有人可以解释一下广度优先搜索吗?
有人可以解释广度优先搜索来解决以下类型的问题 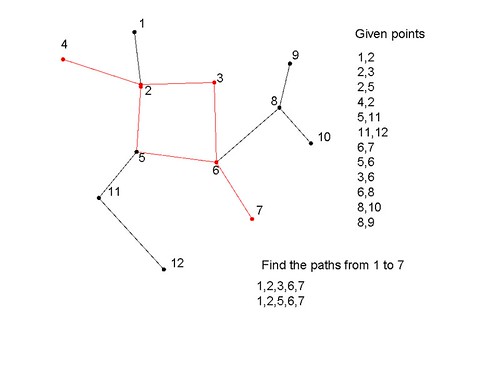
我需要找到 4 到 7 之间的所有路径
Can someone explain Breadth-first search to solve the below kind of problems
I need to find all the paths between 4 and 7
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!






发布评论
评论(5)
您查看与起始节点相邻的所有节点。 然后,您查看与这些节点相邻的所有节点(不会返回到您已经查看过的节点)。 重复直到找到满意的节点或不再有节点。
对于您指出的问题类型,您可以使用上述过程来构建一组路径,终止任何到达所需目标节点的路径,并且当您的图耗尽时,如此终止的一组路径就是您的解决方案集。
You look at all the nodes adjacent to your start node. Then you look at all the nodes adjacent to those (not returning to nodes you've already looked at). Repeat until satisfying node found or no more nodes.
For the kind of problem you indicate, you use the process described above to build a set of paths, terminating any that arrive at the desired destination node, and when your graph is exhausted, the set of paths that so terminated is your solution set.
广度优先搜索 (BFS) 意味着您在进入更深层次之前处理所有起始节点的直接子节点。 BFS是通过队列来实现的,队列存储需要处理的节点列表。
您可以通过将起始节点添加到队列来启动算法。 然后继续运行算法,直到队列中没有任何内容可以处理为止。
当您从队列中出列一个元素时,它就成为您的活动节点。 当您处理活动节点时,会将其所有子节点添加到队列的后面。 当队列为空时,您将终止算法。
由于您处理的是图而不是树,因此您需要存储已处理节点的列表,这样就不会进入循环。
一旦到达节点 7,您就有了一条匹配的路径,您可以停止对该递归路径执行 BFS。 这意味着您根本不将其子级添加到队列中。 为了避免循环并了解您访问过的确切路径,在执行递归 BFS 调用时,请传递已访问过的节点。
Breadth first search (BFS) means that you process all of your starting nodes' direct children, before going to deeper levels. BFS is implemented with a queue which stores a list of nodes that need to be processed.
You start the algorithm by adding your start node to the queue. Then you continue to run your algorithm until you have nothing left to process in the queue.
When you dequeue an element from the queue, it becomes your active node. When you are processing your active node, you add all of its children to the back of the queue. You terminate the algorithm when you have an empty queue.
Since you are dealing with a graph instead of a tree, you need to store a list of your processed nodes so you don't enter into a loop.
Once you reach node 7 you have a matching path and you can stop doing the BFS for that recursive path. Meaning that you simply don't add its children to the queue. To avoid loops and to know the exact path you've visited, as you do your recursive BFS calls, pass up the already visited nodes.
将其视为带有其他网站链接的网站。 让 A 成为我们的根节点或我们的起始网站。
这只有三层深。 您一次搜索一层。 因此,在这种情况下,您将从 A 层开始。如果不匹配,您将转到下一层 AA、AB 和 AC。 如果这些网站都不是您要搜索的网站,那么您可以点击链接进入下一层。 换句话说,您一次查看一层。
深度优先搜索(它的补充)你会从 A 到 AA 再到 AAA。 换句话说,在走宽之前你会先走深。
Think of it as websites with links to other sites on them. Let A be our root node or our starting website.
This is only three layers deep. You search one layer at a time. So in this case you would start at layer A. If that does not match you go to the next layer, AA, AB and AC. If none of those websites is the one you are searching for then you follow the links and go to the next layer. In other words, you look at one layer at a time.
A depth first search (its complement) you would go from A to AA to AAA. In other words you would go DEEP before going WIDE.
您测试连接到根节点的每个节点。 然后测试连接到先前节点的每个节点。 依此类推,直到找到答案。
基本上,每次迭代都会测试距根节点相同距离的节点。
You test each node connected to the root node. Then you test each node connected to the previous nodes. So on, until you find your answer.
Basically, each iteration tests nodes that are the same distance away from the root node.
开始
4;
4,2;
4,2,1; 4,2,3; 4,2,5;
4,2,1;(失败)4,2,3,6; 4,2,5,6; 4,2,5,11;
4,2,3,6,7;(通过)4,2,3,6,8; 4,2,5,6,7;(通过)4,2,5,6,8; 4,2,5,11,12;
4,2,3,6,8,9; 4,2,3,6,8,10; 4,2,5,6,8,9; 4,2,5,6,8,10; 4,2,5,11,12;(失败)
4,2,3,6,8,9;(失败)4,2,3,6,8,10;(失败)4,2,5,6 ,8,9;(失败) 4,2,5,6,8,10;(失败)
END
BEGIN
4;
4,2;
4,2,1; 4,2,3; 4,2,5;
4,2,1;(fail) 4,2,3,6; 4,2,5,6; 4,2,5,11;
4,2,3,6,7;(pass) 4,2,3,6,8; 4,2,5,6,7;(pass) 4,2,5,6,8; 4,2,5,11,12;
4,2,3,6,8,9; 4,2,3,6,8,10; 4,2,5,6,8,9; 4,2,5,6,8,10; 4,2,5,11,12;(fail)
4,2,3,6,8,9;(fail) 4,2,3,6,8,10;(fail) 4,2,5,6,8,9;(fail) 4,2,5,6,8,10;(fail)
END