅仅受到合法移动的约束,并且可以自由地向其目标位置移动,这显然是一个乐观的估计,因此我们的启发式是可接受的(或者它永远不会高估,因为到达目标位置总是需要 < em>至少与启发式估计一样多的动作。)
用文字表述的单调性要求是:
“任何节点的启发式成本(到目标状态的估计距离)必须小于或等于转换到任何相邻节点的成本加上该节点的启发式成本。”
它主要是为了防止出现负循环的可能性,即转换到不相关的节点可能会比实际进行转换的成本减少到目标节点的距离,这表明启发式很差。
在我们的例子中,显示单调性非常简单。根据我们对 d 的定义,任何相邻节点 x,y 都具有 d(x,y)=1。因此我们需要证明
h(x) <= h(y) + 1
相当于
h(x) - h(y) <= 1
相当于
Σ d(xi) - Σ d(yi) <= 1
相当于
Σ d(xi) - d(yi) <= 1
根据 neighbor_nodes(x) 的定义,我们知道两个邻居节点 x,y 最多可以有一个方格的位置不同,这意味着在我们的总和中,项
d(x< sub>i) - d(yi) = 0
对于除 1 之外的所有 i 值。不失一般性地说,i=k 是这样。此外,我们知道,对于 i=k,节点最多移动了一处,因此它到
目标状态最多只能比前一个状态多 1,因此:
Σ d(xi) - d(yi) = d(xk ) - d(yk) <= 1
显示单调性。这显示了需要显示的内容,从而证明该算法将是最优的(以大 O 表示法或渐近方式)。
请注意,我已经在大 O 表示法方面展示了最优性,但仍然有很多空间调整启发式。您可以对其添加额外的扭曲,以便更接近地估计到目标状态的实际距离,但是您必须确保启发式始终是< em>低估否则你就会失去最优性!
很久以后
编辑这篇文章(很久)之后,我意识到我写它的方式有点混淆了这个算法的最优性的含义。
我在这里试图理解的最优性有两个不同的含义:
1)算法产生最优解决方案,即给定客观标准的最佳可能解决方案。
2) 该算法使用相同的启发式扩展了所有可能算法的最少状态节点数。
理解为什么需要启发式的可接纳性和单调性来获得 1) 的最简单方法是将 A* 视为 Dijkstra 最短路径算法在图上的应用,其中边权重由迄今为止移动的节点距离加上启发式给出距离。如果没有这两个属性,我们就会在图中出现负边,从而可能出现负循环,并且 Dijkstra 的最短路径算法将不再返回正确答案! (构造一个简单的例子来说服自己。)
2)实际上很难理解。为了充分理解这句话的意思,这个说法有很多量词,比如在谈论其他算法时,指的是像A*这样的
类似算法,它扩展节点并在没有先验的情况下进行搜索显然,我们可以构造一个简单的反例,例如神谕或精灵在每一步都告诉您答案。要深入理解此声明,我强烈建议阅读维基百科<历史部分的最后一段/a> 以及查看该仔细陈述的句子中的所有引文和脚注。我希望这能消除潜在读者中剩余的困惑。
I will just attempt to rewrite the previous answer with more details on why it is optimal.
The A* algorithm taken directly from wikipedia is
So let me fill in all the details here.
heuristic_estimate_of_distanceis the function Σ d(xi) where d(.) is the Manhattan distance of each square xi from its goal state.So the setup
would have a
heuristic_estimate_of_distanceof 1+2+1=4 since each of 8,5 are one away from their goal position with d(.)=1 and 7 is 2 away from its goal state with d(7)=2.The set of nodes that the A* searches over is defined to be the starting position followed by all possible legal positions. That is lets say the starting position
xis as above:then the function
neighbor_nodes(x)produces the 2 possible legal moves:The function
dist_between(x,y)is defined as the number of square moves that took place to transition from statextoy. This is mostly going to be equal to 1 in A* always for the purposes of your algorithm.closedsetandopensetare both specific to the A* algorithm and can be implemented using standard data structures (priority queues I believe.)came_fromis a data structure usedto reconstruct the solution found using the function
reconstruct_pathwho's details can be found on wikipedia. If you do not wish to remember the solution you do not need to implement this.Last, I will address the issue of optimality. Consider the excerpt from the A* wikipedia article:
"If the heuristic function h is admissible, meaning that it never overestimates the actual minimal cost of reaching the goal, then A* is itself admissible (or optimal) if we do not use a closed set. If a closed set is used, then h must also be monotonic (or consistent) for A* to be optimal. This means that for any pair of adjacent nodes x and y, where d(x,y) denotes the length of the edge between them, we must have:
h(x) <= d(x,y) +h(y)"
So it suffices to show that our heuristic is admissible and monotonic. For the former (admissibility), note that given any configuration our heuristic (sum of all distances) estimates that each square is not constrained by only legal moves and can move freely towards its goal position, which is clearly an optimistic estimate, hence our heuristic is admissible (or it never over-estimates since reaching a goal position will always take at least as many moves as the heuristic estimates.)
The monotonicity requirement stated in words is:
"The heuristic cost (estimated distance to goal state) of any node must be less than or equal to the cost of transitioning to any adjacent node plus the heuristic cost of that node."
It is mainly to prevent the possibility of negative cycles, where transitioning to an unrelated node may decrease the distance to the goal node more than the cost of actually making the transition, suggesting a poor heuristic.
To show monotonicity its pretty simple in our case. Any adjacent nodes x,y have d(x,y)=1 by our definition of d. Thus we need to show
h(x) <= h(y) + 1
which is equivalent to
h(x) - h(y) <= 1
which is equivalent to
Σ d(xi) - Σ d(yi) <= 1
which is equivalent to
Σ d(xi) - d(yi) <= 1
We know by our definition of
neighbor_nodes(x)that two neighbour nodes x,y can have at most the position of one square differing, meaning that in our sums the termd(xi) - d(yi) = 0
for all but 1 value of i. Lets say without loss of generality this is true of i=k. Furthermore, we know that for i=k, the node has moved at most one place, so its distance to
a goal state must be at most one more than in the previous state thus:
Σ d(xi) - d(yi) = d(xk) - d(yk) <= 1
showing monotonicity. This shows what needed to be showed, thus proving this algorithm will be optimal (in a big-O notation or asymptotic kind of way.)
Note, that I have shown optimality in terms of big-O notation but there is still lots of room to play in terms of tweaking the heuristic. You can add additional twists to it so that it is a closer estimate of the actual distance to the goal state, however you have to make sure that the heuristic is always an underestimate otherwise you loose optimality!
EDIT MANY MOONS LATER
Reading this over again (much) later, I realized the way I wrote it sort of confounds the meaning of optimality of this algorithm.
There are two distinct meanings of optimality I was trying to get at here:
1) The algorithm produces an optimal solution, that is the best possible solution given the objective criteria.
2) The algorithm expands the least number of state nodes of all possible algorithms using the same heuristic.
The simplest way to understand why you need admissibility and monotonicity of the heuristic to obtain 1) is to view A* as an application of Dijkstra's shortest path algorithm on a graph where the edge weights are given by the node distance traveled thus far plus the heuristic distance. Without these two properties, we would have negative edges in the graph, thereby negative cycles would be possible and Dijkstra's shortest path algorithm would no longer return the correct answer! (Construct a simple example of this to convince yourself.)
2) is actually quite confusing to understand. To fully understand the meaning of this, there are a lot of quantifiers on this statement, such as when talking about other algorithms, one refers to
similaralgorithms as A* that expand nodes and search without a-priori information (other than the heuristic.) Obviously, one can construct a trivial counter-example otherwise, such as an oracle or genie that tells you the answer at every step of the way. To understand this statement in depth I highly suggest reading the last paragraph in the History section on Wikipedia as well as looking into all the citations and footnotes in that carefully stated sentence.I hope this clears up any remaining confusion among would-be readers.
您可以使用基于数字位置的启发式,即每个字母与其目标状态的所有距离的总和越高,启发式值就越高。然后您可以实现 A* 搜索,这可以被证明是时间和空间复杂度方面的最佳搜索(假设启发式是单调且可接受的。) http://en.wikipedia.org/wiki/A*_search_algorithm
You can use the heuristic that is based on the positions of the numbers, that is the higher the overall sum of all the distances of each letter from its goal state is, the higher the heuristic value. Then you can implement A* search which can be proved to be the optimal search in terms of time and space complexity (provided the heuristic is monotonic and admissible.) http://en.wikipedia.org/wiki/A*_search_algorithm
由于OP无法发布图片,这就是他所说的:
就解决而言这个难题,去看看迭代加深深度优先搜索算法,正如此页面与 8-puzzle 问题相关的内容。
Since the OP cannot post a picture, this is what he's talking about:
As far as solving this puzzle, goes, take a look at the iterative deepening depth-first search algorithm, as made relevant to the 8-puzzle problem by this page.
甜甜圈搞定了!考虑到这个难题的搜索空间相对有限,IDDFS 就能解决这个问题。因此回答OP的问题会很有效。它会找到最优解,但不一定是最优复杂度。
实现 IDDFS 将是这个问题中更复杂的部分,我只是想建议一种简单的方法来管理棋盘、游戏规则等。这特别解决了一种获取可解谜题的初始状态的方法。问题注释中暗示,并非所有 9 个点的随机分配(将空槽视为特殊图块)都会产生可解决的难题。这是数学奇偶性的问题......所以,这里有一个对游戏进行建模的建议:
列出代表游戏有效“移动”的所有 3x3 排列矩阵。
这样的列表是 3x3 的子集(全零和两个 1)。每个矩阵都有一个 ID,这对于在 IDDFS 搜索树中跟踪移动非常方便。矩阵的替代方案是交换瓦片位置编号的二元组,这可能会导致更快的实现。
这样的矩阵可用于创建初始拼图状态,从“获胜”状态开始,并运行随机选择的任意数量的排列。除了确保初始状态是可解的之外,这种方法还提供了可以解决给定谜题的指示性移动次数。
现在让我们实现 IDDFS 算法并[笑话]返回 A+ 的作业[/笑话]...
Donut's got it! IDDFS will do the trick, considering the relatively limited search space of this puzzle. It would be efficient hence respond to the OP's question. It would find the optimal solution, but not necessarily in optimal complexity.
Implementing IDDFS would be the more complicated part of this problem, I just want to suggest an simple approach to managing the board, the games rules etc. This in particular addresses a way to obtain initial states for the puzzle which are solvable. An hinted in the notes of the question, not all random assignemts of 9 tites (considering the empty slot a special tile), will yield a solvable puzzle. It is a matter of mathematical parity... So, here's a suggestions to model the game:
Make the list of all 3x3 permutation matrices which represent valid "moves" of the game.
Such list is a subset of 3x3s w/ all zeros and two ones. Each matrix gets an ID which will be quite convenient to keep track of the moves, in the IDDFS search tree. An alternative to matrices, is to have two-tuples of the tile position numbers to swap, this may lead to faster implementation.
Such matrices can be used to create the initial puzzle state, starting with the "win" state, and running a arbitrary number of permutations selected at random. In addition to ensuring that the initial state is solvable this approach also provides a indicative number of moves with which a given puzzle can be solved.
Now let's just implement the IDDFS algo and [joke]return the assignement for an A+[/joke]...
这是经典最短路径算法的一个例子。您可以在此处和此处。
简而言之,将拼图的所有可能状态视为某个图中的顶点。每次移动都会改变状态 - 因此,每个有效的移动都代表图形的一条边。由于移动没有任何成本,您可能会认为每次移动的成本为 1。以下类似 C++ 的伪代码适用于解决此问题:
This is an example of the classical shortest path algorithm. You can read more about shortest path here and here.
In short, think of all possible states of the puzzle as of vertices in some graph. With each move you change states - so, each valid move represents an edge of the graph. Since moves don't have any cost, you may think of the cost of each move being 1. The following c++-like pseudo-code will work for this problem:
请参阅此链接,了解我的并行加深迭代深入搜索15个难题的解决方案,它是 8 拼图的 4x4 老大哥。
See this link for my parallel iterative deepening search for a solution to the 15-puzzle, which is the 4x4 big-brother of the 8-puzzle.