如何通过众包排序对一百万张图像进行排名
我想通过制作一个游戏来对一组风景图像进行排名,网站访问者可以对它们进行评分,以便找出人们认为哪些图像最具吸引力。
这样做的好方法是什么?
- 流行还是不流行的风格? 即显示单个图像,要求用户从 1-10 对其进行排名。 在我看来,这使我能够平均得分,并且我只需要确保我在所有图像中获得均匀的选票分配。 实施起来相当简单。
- 选择A还是B? 即显示两张图像,要求用户选择更好的一张。 这很有吸引力,因为没有数字排名,只是比较。 但我该如何实施呢? 我的第一个想法是将其作为快速排序,由人类提供比较操作,一旦完成,只需无限地重复排序。
你会怎么做?
如果您需要数字,我指的是一个每日访问量为 20,000 次的网站上的 100 万张图像。 我想象一小部分人可能会玩这个游戏,为了便于讨论,假设我每天可以生成 2,000 个人类排序操作! 这是一个非营利网站,好奇的人会通过我的个人资料找到它:)
I'd like to rank a collection of landscape images by making a game whereby site visitors can rate them, in order to find out which images people find the most appealing.
What would be a good method of doing that?
- Hot-or-Not style? I.e. show a single image, ask the user to rank it from 1-10. As I see it, this allows me to average the scores, and I would just need to ensure that I get an even distribution of votes across all the images. Fairly simple to implement.
- Pick A-or-B? I.e. show two images, ask user to pick the better one. This is appealing as there is no numerical ranking, it's just a comparison. But how would I implement it? My first thought was to do it as a quicksort, with the comparison operations being provided by humans, and once completed, simply repeat the sort ad-infinitum.
How would you do it?
If you need numbers, I'm talking about one million images, on a site with 20,000 daily visits. I'd imagine a small proportion might play the game, for the sake of argument, lets say I can generate 2,000 human sort operations a day! It's a non-profit website, and the terminally curious will find it through my profile :)
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!







发布评论
评论(12)
正如其他人所说,排名 1-10 的效果并不好,因为人们的水平不同。
选择 A-or-B 方法的问题在于,它不能保证系统的传递性(A 可以击败 B,但 B 可以击败 C,C 可以击败 A)。 使用非传递比较运算符会破坏排序算法。 对于此示例,使用快速排序,未选择作为主元的字母将被错误地相互排名。
在任何给定时间,您都希望获得所有图片的绝对排名(即使其中一些/全部图片并列)。 您还希望您的排名不会发生变化除非有人投票。
我会使用选择 A-或-B(或平局) 方法,但确定类似于 Elo 评级系统,用于 2 人游戏(最初是国际象棋)的排名:
Elo系统:
用图片替换“玩家”,您可以通过一个简单的方法根据公式调整两张图片的评级。 然后,您可以使用这些数字分数进行排名。 (此处的 K 值是锦标赛的“级别”。小型本地锦标赛为 8-16,大型邀请赛/区域赛为 24-32。您可以使用 20 这样的常量)。
使用这种方法,您只需要为每张图片保留一个数字,这比将每张图片的单独排名保留在其他图片上要少得多的内存消耗。
编辑:根据评论添加了更多内容。
As others have said, ranking 1-10 does not work that well because people have different levels.
The problem with the Pick A-or-B method is that its not guaranteed for the system to be transitive (A can beat B, but B beats C, and C beats A). Having nontransitive comparison operators breaks sorting algorithms. With quicksort, against this example, the letters not chosen as the pivot will be incorrectly ranked against each other.
At any given time, you want an absolute ranking of all the pictures (even if some/all of them are tied). You also want your ranking not to change unless someone votes.
I would use the Pick A-or-B (or tie) method, but determine ranking similar to the Elo ratings system which is used for rankings in 2 player games (originally chess):
The Elo System:
Replace "players" with pictures and you have a simple way of adjusting both pictures' rating based on a formula. You can then perform a ranking using those numeric scores. (K-Value here is the "Level" of the tournament. It's 8-16 for small local tournaments and 24-32 for larger invitationals/regionals. You can just use a constant like 20).
With this method, you only need to keep one number for each picture which is a lot less memory intensive than keeping the individual ranks of each picture to each other picture.
EDIT: Added a little more meat based on comments.
大多数解决这个问题的天真的方法都有一些严重的问题。 最糟糕的是 bash.org 和 qdb.us 显示报价 - 用户可以对报价进行向上 (+1) 或向下 (-1) 投票,最佳报价列表按总净得分排序。 这遭受了可怕的时间偏见——较旧的引言通过简单的长寿积累了大量的积极选票,即使它们只是有点幽默。 如果笑话随着年龄的增长而变得更有趣,那么这个算法可能有意义,但相信我,事实并非如此。
有各种尝试来解决这个问题——查看每个时间段的正面投票数量、对最近的投票进行加权、对较旧的投票实施衰减系统、计算正面投票与负面投票的比率等。大多数都存在其他缺陷。
我认为最好的解决方案是网站 最有趣的解决方案< /a> 最可爱, The Fairest 和 Best Thing 使用 - a 修改后的孔多塞投票系统:
有关实施此类系统的更多信息,维基百科页面上的排名对应该会有所帮助。
该算法要求人们比较两个对象(您选择 A 或 B 选项),但坦率地说,这是一件好事。 我相信,在决策理论中,人类在比较两个对象方面比在抽象排名方面要好得多,这一点已被广泛接受。 数百万年的进化使我们擅长从树上采摘最好的苹果,但不擅长决定我们采摘的苹果与真正的柏拉图式苹果的接近程度。 (顺便说一句,这就是为什么层次分析过程如此漂亮......但这就是有点偏离主题。)
最后要指出的是,SO 使用一种算法来查找最佳答案,该算法与 bash.org 非常相似 的算法来找到最佳报价。 它在这里运作良好,但在那里却严重失败 - 很大程度上是因为这里旧的、评价很高但现在已经过时的答案可能会被编辑。 bash.org 不允许编辑,而且不清楚你如何去编辑关于现在过时的互联网模因的十年前的笑话,即使你可以......无论如何,我的观点是,正确的算法通常是取决于您的问题的详细信息。 :-)
Most naive approaches to the problem have some serious issues. The worst is how bash.org and qdb.us displays quotes - users can vote a quote up (+1) or down (-1), and the list of best quotes is sorted by the total net score. This suffers from a horrible time bias - older quotes have accumulated huge numbers of positive votes via simple longevity even if they're only marginally humorous. This algorithm might make sense if jokes got funnier as they got older but - trust me - they don't.
There are various attempts to fix this - looking at the number of positive votes per time period, weighting more recent votes, implementing a decay system for older votes, calculating the ratio of positive to negative votes, etc. Most suffer from other flaws.
The best solution - I think - is the one that the websites The Funniest The Cutest, The Fairest, and Best Thing use - a modified Condorcet voting system:
For more information on implementing such systems the Wikipedia page on Ranked Pairs should be helpful.
The algorithm requires people to compare two objects (your Pick-A-or-B option), but frankly, that's a good thing. I believe it's very well accepted in decision theory that humans are vastly better at comparing two objects than they are at abstract ranking. Millions of years of evolution make us good at picking the best apple off the tree, but terrible at deciding how closely the apple we picked hews to the true Platonic Form of appleness. (This is, by the way, why the Analytic Hierarchy Process is so nifty...but that's getting a bit off topic.)
One final point to make is that SO uses an algorithm to find the best answers which is very similar to bash.org's algorithm to find the best quote. It works well here, but fails terribly there - in large part because an old, highly rated, but now outdated answer here is likely to be edited. bash.org doesn't allow editing, and it's not clear how you'd even go about editing decade-old jokes about now-dated internet memes even if you could... In any case, my point is that the right algorithm usually depends on the details of your problem. :-)
我知道这个问题已经很老了,但我想我会做出贡献,
我会看看微软研究院开发的 TrueSkill 系统。 它类似于 ELO,但收敛时间要快得多(与线性相比,看起来呈指数形式),因此您可以从每次投票中获得更多收益。 然而,它在数学上更为复杂。
http://en.wikipedia.org/wiki/TrueSkill
I know this question is quite old but I thought I'd contribute
I'd look at the TrueSkill system developed at Microsoft Research. It's like ELO but has a much faster convergence time (looks exponential compared to linear), so you get more out of each vote. It is, however, more complex mathematically.
http://en.wikipedia.org/wiki/TrueSkill
我不喜欢不热不热的风格。 即使他们都喜欢完全相同的图像,不同的人也会选择不同的数字。 另外,我讨厌给事物打分(满分 10 分),我永远不知道该选择哪个数字。
选择 A-或 B 更加简单和有趣。 您可以看到两张图像,并在网站上的图像之间进行比较。
I don't like the Hot-or-Not style. Different people would pick different numbers even if they all liked the image exactly the same. Also I hate rating things out of 10, I never know which number to choose.
Pick A-or-B is much simpler and funner. You get to see two images, and comparisons are made between the images on the site.
这些来自 Wikipedia 的方程使得计算 Elo 评级(图像 A 的算法)变得更简单/更有效B 很简单:
使用以下方法计算双方的新评分:
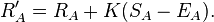
更新新评级 RA、RB 并计数 mA、mB
These equations from Wikipedia makes it simpler/more effective to calculate Elo ratings, the algorithm for images A and B would be simple:
Calculate the new ratings for both using:
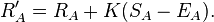
Update the new ratings RA,RB and counts mA,mB in the database.
您可能想要组合使用。
第一阶段:
热与否风格(尽管我会选择 3 个选项投票:糟透了,嗯/好吧。酷!)
一旦你将集合分类到 3 个桶中,那么我会从同一个桶中选择两个图像并继续 然后,您可以使用英国足球的升级和降级系统将前几个“糟糕
”移动到 Meh/OK 区域,以细化边缘情况。
You may want to go with a combination.
First phase:
Hot-or-not style (although I would go with a 3 option vote: Sucks, Meh/OK. Cool!)
Once you've sorted the set into the 3 buckets, then I would select two images from the same bucket and go with the "Which is nicer"
You could then use an English Soccer system of promotion and demotion to move the top few "Sucks" into the Meh/OK region, in order to refine the edge cases.
排名1-10是不行的,每个人的级别不同。 总是给出 3-7 分的人的排名会比总是给出 1 或 10 分的人黯然失色。a-
或-b 更可行。
Ranking 1-10 won't work, everyone has different levels. Someone who always gives 3-7 ratings would have his rankings eclipsed by people who always give 1 or 10.
a-or-b is more workable.
哇,我比赛迟到了。
我非常喜欢 ELO 系统,但正如欧文所说,在我看来,你会缓慢地建立任何重要的结果。
我相信人类的能力比仅仅比较两个图像要强大得多,但你希望将交互保持在最低限度。
那么,您如何显示 n 张图像(n 是您可以在屏幕上明显显示的任何数字,这可能是 10、20、30,具体取决于用户的偏好)并让他们选择他们认为该批次中最好的图像。 现在回到 ELO。 你需要修改你的评级系统,但保持同样的精神。 事实上,您已将一张图像与其他 n-1 张图像进行了比较。 因此,您进行了 n-1 次 ELO 评级,但您应该将评级的变化除以 n-1 次以进行匹配(以便不同 n 值的结果彼此一致)。
你完成了。 您现在已经拥有了世界上最好的。 一个简单的评级系统,只需点击一下即可处理许多图像。
Wow, I'm late in the game.
I like the ELO system very much so, but like Owen says it seems to me that you'd be slow building up any significant results.
I believe humans have much greater capacity than just comparing two images, but you want to keep interactions to the bare minimum.
So how about you show n images (n being any number you can visibly display on a screen, this may be 10, 20, 30 depending on user's preference maybe) and get them to pick which they think is best in that lot. Now back to ELO. You need to modify you ratings system, but keep the same spirit. You have in fact compared one image to n-1 others. So you do your ELO rating n-1 times, but you should divide the change of rating by n-1 to match (so that results with different values of n are coherent with one another).
You're done. You've now got the best of all worlds. A simple rating system working with many images in one click.
如果您更喜欢使用选择 A 或 B 策略,我会推荐这篇论文:http://research.microsoft.com/en-us/um/people/horvitz/crowd_pairwise.pdf
该论文介绍了 Crowd-BT 模型,该模型将著名的 Bradley-Terry 成对比较模型扩展到众包环境中。 它还给出了自适应学习算法来增强模型的时间和空间效率。 您可以在 Github 上找到该算法的 Matlab 实现(但我不确定是否有用)。
If you prefer using the Pick A or B strategy I would recommend this paper: http://research.microsoft.com/en-us/um/people/horvitz/crowd_pairwise.pdf
The paper tells about the Crowd-BT model which extends the famous Bradley-Terry pairwise comparison model into crowdsource setting. It also gives an adaptive learning algorithm to enhance the time and space efficiency of the model. You can find a Matlab implementation of the algorithm on Github (but I'm not sure if it works).
已不复存在的网站 Whatsbetter.com 使用了 Elo 风格方法。 您可以在 常见问题解答中了解该方法互联网档案馆。
The defunct web site whatsbetter.com used an Elo style method. You can read about the method in their FAQ on the Internet Archive.
选择 A-或 B 这是最简单的,而且不太容易产生偏见,但是在每次人际互动中,它为您提供的信息要少得多。 我认为由于减少了偏差,Pick 更优越,并且在有限的范围内它为您提供了相同的信息。
一个非常简单的评分方案是对每张图片进行计数。 当有人给出正比较时,计数会增加;当有人给出负比较时,计数会减少。
对一百万个整数列表进行排序非常快,在现代计算机上只需不到一秒钟。
也就是说,这个问题相当不恰当——每张图像只显示一次需要 50 天的时间。
我打赌您对排名最高的图像更感兴趣? 因此,您可能希望通过预测排名来偏置图像检索 - 因此您更有可能显示已经实现一些积极比较的图像。 这样您将更快地开始显示“有趣”的图像。
Pick A-or-B its the simplest and less prone to bias, however at each human interaction it gives you substantially less information. I think because of the bias reduction, Pick is superior and in the limit it provides you with the same information.
A very simple scoring scheme is to have a count for each picture. When someone gives a positive comparison increment the count, when someone gives a negative comparison, decrement the count.
Sorting a 1-million integer list is very quick and will take less than a second on a modern computer.
That said, the problem is rather ill-posed - It will take you 50 days to show each image only once.
I bet though you are more interested in the most highly ranked images? So, you probably want to bias your image retrieval by predicted rank - so you are more likely to show images that have already achieved a few positive comparisons. This way you will more quickly just start showing 'interesting' images.
我喜欢快速排序选项,但我会花几周时间:
另一个有趣的选择是利用人群来教授神经网络。
I like the quick-sort option but I'd make a few tweeks:
The other fun option would be to use the crowd to teach a neural-net.