数学基础
- 线性代数
- 概率论与随机过程
- 数值计算
- 蒙特卡洛方法与 MCMC 采样
- 机器学习方法概论
统计学习
深度学习
- 深度学习简介
- 深度前馈网络
- 反向传播算法
- 正则化
- 深度学习中的最优化问题
- 卷积神经网络
- CNN:图像分类
- 循环神经网络 RNN
- Transformer
- 一、Transformer [2017]
- 二、Universal Transformer [2018]
- 三、Transformer-XL [2019]
- 四、GPT1 [2018]
- 五、GPT2 [2019]
- 六、GPT3 [2020]
- 七、OPT [2022]
- 八、BERT [2018]
- 九、XLNet [2019]
- 十、RoBERTa [2019]
- 十一、ERNIE 1.0 [2019]
- 十二、ERNIE 2.0 [2019]
- 十三、ERNIE 3.0 [2021]
- 十四、ERNIE-Huawei [2019]
- 十五、MT-DNN [2019]
- 十六、BART [2019]
- 十七、mBART [2020]
- 十八、SpanBERT [2019]
- 十九、ALBERT [2019]
- 二十、UniLM [2019]
- 二十一、MASS [2019]
- 二十二、MacBERT [2019]
- 二十三、Fine-Tuning Language Models from Human Preferences [2019]
- 二十四 Learning to summarize from human feedback [2020]
- 二十五、InstructGPT [2022]
- 二十六、T5 [2020]
- 二十七、mT5 [2020]
- 二十八、ExT5 [2021]
- 二十九、Muppet [2021]
- 三十、Self-Attention with Relative Position Representations [2018]
- 三十一、USE [2018]
- 三十二、Sentence-BERT [2019]
- 三十三、SimCSE [2021]
- 三十四、BERT-Flow [2020]
- 三十五、BERT-Whitening [2021]
- 三十六、Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings [2019]
- 三十七、CERT [2020]
- 三十八、DeCLUTR [2020]
- 三十九、CLEAR [2020]
- 四十、ConSERT [2021]
- 四十一、Sentence-T5 [2021]
- 四十二、ULMFiT [2018]
- 四十三、Scaling Laws for Neural Language Models [2020]
- 四十四、Chinchilla [2022]
- 四十七、GLM-130B [2022]
- 四十八、GPT-NeoX-20B [2022]
- 四十九、Bloom [2022]
- 五十、PaLM [2022] (粗读)
- 五十一、PaLM2 [2023](粗读)
- 五十二、Self-Instruct [2022]
- 句子向量
- 词向量
- 传统CTR 预估模型
- CTR 预估模型
- 一、DSSM [2013]
- 二、FNN [2016]
- 三、PNN [2016]
- 四、DeepCrossing [2016]
- 五、Wide 和 Deep [2016]
- 六、DCN [2017]
- 七、DeepFM [2017]
- 八、NFM [2017]
- 九、AFM [2017]
- 十、xDeepFM [2018]
- 十一、ESMM [2018]
- 十二、DIN [2017]
- 十三、DIEN [2019]
- 十四、DSIN [2019]
- 十五、DICM [2017]
- 十六、DeepMCP [2019]
- 十七、MIMN [2019]
- 十八、DMR [2020]
- 十九、MiNet [2020]
- 二十、DSTN [2019]
- 二十一、BST [2019]
- 二十二、SIM [2020]
- 二十三、ESM2 [2019]
- 二十四、MV-DNN [2015]
- 二十五、CAN [2020]
- 二十六、AutoInt [2018]
- 二十七、Fi-GNN [2019]
- 二十八、FwFM [2018]
- 二十九、FM2 [2021]
- 三十、FiBiNET [2019]
- 三十一、AutoFIS [2020]
- 三十三、AFN [2020]
- 三十四、FGCNN [2019]
- 三十五、AutoCross [2019]
- 三十六、InterHAt [2020]
- 三十七、xDeepInt [2023]
- 三十九、AutoDis [2021]
- 四十、MDE [2020]
- 四十一、NIS [2020]
- 四十二、AutoEmb [2020]
- 四十三、AutoDim [2021]
- 四十四、PEP [2021]
- 四十五、DeepLight [2021]
- 图的表达
- 一、DeepWalk [2014]
- 二、LINE [2015]
- 三、GraRep [2015]
- 四、TADW [2015]
- 五、DNGR [2016]
- 六、Node2Vec [2016]
- 七、WALKLETS [2016]
- 八、SDNE [2016]
- 九、CANE [2017]
- 十、EOE [2017]
- 十一、metapath2vec [2017]
- 十二、GraphGAN [2018]
- 十三、struc2vec [2017]
- 十四、GraphWave [2018]
- 十五、NetMF [2017]
- 十六、NetSMF [2019]
- 十七、PTE [2015]
- 十八、HNE [2015]
- 十九、AANE [2017]
- 二十、LANE [2017]
- 二十一、MVE [2017]
- 二十二、PMNE [2017]
- 二十三、ANRL [2018]
- 二十四、DANE [2018]
- 二十五、HERec [2018]
- 二十六、GATNE [2019]
- 二十七、MNE [2018]
- 二十八、MVN2VEC [2018]
- 二十九、SNE [2018]
- 三十、ProNE [2019]
- Graph Embedding 综述
- 图神经网络
- 一、GNN [2009]
- 二、Spectral Networks 和 Deep Locally Connected Networks [2013]
- 三、Fast Localized Spectral Filtering On Graph [2016]
- 四、GCN [2016]
- 五、神经图指纹 [2015]
- 六、GGS-NN [2016]
- 七、PATCHY-SAN [2016]
- 八、GraphSAGE [2017]
- 九、GAT [2017]
- 十、R-GCN [2017]
- 十一、 AGCN [2018]
- 十二、FastGCN [2018]
- 十三、PinSage [2018]
- 十四、GCMC [2017]
- 十五、JK-Net [2018]
- 十六、PPNP [2018]
- 十七、VRGCN [2017]
- 十八、ClusterGCN [2019]
- 十九、LDS-GNN [2019]
- 二十、DIAL-GNN [2019]
- 二十一、HAN [2019]
- 二十二、HetGNN [2019]
- 二十三、HGT [2020]
- 二十四、GPT-GNN [2020]
- 二十五、Geom-GCN [2020]
- 二十六、Graph Network [2018]
- 二十七、GIN [2019]
- 二十八、MPNN [2017]
- 二十九、UniMP [2020]
- 三十、Correct and Smooth [2020]
- 三十一、LGCN [2018]
- 三十二、DGCNN [2018]
- 三十三、AS-GCN
- 三十四、DGI [2018]
- 三十五、DIFFPOLL [2018]
- 三十六、DCNN [2016]
- 三十七、IN [2016]
- 图神经网络 2
- 图神经网络 3
- 推荐算法(传统方法)
- 一、Tapestry [1992]
- 二、GroupLens [1994]
- 三、ItemBased CF [2001]
- 四、Amazon I-2-I CF [2003]
- 五、Slope One Rating-Based CF [2005]
- 六、Bipartite Network Projection [2007]
- 七、Implicit Feedback CF [2008]
- 八、PMF [2008]
- 九、SVD++ [2008]
- 十、MMMF 扩展 [2008]
- 十一、OCCF [2008]
- 十二、BPR [2009]
- 十三、MF for RS [2009]
- 十四、 Netflix BellKor Solution [2009]
- 推荐算法(神经网络方法 1)
- 一、MIND [2019](用于召回)
- 二、DNN For YouTube [2016]
- 三、Recommending What Video to Watch Next [2019]
- 四、ESAM [2020]
- 五、Facebook Embedding Based Retrieval [2020](用于检索)
- 六、Airbnb Search Ranking [2018]
- 七、MOBIUS [2019](用于召回)
- 八、TDM [2018](用于检索)
- 九、DR [2020](用于检索)
- 十、JTM [2019](用于检索)
- 十一、Pinterest Recommender System [2017]
- 十二、DLRM [2019]
- 十三、Applying Deep Learning To Airbnb Search [2018]
- 十四、Improving Deep Learning For Airbnb Search [2020]
- 十五、HOP-Rec [2018]
- 十六、NCF [2017]
- 十七、NGCF [2019]
- 十八、LightGCN [2020]
- 十九、Sampling-Bias-Corrected Neural Modeling [2019](检索)
- 二十、EGES [2018](Matching 阶段)
- 二十一、SDM [2019](Matching 阶段)
- 二十二、COLD [2020 ] (Pre-Ranking 模型)
- 二十三、ComiRec [2020](https://www.wenjiangs.com/doc/0b4e1736-ac78)
- 二十四、EdgeRec [2020]
- 二十五、DPSR [2020](检索)
- 二十六、PDN [2021](mathcing)
- 二十七、时空周期兴趣学习网络ST-PIL [2021]
- 推荐算法之序列推荐
- 一、FPMC [2010]
- 二、GRU4Rec [2015]
- 三、HRM [2015]
- 四、DREAM [2016]
- 五、Improved GRU4Rec [2016]
- 六、NARM [2017]
- 七、HRNN [2017]
- 八、RRN [2017]
- 九、Caser [2018]
- 十、p-RNN [2016]
- 十一、GRU4Rec Top-k Gains [2018]
- 十二、SASRec [2018]
- 十三、RUM [2018]
- 十四、SHAN [2018]
- 十五、Phased LSTM [2016]
- 十六、Time-LSTM [2017]
- 十七、STAMP [2018]
- 十八、Latent Cross [2018]
- 十九、CSRM [2019]
- 二十、SR-GNN [2019]
- 二十一、GC-SAN [2019]
- 二十二、BERT4Rec [2019]
- 二十三、MCPRN [2019]
- 二十四、RepeatNet [2019]
- 二十五、LINet(2019)
- 二十六、NextItNet [2019]
- 二十七、GCE-GNN [2020]
- 二十八、LESSR [2020]
- 二十九、HyperRec [2020]
- 三十、DHCN [2021]
- 三十一、TiSASRec [2020]
- 推荐算法(综述)
- 多任务学习
- 系统架构
- 实践方法论
- 深度强化学习 1
- 自动代码生成
工具
- CRF
- lightgbm
- xgboost
- scikit-learn
- spark
- numpy
- matplotlib
- pandas
- huggingface_transformer
- 一、Tokenizer
- 二、Datasets
- 三、Model
- 四、Trainer
- 五、Evaluator
- 六、Pipeline
- 七、Accelerate
- 八、Autoclass
- 九、应用
- 十、Gradio
Scala
- 环境搭建
- 基础知识
- 函数
- 类
- 样例类和模式匹配
- 测试和注解
- 集合 collection(一)
- 集合collection(二)
- 集成 Java
- 并发
三、 函数库
1. 随机数库
numpy中的随机和分布函数模块有两种用法:函数式以及类式
1.1 函数式
随机数
numpy.random.rand(d0, d1, ..., dn):指定形状(d0, d1, ..., dn)创建一个随机的ndarray。每个元素值来自于半闭半开区间[0,1)并且服从均匀分布。- 要求
d0, d1, ..., dn为整数 - 如果未提供参数,则返回一个随机的浮点数而不是
ndarray,浮点数值来自于半闭半开区间[0,1)并且服从均匀分布。
- 要求
numpy.random.randn(d0, d1, ..., dn):指定形状(d0, d1, ..., dn)创建一个随机的ndarray。每个元素值服从正态分布,其中正态分布的期望为0,方差为1- 要求
d0, d1, ..., dn为整数或者可以转换为整数 - 如果
di为浮点数,则截断成整数 - 如果未提供参数,则返回一个随机的浮点数而不是
ndarray,浮点数值服从正态分布,其中正态分布的期望为0,方差为1
- 要求
numpy.random.randint(low[, high, size]):返回一个随机的整数ndarray或者一个随机的整数值。- 如果
high为None,则表示整数值都取自[0,low)且服从discrete uniform分布 - 如果
high给出了值,则表示整数值都取自[low,high)且服从discrete uniform分布 size是一个整数的元组,指定了输出的ndarray的形状。如果为None则表示输出为单个整数值
- 如果
numpy.random.random_integers(low[, high, size]):返回一个随机的整数ndarray或者一个随机的整数值。- 如果
high为None,则表示整数值都取自[1,low]且服从discrete uniform分布 - 如果
high给出了值,则表示整数值都取自[low,high]且服从discrete uniform分布 size是一个整数的元组,指定了输出的ndarray的形状。如果为None则表示输出为单个整数值
它与
randint区别在于randint是半闭半开区间,而random_integers是全闭区间- 如果
numpy.random.random_sample([size]):返回一个随机的浮点ndarray或者一个随机的浮点值,浮点值是[0.0,1.0)之间均匀分布的随机数size为整数元组或者整数,指定结果ndarray的形状。如果为None则只输出单个浮点数- 如果想生成
[a,b)之间均匀分布的浮点数,那么你可以用(b-a)*random_sample()+a
如果
size有效,它的效果等于numpy.random.rand(*size); 如果size无效,它的效果等于numpy.random.rand()
numpy.random.random([size]):等价于numpy.random.random_sample([size])numpy.random.ranf([size]):等价于numpy.random.random_sample([size])numpy.random.sample([size]):等价于numpy.random.random_sample([size])
numpy.random.choice(a[, size, replace, p]):从一维数组中采样产生一组随机数或者一个随机数a为一位数组或者int,如果是int则采样数据由numpy.arange(n)提供,否则采用数据由a提供size为整数元组或者整数,指定结果ndarray的形状。如果为None则只输单个值replace:如果为True则可以重复采样(有放回的采样);如果为False,则采用不放回的采样p:为一维数组,用于指定采样数组中每个元素值的采样概率。如果为None则均匀采样。如果参数有问题则抛出异常:比如
a为整数但是小于0,比如p不满足概率和为1,等等。。
numpy.random.bytes(length):返回length长度的随机字节串。length指定字节长度。
排列组合
numpy.random.shuffle(x):原地随机混洗x的内容,返回None。x为array-like对象,原地修改它numpy.random.permutation(x):随机重排x,返回重排后的ndarray。x为array-like对象,不会修改它如果
x是个整数,则重排numpy.arange(x)如果
x是个数组,则拷贝它然后对拷贝进行混洗- 如果
x是个多维数则只是混洗它的第0维
- 如果

概率分布函数:下面是共同参数:
size若非None,则它指定输出ndarray的形状。如果为None,则输出单个值。numpy.random.beta(a, b[, size]):Beta分布。其中a,b都是Beta分布的参数,要求非负浮点数。贝塔分布为:
$ f(x;\alpha,\beta)=\frac {1}{B(\alpha,\beta)} x^{\alpha-1}(1-x)^{\beta-1} $其中:
$ B(\alpha,\beta)=\int_0^{1} t^{\alpha-1}(1-t)^{\beta-1}\,dt $
numpy.random.binomial(n, p[, size]):二项分布。其中n,p都是二项分布的参数,要求n为大于等于0的浮点数,如果它为浮点数则截断为整数;p为[0,1]之间的浮点数。二项分布为:
$ P(N)=\binom{n}{N}p^{N}(1-p)^{n-N} $
numpy.random.chisquare(df[, size]):卡方分布。其中df为整数,是卡方分布的自由度(若小于等于0则抛出异常)。卡方分布为:
$ p(x)=\frac{(1/2)^{k/2}}{\Gamma(k/2)} x^{k/2-1}e^{-x/2} $其中
$ \Gamma(x)=\int^{\infty}_0 t^{x-1}e^{-t}\,dt $
numpy.random.dirichlet(alpha[, size]):狄利克雷分布。其中alpha是个数组,为狄利克雷分布的参数。numpy.random.exponential([scale, size]):指数分布。scale为浮点数,是参数 $ MathJax-Element-53 $指数分布的概率密度函数为:
$ f(x;\frac {1}{\beta})=\frac{1}{\beta}\exp(-\frac{x}{\beta}) $
numpy.random.f(dfnum, dfden[, size]):F分布。dfnum为浮点数,应该大于0,是分子的自由度;dfden是浮点数,应该大于0,是分母的自由度。numpy.random.gamma(shape[, scale, size]):伽玛分布。其中shape是个大于0的标量,表示分布的形状;scale是个大于0的标量,表示伽玛分布的scale(默认为1)。伽玛分布的概率密度函数为:
$ p(x)=x^{k-1} \frac {e^{-x/\theta}}{\theta^{k}\Gamma(k)} $,其中
k为形状, $ MathJax-Element-54 $ 为scale
numpy.random.geometric(p[, size]):几何分布。其中p是单次试验成功的概率。几何分布为:
$ f(k)=(1-p)^{k-1}p $
numpy.random.gumbel([loc, scale, size]):甘贝尔分布。其中loc为浮点数,是分布的location of mode,scale是浮点数,为scale。甘贝尔分布:
xxxxxxxxxx
p(x)=\frac {e^{-(x-\mu)/\beta}}{\beta} e^{-e-(x-\mu)/\beta} Preview $ p(x)=\frac {e^{-(x-\mu)/\beta}}{\beta} e^{-e-(x-\mu)/\beta} $ $ p(x)=\frac {e^{-(x-\mu)/\beta}}{\beta} e^{-e-(x-\mu)/\beta} $,其中 $ MathJax-Element-120 $ 为
location of mode, $ MathJax-Element-121 $ 为scale
numpy.random.hypergeometric(ngood, nbad, nsample[, size]): 超几何分布。其中ngood为整数或者array_like,必须非负数,为好的选择;nbad为整数或者array_like,必须非负数,表示坏的选择。超级几何分布:
$ P(x)= \frac {\binom{m}{n} \binom{N-m}{n-x}} {\binom{N}{n}}, 0 \le x \le m \ \text{and} \ n+m-N \le x \le n $,其中
n=ngood,m=nbad,N为样本数量。P(x)为x成功的概率
numpy.random.laplace([loc, scale, size]):拉普拉斯分布。loc为浮点数,scale为浮点数拉普拉斯分布:
$ f(x;\mu,\lambda)=\frac {1}{2\lambda} \exp(- \frac{\|x-\mu\|}{\lambda}) $,其中
loc= $ MathJax-Element-55 $ ,scale= $ MathJax-Element-56 $
numpy.random.logistic([loc, scale, size]):逻辑斯谛分布。其中loc为浮点数,scale为大于0的浮点数逻辑斯谛分布:
$ P(x)= \frac {e^{-(x-\mu)/s}}{s(1+e^{-(x-\mu)/s})^{2}} $, 其中
loc= $ MathJax-Element-73 $ ,scale= $ MathJax-Element-58 $
numpy.random.lognormal([mean, sigma, size]):对数正态分布。其中mean为浮点数,sigma为大于0的浮点数。对数正态分布:
$ p(x)=\frac {1}{\sigma x \sqrt{2\pi}} e^{-(\ln(x)-\mu)^{2}/(2\sigma^{2})} $,其中
mean= $ MathJax-Element-59 $ ,sigma= $ MathJax-Element-60 $
numpy.random.logseries(p[, size]):对数分布,其中p为[0.0--1.0]之间的浮点数。对数分布:
$ P(k)=\frac {-p^{k}}{k\ln(1-p)} $
numpy.random.multinomial(n, pvals[, size]):多项式分布。n为执行二项分布的试验次数,pvals为浮点序列,要求这些序列的和为1,其长度为n。numpy.random.multivariate_normal(mean, cov[, size]):多元正态分布。mean为一维数组,长度为N;cov为二维数组,形状为(N,N)numpy.random.negative_binomial(n, p[, size]):负二项分布。n为整数,大于0;p为[0.0--1.0]之间的浮点数。负二项分布:
$ P(N;n,p)=\binom{N+n-1}{n-1}p^{n}(1-p)^{N} $
numpy.random.noncentral_chisquare(df, nonc[, size]):非中心卡方分布。df为整数,必须大于0;noc为大于0的浮点数。非中心卡方分布:
$ P(x;k,\lambda)= \sum_{i=0}^{\infty } f_Y(x) \frac {e^{-\lambda/2}(-\lambda/2)^{i}}{i!} $其中 $ MathJax-Element-61 $ 为卡方分布,
df为k,nonc为 $ MathJax-Element-62 $
numpy.random.noncentral_f(dfnum, dfden, nonc[, size]):非中心F分布。其中dfnum为大于1的整数,dfden为大于1的整数,nonc为大于等于0的浮点数。numpy.random.normal([loc, scale, size]):正态分布。其中loc为浮点数,scale为浮点数。正态分布:
$ p(x)=\frac {1}{\sqrt{2\pi\sigma^{2}}}e^{-(x-\mu)^{2}/(2\sigma^{2})} $,其中
loc= $ MathJax-Element-73 $ ,scale= $ MathJax-Element-67 $
numpy.random.pareto(a[, size]):帕累托分布。其中a为浮点数。帕累托分布:
$ p(x)= \frac {\alpha m ^{\alpha}}{x^{\alpha+1}} $,其中
a= $ MathJax-Element-65 $ ,m为scale
numpy.random.poisson([lam, size]):泊松分布。其中lam为浮点数或者一个浮点序列(浮点数大于等于0)。泊松分布:
$ f(k;\lambda)=\frac {\lambda^{k}e^{-\lambda}}{k!} $,其中
lam= $ MathJax-Element-66 $
numpy.random.power(a[, size]):幂级数分布。其中a为大于0的浮点数。幂级数分布:
$ P(x;a)=ax^{a-1},0\le x \le 1,a \gt 0 $
numpy.random.rayleigh([scale, size]): 瑞利分布。其中scale为大于0的浮点数。瑞利分布:
$ P(x;\sigma)=\frac{x}{\sigma^{2}}e^{-x^{2}/(2\sigma^{2})} $,其中
scale= $ MathJax-Element-67 $
numpy.random.standard_cauchy([size]):标准柯西分布。柯西分布:
$ P(x;x_0,\gamma)=\frac{1}{\pi\gamma[1+((x-x_0)/\gamma)^{2}]} $,其中标准柯西分布中, $ MathJax-Element-68 $
numpy.random.standard_exponential([size]):标准指数分布。其中scale等于1numpy.random.standard_gamma(shape[, size]):标准伽玛分布,其中scale等于1numpy.random.standard_normal([size]):标准正态分布,其中mean=0,stdev等于1numpy.random.standard_t(df[, size]):学生分布。其中df是大于0的整数。学生分布:
$ f(t;\nu)=\frac{\Gamma((\nu+1)/2)}{\sqrt{\nu\pi}\Gamma(\nu/2)}(1+t^{2}/\nu)^{-(\nu+1)/2} $, 其中
df= $ MathJax-Element-69 $
numpy.random.triangular(left, mode, right[, size]): 三角分布。其中left为标量,mode为标量,right为标量- 三角分布(其中
left=l,mode=m,right=r):
- 三角分布(其中
numpy.random.uniform([low, high, size]):均匀分布。其中low为浮点数;high为浮点数。均匀分布:
$ p(x)=\frac {1}{b-a} $,其中
low=a,high=b
numpy.random.vonmises(mu, kappa[, size]):Mises分布。其中mu为浮点数,kappa为大于等于0的浮点数。
$ p(x)= \frac{e^{\kappa \cos(x-\mu)}}{2\pi I_0(\kappa)} $Mises分布:,其中
mu= $ MathJax-Element-73 $ ,kappa= $ MathJax-Element-71 $ , $ MathJax-Element-72 $ 是modified Bessel function of order 0
numpy.random.wald(mean, scale[, size]):Wald分布。其中mean为大于0的标量,scale为大于等于0的标量
$ P(x;\mu,\lambda)=\sqrt{\frac {\lambda}{2\pi x^{3}}} \exp \{\frac{-\lambda(x-\mu)^{2}}{2\mu^{2}x}\} $Wald分布:,其中
mean= $ MathJax-Element-73 $ ,scale= $ MathJax-Element-74 $
numpy.random.weibull(a[, size]):Weibull分布。其中a是个浮点数。
$ p(x)= \frac {a}{\lambda} (\frac {x}{\lambda})^{a-1} e^{-(x/\lambda)^{a}} $Weibull分布:,其中
a= $ MathJax-Element-75 $ , $ MathJax-Element-76 $ 为scale
numpy.random.zipf(a[, size]):齐夫分布。其中a为大于1的浮点数。齐夫分布:
$ p(x)=\frac {x^{-a}}{\zeta(a)} $,其中
a= $ MathJax-Element-77 $ , $ MathJax-Element-78 $ 为Riemann Zeta函数。
numpy.random.seed(seed=None):用于设置随机数生成器的种子。int是个整数或者数组,要求能转化成32位无符号整数。
1.2 RandomState类
类式用法主要使用
numpy.random.RandomState类,它是一个Mersenne Twister伪随机数生成器的容器。它提供了一些方法来生成各种各样概率分布的随机数。构造函数:
RandomState(seed)。其中seed可以为None,int,array_like。这个seed是初始化伪随机数生成器。如果seed为None,则RandomState会尝试读取/dev/urandom或者Windows analogure来读取数据,或用者clock来做种子。Python的stdlib模块random也提供了一个Mersenne Twister伪随机数生成器。但是RandomState提供了更多的概率分布函数。RandomState保证了通过使用同一个seed以及同样参数的方法序列调用会产生同样的随机数序列(除了浮点数精度上的区别)。RandomState提供了一些方法来产生各种分布的随机数。这些方法都有一个共同的参数size。- 如果
size为None,则只产生一个随机数 - 如果
size为一个整数,则产生一个一维的随机数数组。 - 如果
size为一个元组,则生成一个多维的随机数数组。其中数组的形状由元组指定。
- 如果
生成随机数的方法
.bytes(length):等效于numpy.random.bytes(...)函数.choice(a[, size, replace, p]):等效于numpy.random.choice(...)函数.rand(d0, d1, ..., dn):等效于numpy.random.rand(...)函数.randint(low[, high, size]):等效于numpy.random.randint(...)函数.randn(d0, d1, ..., dn):等效于numpy.random.randn(...)函数.random_integers(low[, high, size]):等效于numpy.random_integers.bytes(...)函数.random_sample([size]):等效于numpy.random.random_sample(...)函数.tomaxint([size]):等效于numpy.random.tomaxint(...)函数
排列组合的方法
.shuffle(x):等效于numpy.random.shuffle(...)函数.permutation(x):等效于numpy.random.permutation(...)函数
指定概率分布函数的方法
.beta(a, b[, size]):等效于numpy.random.beta(...)函数.binomial(n, p[, size]):等效于numpy.random.binomial(...)函数.chisquare(df[, size]):等效于numpy.random.chisquare(...)函数.dirichlet(alpha[, size]):等效于numpy.random.dirichlet(...)函数.exponential([scale, size]):等效于numpy.random.exponential(...)函数.f(dfnum, dfden[, size]):等效于numpy.random.f(...)函数.gamma(shape[, scale, size]):等效于numpy.random.gamma(...)函数.geometric(p[, size]):等效于numpy.random.geometric(...)函数.gumbel([loc, scale, size]):等效于numpy.random.gumbel(...)函数.hypergeometric(ngood, nbad, nsample[, size]):等效于numpy.random.hypergeometric(...)函数.laplace([loc, scale, size]):等效于numpy.random.laplace(...)函数.logistic([loc, scale, size]):等效于numpy.random.logistic(...)函数.lognormal([mean, sigma, size]):等效于numpy.random.lognormal(...)函数.logseries(p[, size]):等效于numpy.random.logseries(...)函数.multinomial(n, pvals[, size]):等效于numpy.random.multinomial(...)函数.multivariate_normal(mean, cov[, size]):等效于numpy.random.multivariate_normal(...)函数.negative_binomial(n, p[, size]):等效于numpy.random.negative_binomial(...)函数.noncentral_chisquare(df, nonc[, size]):等效于numpy.random.noncentral_chisquare(...)函数.noncentral_f(dfnum, dfden, nonc[, size]):等效于numpy.random.noncentral_f(...)函数.normal([loc, scale, size]):等效于numpy.random.normal(...)函数.pareto(a[, size]):等效于numpy.random.pareto(...)函数 -. poisson([lam, size]):等效于numpy.random.poisson(...)函数.power(a[, size]):等效于numpy.random.power(...)函数.rayleigh([scale, size]):等效于numpy.random.rayleigh(...)函数.standard_cauchy([size]):等效于numpy.random.standard_cauchy(...)函数.standard_exponential([size]):等效于numpy.random.standard_exponential(...)函数.standard_gamma(shape[, size]):等效于numpy.random.standard_gamma(...)函数.standard_normal([size]):等效于numpy.random.standard_normal(...)函数.standard_t(df[, size]):等效于numpy.random.standard_t(...)函数.triangular(left, mode, right[, size]):等效于numpy.random.triangular(...)函数.uniform([low, high, size]):等效于numpy.random.uniform(...)函数.vonmises(mu, kappa[, size]):等效于numpy.random.vonmises(...)函数.wald(mean, scale[, size]):等效于numpy.random.wald(...)函数.weibull(a[, size]):等效于numpy.random.weibull(...)函数.zipf(a[, size]):等效于numpy.random.zipf(...)函数
类式的其他函数
seed(seed=None):该方法在RandomState被初始化时自动调用,你也可以反复调用它从而重新设置伪随机数生成器的种子。get_state():该方法返回伪随机数生成器的内部状态。其结果是一个元组(str, ndarray of 624 uints, int, int, float),依次为:- 字符串
'MT19937' - 一维数组,其中是624个无符号整数
key - 一个整数
pos - 一个整数
has_gauss - 一个浮点数
cached_gaussian
- 字符串
set_state(state):该方法设置伪随机数生成器的内部状态,如果执行成功则返回None。参数是个元组(str, ndarray of 624 uints, int, int, float),依次为:- 字符串
'MT19937' - 一维数组,其中是624个无符号整数
key - 一个整数
pos - 一个整数
has_gauss - 一个浮点数
cached_gaussian
- 字符串
2. 统计量
这里是共同的参数:
a:一个array_like对象axis:可以为为int或者tuple或者None:None:将a展平,在整个数组上操作int:在a的指定轴线上操作。如果为-1,表示沿着最后一个轴(0轴为第一个轴)。tuple of ints:在a的一组指定轴线上操作
out:可选的输出位置。必须与期望的结果形状相同keepdims:如果为True,则结果数组的维度与原数组相同,从而可以与原数组进行广播运算。
顺序统计:
numpy.minimum(x1, x2[, out]):返回两个数组x1和x2对应位置的最小值。要求x1和x2形状相同或者广播之后形状相同。numpy.maximum(x1, x2[, out]):返回两个数组x1和x2对应位置的最大值。要求x1和x2形状相同或者广播之后形状相同。numpy.amin(a[, axis, out, keepdims]):返回a中指定轴线上的最小值(数组)、或者返回a上的最小值(标量)。numpy.amax(a[, axis, out, keepdims]):返回a中指定轴线上的最大值(数组)、或者返回a上的最小值(标量)。numpy.nanmin(a[, axis, out, keepdims]): 返回a中指定轴线上的最小值(数组)、或者返回a上的最小值(标量),忽略NaN。numpy.nanmax(a[, axis, out, keepdims]):返回a中指定轴线上的最大值(数组)、或者返回a上的最小值(标量)忽略NaN。numpy.ptp(a[, axis, out]):返回a中指定轴线上的最大值减去最小值(数组),即peak to peaknumpy.argmin(a, axis=None, out=None):返回a中指定轴线上最小值的下标numpy.argmax(a, axis=None, out=None):返回a中指定轴线上最大值的下标numpy.percentile(a, q[, axis, out, ...]):返回a中指定轴线上qth 百分比数据。q=50表示 50% 分位。你可以用列表或者数组的形式一次指定多个q。numpy.nanpercentile(a, q[, axis, out, ...]):返回a中指定轴线上qth 百分比数据。q=50表示 50% 分位。numpy.partition(a, kth, axis=-1, kind='introselect', order=None):它将数组执行划分操作:第 $ MathJax-Element-82 $ 位左侧的数都小于第 $ MathJax-Element-82 $ ;第 $ MathJax-Element-82 $ 位右侧的数都大于等于第 $ MathJax-Element-82 $ 。它返回划分之后的数组numpy.argpartition(a, kth, axis=-1, kind='introselect', order=None):返回执行划分之后的下标(对应于数组划分之前的位置)。

排序:
numpy.sort(a, axis=-1, kind='quicksort', order=None):返回a在指定轴上排序后的结果(并不修改原数组)。kind:字符串指定排序算法。可以为'quicksort'(快速排序),'mergesort'(归并排序),'heapsort'(堆排序)order:在结构化数组中排序中,用于设置排序的字段(一个字符串)
numpy.argsort(a, axis=-1, kind='quicksort', order=None):返回a在指定轴上排序之后的下标(对应于数组划分之前的位置)。numpy.lexsort(keys, axis=-1):- 如果
keys为数组,则根据数组的最后一个轴的最后一排数值排列,并返回这些轴的排列顺序。如数组a的shape=(4,5),则根据a最后一行(对应于最后一个轴的最后一排)的5列元素排列。这里axis指定排序的轴 。对于argsort,会在最后一个轴的每一排进行排列并返回一个与a形状相同的数组。 - 如果
keys为一维数组的元组,则将这些一维数组当作行向量拼接成二维数组并按照数组来操作。
- 如果
numpy.searchsorted(a, v, side='left', sorter=None):要求a是个已排序好的一维数组。本函数将v插入到a中,从而使得数组a维持一个排序好的数组。函数返回的是v应该插入的位置。side指定若发现数值相等时,插入左侧left还是右侧right- 如果你想一次插入多个数值,可以将
v设置为列表或者数组。 - 如果
sorter=None,则要求a已排序好。如果a未排序,则要求传入一个一维数组或者列表。这个一维数组或者列表给出了a的升序排列的下标。(通常他就是argsort的结果) - 它并不执行插入操作,只是返回待插入的位置
- 如果你想一次插入多个数值,可以将


均值和方差:
numpy.sum(a, axis=None, dtype=None, out=None, keepdims=False):计算a在指定轴上的和numpy.prod(a, axis=None, dtype=None, out=None, keepdims=False):计算a在指定轴上的乘积numpy.median(a[, axis, out, overwrite_input, keepdims]):计算a在指定轴上的中位数(如果有两个,则取这两个的平均值)numpy.average(a[, axis, weights, returned]):计算a在指定轴上的加权平均数numpy.mean(a[, axis, dtype, out, keepdims]):计算a在指定轴上的算术均值numpy.std(a[, axis, dtype, out, ddof, keepdims]):计算a在指定轴上的标准差numpy.var(a[, axis, dtype, out, ddof, keepdims]):计算a在指定轴上的方差。方差有两种定义:偏样本方差
$ var=\frac 1N\sum_{i=1}^{N}(x_i-\bar x)^{2} $biased sample variance。计算公式为 ( $ MathJax-Element-84 $ 为均值):无偏样本方差
$ var=\frac 1{N-1}\sum_{i=1}^{N}(x_i-\bar x)^{2} $unbiased sample variance。计算公式为 ( $ MathJax-Element-84 $ 为均值):当
ddof=0时,计算偏样本方差;当ddof=1时,计算无偏样本方差。默认值为 0。当ddof为其他整数时,分母就是N-ddof。
numpy.nanmedian(a[, axis, out, overwrite_input, ...]):计算a在指定轴上的中位数,忽略NaNnumpy.nanmean(a[, axis, dtype, out, keepdims]):计算a在指定轴上的算术均值,忽略NaNnumpy.nanstd(a[, axis, dtype, out, ddof, keepdims]):计算a在指定轴上的标准差,忽略NaNnumpy.nanvar(a[, axis, dtype, out, ddof, keepdims]):计算a在指定轴上的方差,忽略NaN

相关系数:
numpy.corrcoef(x[, y, rowvar, bias, ddof]): 返回皮尔逊积差相关numpy.correlate(a, v[, mode]):返回两个一维数组的互相关系数numpy.cov(m[, y, rowvar, bias, ddof, fweights, ...]):返回协方差矩阵
直方图:
numpy.unique(ar, return_index=False, return_inverse=False, return_counts=False):返回ar中所有不同的值组成的一维数组。如果ar不是一维的,则展平为一维。return_index:如果为True,则同时返回这些独一无二的数值在原始数组中的下标return_inverse:如果为True,则返回元素数组的值在新返回数组中的下标(从而可以重建元素数组)return_counts:如果为True,则返回每个独一无二的值在原始数组中出现的次数
numpy.histogram(a, bins=10, range=None, normed=False, weights=None, density=None):计算一组数据的直方图。如果a不是一维的,则展平为一维。bins指定了统计的区间个数(即统计范围的等分数)。range是个长度为2的元组,表示统计范围的最小值和最大值(默认时,表示范围为数据的最小值和最大值)。当density为False时,返回a中数据在每个区间的个数;否则返回a中数据在每个区间的频率。weights设置了a中每个元素的权重,如果设置了该参数,则计数时考虑权重。它返回的是一个元组,第一个元素给出了每个直方图的计数值,第二个元素给出了直方图的统计区间的从左到右的各个闭合点 (比计数值的数量多一个)。normed:作用与density相同。该参数将被废弃bins也可以为下列字符串,此时统计区间的个数将通过计算自动得出。可选的字符串有:'auto'、'fd'、'doane'、'scott'、'rice'、'sturges'、'sqrt'
numpy.histogram2d(x, y, bins=10, range=None, normed=False, weights=None):计算两组数据的二维直方图numpy.histogramdd(sample, bins=10, range=None, normed=False, weights=None):计算多维数据的直方图numpy.bincount(x[, weights, minlength]):计算每个数出现的次数。它要求数组中所有元素都是非负的。其返回数组中第i个元素表示:整数i在x中出现的次数。要求x必须一维数组,否则报错。weights设置了x中每个元素的权重,如果设置了该参数,则计数时考虑权重。minlength指定结果的一维数组最少多长(如果未指定,则由x中最大的数决定)。numpy.digitize(x, bins, right=False):离散化。如果x不是一维的,则展平为一维。它返回一个数组,该数组中元素值给出了x中的每个元素将对应于统计区间的哪个区间。区间由bins这个一维数组指定,它依次给出了统计区间的从左到右的各个闭合点。right为True,则表示统计区间为左开右闭合(];为False,则表示统计区间为左闭合右开[)
注意:
matplotlib.pyplot也有一个建立直方图的函数(hist(...)),区别在于matplotlib.pyplot.hist(...)函数会自动绘直方图,而numpy.histogram仅仅产生数据

3. 分段函数
numpy.where(condition[, x, y]):它类似于python的x if condition else y。condition/x/y都是数组,要求形状相同或者通过广播之后形状相同。产生结果的方式为: 如果condition某个元素为True或者非零,则对应的结果元素从x中获取;否则对应的结果元素从y中获取
如果分段数量增加,则需要嵌套多层的
where()。此时可以使用select():numpy.select(condlist, choicelist, default=0)。其中
condlist为长度为N的列表,列表元素为数组,给出了条件数组choicelist为长度为N的列表,列表元素为数组,给出了结果被选中的候选值。所有数组的长度都形状相同,如果形状不同,则执行广播。结果数组的形状为广播之后的形状。
结果筛选规则如下:
- 从
condlist左到右扫描,若发现第i个元素(是个数组)对应位置为True或者非零,则输出元素来自choicelist的第i个元素(是个数组)。因此若有多个condlist的元素满足,则只会使用第一个遇到的。 - 如果扫描结果是都不满足,则使用
default
- 从
采用
where/select时,所有的参数需要在调用它们之前完成。在计算时还会产生许多保存中间结果的数组。因此如果输入数组很大,则将会发生大量内存分配和释放。 为此numpy提供了piecewise函数:numpy.piecewise(x, condlist, funclist, *args, **kw)。x:为分段函数的自变量取值数组condlist:为一个列表,列表元素为布尔数组,数组形状和x相同。funclist:为一个列表,列表元素为函数对象。其长度与condlist相同或者比它长1。- 当
condlist[i]对应位置为True时,则该位置处的输出值由funclist[i]来计算。如果funclist长度比condlist长1,则当所有的condlist都是False时,则使用funclist[len(condlist)]来计算。如果有多个符合条件,则使用最后一个遇到的(而不是第一个遇到的) - 列表元素可以为数值,表示一个返回为常数值(就是该数值)的函数。
- 当
args/kw:用于传递给函数对象funclist[i]的额外参数。
4. 多项式
一元多项式类的构造:(注意系数按照次数从高次到低次排列)
xxxxxxxxxx
class numpy.poly1d(c_or_r, r=0, variable=None)c_or_r:一个数组或者序列。其意义取决于rr:布尔值。如果为True,则c_or_r指定的是多项式的根;如果为False,则c_or_r指定的是多项式的系数variable:一个字符串,指定了打印多项式时,用什么字符代表自变量。默认为x
多项式的属性有:
.coeffs属性:多项式的系数.order属性:多项式最高次的次数.variable属性:自变量的代表字符
多项式的方法有:
.deriv(m=1)方法:计算多项式的微分。可以通过参数m指定微分次数.integ(m=1,k=0)方法:计算多项式的积分。可以通过参数m指定积分次数和k积分常量

操作一元多项式类的函数:
- 多项式对象可以像函数一样,返回多项式的值
- 多项式对象进行加减乘除,相当于对应的多项式进行计算。也可以使用对应的
numpy.polyadd/polysub/polymul/polydiv/函数。 numpy.polyder/numpy.polyint:进行微分/积分操作numpy.roots函数:求多项式的根(也可以通过p.r方法)

使用
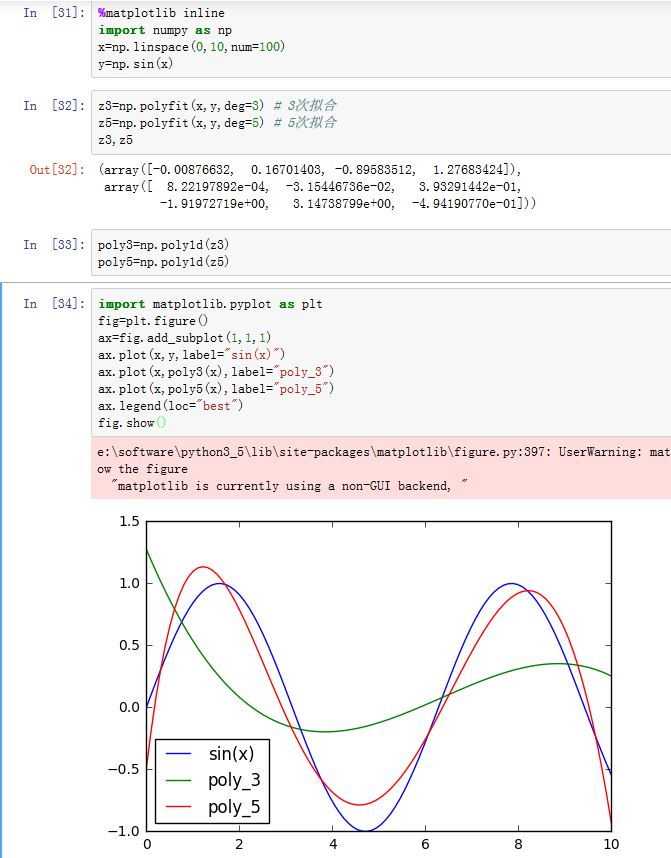
np.polyfit(x, y, deg, rcond=None, full=False, w=None, cov=False)函数可以对一组数据使用多项式函数进行拟合(最小均方误差)。其参数为:x:数据点的x坐标序列y:数据点的y坐标序列。如果某个x坐标由两个点,你可以传入一个二维数组。deg:拟合多项式的次数rcond:指定了求解过程中的条件:当某个特征值/最大特征值<rcond时,该特征值被抛弃full:如果为False,则仅仅返回拟合多项式的系数;如果为True,则更多的结果被返回w:权重序列。它对y序列的每个位置赋予一个权重cov:如果为True,则返回相关矩阵。如果full为True,则不返回。
默认情况下,返回两个数组:一个是拟合多项式的系数;另一个是数据的相关矩阵

numpy提供了更丰富的多项式函数类。注意其中的多项式的系数按照次数从小到大排列。numpy.polynomial.Polynomial:一元多次多项式numpy.polynomial.Chebyshev:切比雪夫多项式numpy.polynomial.Laguerre:拉盖尔多项式numpy.polynomial.Legendre:勒让德多项式numpy.polynomial.Hermite:哈米特多项式numpy.polynomial.HermiteE:HermiteE多项式
所有的这些多项式的构造函数为:
XXX(coef, domain=None, window=None)。其中XXX为多项式类名。domain为自变量取值范围,默认为[-1,1]。window指定了将domain映射到的范围,默认为[-1,1]。如切比雪夫多项式在
[-1,1]上为正交多项式。因此只有在该区间上才能正确插值拟合多项式。为了使得对任何区域的目标函数进行插值拟合,所以在domain指定拟合的目标区间。所有的这些多项式可以使用的方法为:
- 四则运行
.basis(deg[, domain, window]):获取转换后的一元多项式.convert(domain=None, kind=None, window=None):转换为另一个格式的多项式。kind为目标格式的多项式的类.degree():返回次数.fit(x, y, deg[, domain, rcond, full, w, window]):拟合数据,返回拟合后的多项式.fromroots(roots[, domain, window]):从根创建多项式.has_samecoef(other)、.has_samedomain(other)、.has_sametype(other)、.has_samewindow(other):判断是否有相同的系数/domain/类型/window.roots():返回多项式的根.trim([tol]):将系数小于tol的项截掉- 函数调用的方式
](https://www.wenjiangs.com/wp-content/uploads/2023/docimg23/1913-axvwav3mhlb.JPG)
切比雪夫多项式可以降低龙格现象。所谓龙格现象:等距离差值多项式在两个端点处有非常大的震荡,
n越大,震荡越大。
5. 内积、外积、张量积
numpy.dot(a, b, out=None):计算矩阵的乘积。对于一维数组,他计算的是内积;对于二维数组,他计算的是线性代数中的矩阵乘法。numpy.vdot(a, b):返回一维向量之间的点积。如果a和b是多维数组,则展平成一维再点积。
numpy.inner(a, b):计算矩阵的内积。对于一维数组,它计算的是向量点积;对于多维数组,则它计算的是:每个数组最后轴作为向量,由此产生的内积。numpy.outer(a, b, out=None):计算矩阵的外积。它始终接收一维数组。如果是多维数组,则展平成一维数组。

numpy.tensordot(a, b, axes=2):计算张量乘积。axes如果是个二元序列,则第一个元素表示a中的轴;第二个元素表示b中的轴。将这两个轴上元素相乘之后求和。其他轴不变axes如果是个整数,则表示把a中的后axes个轴和b中的前axes个轴进行乘积之后求和。其他轴不变
叉乘:
numpy.cross(a, b, axisa=-1, axisb=-1, axisc=-1, axis=None):计算两个向量之间的叉乘。叉积用于判断两个三维空间的向量是否垂直。要求a和b都是二维向量或者三维向量,否则抛出异常。(当然他们也可以是二维向量的数组,或者三维向量的数组,此时一一叉乘)
6. 线性代数
逆矩阵:
numpy.linalg.inv(a):获取a的逆矩阵(一个array-like对象)。如果传入的是多个矩阵,则依次计算这些矩阵的逆矩阵。
如果
a不是方阵,或者a不可逆则抛出异常
单位矩阵:
numpy.eye(N[, M, k, dtype]):返回一个二维单位矩阵行为N,列为M,对角线元素为1,其余元素为0。M默认等于N。k默认为0表示对角线元素为1(单位矩阵),如为正数则表示对角线上方一格的元素为1(上单位矩阵),如为负数表示对角线下方一格的元素为1(下单位矩阵)对角线和:
numpy.trace(a, offset=0, axis1=0, axis2=1, dtype=None, out=None):返回对角线的和。- 如果
a是二维的,则直接选取对角线的元素之和(offsert=0),或者对角线右侧偏移offset的元素之和(即选取a[i,i+offset]之和)
- 如果
如果
a不止二维,则由axis1和axis2指定的轴选取了取对角线的矩阵。如果
a少于二维,则抛出异常
计算线性方程的解 $ MathJax-Element-85 $ :
numpy.linalg.solve(a,b):计算线性方程的解ax=b,其中a为矩阵,要求为秩不为0的方阵,b为列向量(长度等于方阵大小);或者a为标量,b也为标量。- 如果
a不是方阵或者a是方阵但是行列式为0,则抛出异常

- 如果
特征值:
numpy.linalg.eig(a):计算矩阵的特征值和右特征向量。如果不是方阵则抛出异常,如果行列式为0则抛出异常。
奇异值分解:
numpy.linalg.svd(a, full_matrices=1, compute_uv=1):对矩阵a进行奇异值分解,将它分解成u*np.diag(s)*v的形式,其中u和v是酉矩阵,s是a的奇异值组成的一维数组。 其中:full_matrics:如果为True,则u形状为(M,M),v形状为(N,N);否则u形状为(M,K),v形状为(K,N),K=min(M,N)compute_uv:如果为True则表示要计算u和v。默认为True。- 返回
u、s、v的元组 - 如果不可分解则抛出异常

如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!
发布评论