- Introduction to Python
- Getting started with Python and the IPython notebook
- Functions are first class objects
- Data science is OSEMN
- Working with text
- Preprocessing text data
- Working with structured data
- Using SQLite3
- Using HDF5
- Using numpy
- Using Pandas
- Computational problems in statistics
- Computer numbers and mathematics
- Algorithmic complexity
- Linear Algebra and Linear Systems
- Linear Algebra and Matrix Decompositions
- Change of Basis
- Optimization and Non-linear Methods
- Practical Optimizatio Routines
- Finding roots
- Optimization Primer
- Using scipy.optimize
- Gradient deescent
- Newton’s method and variants
- Constrained optimization
- Curve fitting
- Finding paraemeters for ODE models
- Optimization of graph node placement
- Optimization of standard statistical models
- Fitting ODEs with the Levenberg–Marquardt algorithm
- 1D example
- 2D example
- Algorithms for Optimization and Root Finding for Multivariate Problems
- Expectation Maximizatio (EM) Algorithm
- Monte Carlo Methods
- Resampling methods
- Resampling
- Simulations
- Setting the random seed
- Sampling with and without replacement
- Calculation of Cook’s distance
- Permutation resampling
- Design of simulation experiments
- Example: Simulations to estimate power
- Check with R
- Estimating the CDF
- Estimating the PDF
- Kernel density estimation
- Multivariate kerndel density estimation
- Markov Chain Monte Carlo (MCMC)
- Using PyMC2
- Using PyMC3
- Using PyStan
- C Crash Course
- Code Optimization
- Using C code in Python
- Using functions from various compiled languages in Python
- Julia and Python
- Converting Python Code to C for speed
- Optimization bake-off
- Writing Parallel Code
- Massively parallel programming with GPUs
- Writing CUDA in C
- Distributed computing for Big Data
- Hadoop MapReduce on AWS EMR with mrjob
- Spark on a local mahcine using 4 nodes
- Modules and Packaging
- Tour of the Jupyter (IPython3) notebook
- Polyglot programming
- What you should know and learn more about
- Wrapping R libraries with Rpy
Obtaining data
Data may be generated from clinical trials, scientific experiments, surveys, web pages, computer simulations etc. There are many ways that data can be stored, and part of the initial challenge is simply reading in the data so that it can be analysed.
Remote data
Alternatives using command line commandes
! wget http://www.gutenberg.org/cache/epub/11/pg11.txt -O alice.txt
--2015-01-14 20:23:09-- http://www.gutenberg.org/cache/epub/11/pg11.txt Resolving www.gutenberg.org... 152.19.134.47, 152.19.134.47 Connecting to www.gutenberg.org|152.19.134.47|:80... connected. HTTP request sent, awaiting response... 200 OK Length: 167518 (164K) [text/plain] Saving to: ‘alice.txt’ 100%[======================================>] 167,518 677KB/s in 0.2s 2015-01-14 20:23:11 (677 KB/s) - ‘alice.txt’ saved [167518/167518]
! curl http://www.gutenberg.org/cache/epub/11/pg11.txt > alice.txt
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 163k 100 163k 0 0 416k 0 --:--:-- --:--:-- --:--:-- 418k
Alternatives Using Python
import urllib2
text = urllib2.urlopen('http://www.gutenberg.org/cache/epub/11/pg11.txt').read()
import requests
test = requests.get('http://www.gutenberg.org/cache/epub/11/pg11.txt').text
Plain text files
We can open plain text files with the open function. This is a common and very flexible format, but because no structure is involved, custom processing methods to extract the information needed may be necessary.
Example 1 : Suppose we want to find out how often the words alice and drink occur in the same sentence in Alice in Wonderland.
# We first need to get the book from Project Gutenburg
import os
if not os.path.exists('alice.txt'):
! wget http://www.gutenberg.org/cache/epub/11/pg11.txt -O alice.txt
# now read the book into memory, clean out blank lines and convert to lowercase
alice = open('alice.txt', 'r').read().replace('\r\n', ' ').lower()
# split into sentence # simplistically assume that every sentence ends with a '.', '?' or '!' import re stop_pattern = '\.|\?|\!' sentences = re.split(stop_pattern, alice)
# find sentences that contain both 'alice' and 'drink'
print
for i, sentence in enumerate(sentences):
if 'alice' in sentence and 'drink' in sentence:
print i, sentence, '\n'
66 there seemed to be no use in waiting by the little door, so she went back to the table, half hoping she might find another key on it, or at any rate a book of rules for shutting people up like telescopes: this time she found a little bottle on it, ('which certainly was not here before,' said alice,) and round the neck of the bottle was a paper label, with the words 'drink me' beautifully printed on it in large letters
67 it was all very well to say 'drink me,' but the wise little alice was not going to do that in a hurry
469 alice looked all round her at the flowers and the blades of grass, but she did not see anything that looked like the right thing to eat or drink under the circumstances
882 ' said alice, who always took a great interest in questions of eating and drinking
Delimited files
Plain text files can also have a delimited structure - basically a table with rows and columns, where eacy column is separated by some separator, commonly a comma (CSV) or tab. There may or may not be additional comments or a header row in the file.
%%file example.csv # This is a comment # This is another comment alice,60,1.56 bob,72,1.75 david,84,1.82
Overwriting example.csv
# Using line by line parsing
import csv
with open('example.csv') as f:
# use a generator expression to strip out comments
for line in csv.reader(row for row in f if not row.startswith('#')):
name, wt, ht = line
wt, ht = map(float, (wt, ht))
print 'BMI of %s = %.2f' % (name, wt/(ht*ht))
BMI of alice = 24.65 BMI of bob = 23.51 BMI of david = 25.36
# Often it is most convenient to read it into a Pandas dataframe
import pandas as pd
df = pd.read_csv('example.csv', comment='#', header=None)
df.columns = ['name', 'wt', 'ht']
df['bmi'] = df['wt']/(df['ht']*df['ht'])
df
| name | wt | ht | bmi | |
|---|---|---|---|---|
| 0 | alice | 60 | 1.56 | 24.654832 |
| 1 | bob | 72 | 1.75 | 23.510204 |
| 2 | david | 84 | 1.82 | 25.359256 |
JSON files
JSON is JavaScript Object Notation - a format used widely for web-based resource sharing. It is very similar in structure to a Python nested dictionary. Here is an example from http://json.org/example
%%file example.json
{
"glossary": {
"title": "example glossary",
"GlossDiv": {
"title": "S",
"GlossList": {
"GlossEntry": {
"ID": "SGML",
"SortAs": "SGML",
"GlossTerm": "Standard Generalized Markup Language",
"Acronym": "SGML",
"Abbrev": "ISO 8879:1986",
"GlossDef": {
"para": "A meta-markup language, used to create markup languages such as DocBook.",
"GlossSeeAlso": ["GML", "XML"]
},
"GlossSee": "markup"
}
}
}
}
}
Overwriting example.json
import json
data = json.load(open('example.json'))
# data is a nested Python dictionary data
{u'glossary': {u'GlossDiv': {u'GlossList': {u'GlossEntry': {u'Abbrev': u'ISO 8879:1986',
u'Acronym': u'SGML',
u'GlossDef': {u'GlossSeeAlso': [u'GML', u'XML'],
u'para': u'A meta-markup language, used to create markup languages such as DocBook.'},
u'GlossSee': u'markup',
u'GlossTerm': u'Standard Generalized Markup Language',
u'ID': u'SGML',
u'SortAs': u'SGML'}},
u'title': u'S'},
u'title': u'example glossary'}}
# and can be parsed using standard key lookups data['glossary']['GlossDiv']['GlossList']
{u'GlossEntry': {u'Abbrev': u'ISO 8879:1986',
u'Acronym': u'SGML',
u'GlossDef': {u'GlossSeeAlso': [u'GML', u'XML'],
u'para': u'A meta-markup language, used to create markup languages such as DocBook.'},
u'GlossSee': u'markup',
u'GlossTerm': u'Standard Generalized Markup Language',
u'ID': u'SGML',
u'SortAs': u'SGML'}}
Web scraping
Sometimes we want to get data from a web page that does not provide an API to do so programmatically. In such cases, we have to resort to web scraping.
!pip install Scrapy
Requirement already satisfied (use --upgrade to upgrade): Scrapy in /Users/cliburn/anaconda/lib/python2.7/site-packages Cleaning up...
if os.path.exists('dmoz'):
%rm -rf dmoz
! scrapy startproject dmoz
New Scrapy project 'dmoz' created in:
/Users/cliburn/git/STA663-2015/Lectures/Topic03_Data_Munging/dmoz
You can start your first spider with:
cd dmoz
scrapy genspider example example.com
%%file dmoz/dmoz/items.py
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
Overwriting dmoz/dmoz/items.py
%%file dmoz/dmoz/spiders/dmoz_spider.py
import scrapy
from dmoz.items import DmozItem
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
for sel in response.xpath('//ul/li'):
item = DmozItem()
item['title'] = sel.xpath('a/text()').extract()
item['link'] = sel.xpath('a/@href').extract()
item['desc'] = sel.xpath('text()').extract()
yield item
Writing dmoz/dmoz/spiders/dmoz_spider.py
%%bash cd dmoz scrapy crawl dmoz --nolog -o scraped_data.json
dmoz = json.load(open('dmoz/scraped_data.json'))
for item in dmoz:
if item['title'] and item['link']:
if item['link'][0].startswith('http'):
print '%s: %s' % (item['title'][0], item['link'][0])
eff-bot's Daily Python URL: http://www.pythonware.com/daily/ Free Python and Zope Hosting Directory: http://www.oinko.net/freepython/ O'Reilly Python Center: http://oreilly.com/python/ Python Developer's Guide: https://www.python.org/dev/ Social Bug: http://win32com.goermezer.de/ Core Python Programming: http://www.pearsonhighered.com/educator/academic/product/0,,0130260363,00%2Ben-USS_01DBC.html Data Structures and Algorithms with Object-Oriented Design Patterns in Python: http://www.brpreiss.com/books/opus7/html/book.html Dive Into Python 3: http://www.diveintopython.net/ Foundations of Python Network Programming: http://rhodesmill.org/brandon/2011/foundations-of-python-network-programming/ Free Python books: http://www.techbooksforfree.com/perlpython.shtml FreeTechBooks: Python Scripting Language: http://www.freetechbooks.com/python-f6.html How to Think Like a Computer Scientist: Learning with Python: http://greenteapress.com/thinkpython/ An Introduction to Python: http://www.network-theory.co.uk/python/intro/ Learn to Program Using Python: http://www.freenetpages.co.uk/hp/alan.gauld/ Making Use of Python: http://www.wiley.com/WileyCDA/WileyTitle/productCd-0471219754.html Practical Python: http://hetland.org/writing/practical-python/ Pro Python System Administration: http://sysadminpy.com/ Programming in Python 3 (Second Edition): http://www.qtrac.eu/py3book.html Python 2.1 Bible: http://www.wiley.com/WileyCDA/WileyTitle/productCd-0764548077.html Python 3 Object Oriented Programming: https://www.packtpub.com/python-3-object-oriented-programming/book Python Language Reference Manual: http://www.network-theory.co.uk/python/language/ Python Programming Patterns: http://www.pearsonhighered.com/educator/academic/product/0,,0130409561,00%2Ben-USS_01DBC.html Python Programming with the Java Class Libraries: A Tutorial for Building Web and Enterprise Applications with Jython: http://www.informit.com/store/product.aspx?isbn=0201616165&redir=1 Python: Visual QuickStart Guide: http://www.pearsonhighered.com/educator/academic/product/0,,0201748843,00%2Ben-USS_01DBC.html Sams Teach Yourself Python in 24 Hours: http://www.informit.com/store/product.aspx?isbn=0672317354 Text Processing in Python: http://gnosis.cx/TPiP/ XML Processing with Python: http://www.informit.com/store/product.aspx?isbn=0130211192
HDF5
HDF5 is a hierarchical format often used to store complex scientific data. For instance, Matlab now saves its data to HDF5. It is particularly useful to store complex hierarchical data sets with associated metadata, for example, the results of a computer simulation experiment.
The main concepts associated with HDF5 are
- file: container for hierachical data - serves as ‘root’ for tree
- group: a node for a tree
- dataset: array for numeric data - can be huge
- attribute: small pieces of metadata that provide additional context
import h5py import numpy as np
# creating a HDF5 file
import datetime
if not os.path.exists('example.hdf5'):
with h5py.File('example.hdf5') as f:
project = f.create_group('project')
project.attrs.create('name', 'My project')
project.attrs.create('date', str(datetime.date.today()))
expt1 = project.create_group('expt1')
expt2 = project.create_group('expt2')
expt1.create_dataset('counts', (100,), dtype='i')
expt2.create_dataset('values', (1000,), dtype='f')
expt1['counts'][:] = range(100)
expt2['values'][:] = np.random.random(1000)
with h5py.File('example.hdf5') as f:
project = f['project']
print project.attrs['name']
print project.attrs['date']
print project['expt1']['counts'][:10]
print project['expt2']['values'][:10]
My project 2014-12-17 [0 1 2 3 4 5 6 7 8 9] [ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
Relational databases
Relational databases are comprised of tables, where each row consists of a tuple of columns. Each row is uniquely identified by a primary key, and tables can be linked via foreign keys.
We will illustrate the concepts of table querying the Chinook database . From the online description, “The Chinook data model represents a digital media store, including tables for artists, albums, media tracks, invoices and customers.”
from IPython.display import Image Image(url='http://lh4.ggpht.com/_oKo6zFhdD98/SWFPtyfHJFI/AAAAAAAAAMc/GdrlzeBNsZM/s800/ChinookDatabaseSchema1.1.png')
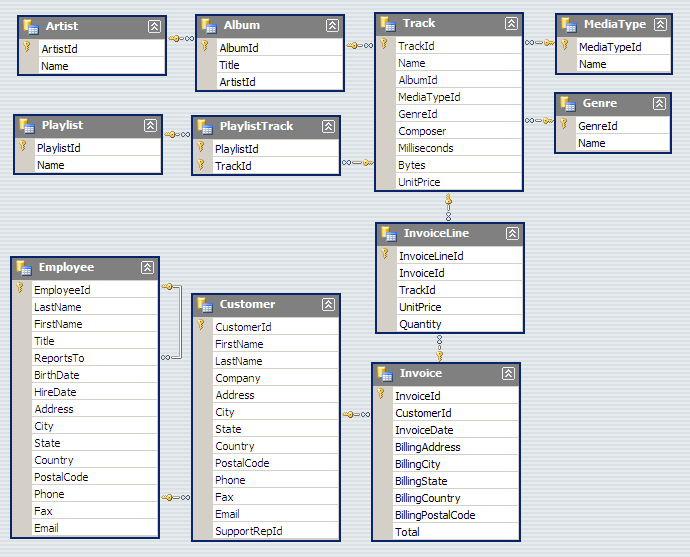
import sqlite3
# first connect to database and get a cursor for executing commands
conn = sqlite3.connect('Chinook.db')
cr = conn.cursor()
# What tables are in the database?
cr.execute("select name from sqlite_master where type = 'table';")
print cr.fetchall()
[(u'Album',), (u'Artist',), (u'Customer',), (u'Employee',), (u'Genre',), (u'Invoice',), (u'InvoiceLine',), (u'MediaType',), (u'Playlist',), (u'PlaylistTrack',), (u'Track',)]
# What is the structure of the Album table?
cr.execute("select sql from sqlite_master where type = 'table' and name = 'Album';" )
print cr.fetchone()[0]
CREATE TABLE [Album]
(
[AlbumId] INTEGER NOT NULL,
[Title] NVARCHAR(160) NOT NULL,
[ArtistId] INTEGER NOT NULL,
CONSTRAINT [PK_Album] PRIMARY KEY ([AlbumId]),
FOREIGN KEY ([ArtistId]) REFERENCES [Artist] ([ArtistId])
ON DELETE NO ACTION ON UPDATE NO ACTION
)
# What is the structure of the Artist table?
cr.execute("select sql from sqlite_master where type = 'table' and name = 'Artist';" )
print cr.fetchone()[0]
CREATE TABLE [Artist]
(
[ArtistId] INTEGER NOT NULL,
[Name] NVARCHAR(120),
CONSTRAINT [PK_Artist] PRIMARY KEY ([ArtistId])
)
# List a few items
cr.execute("select * from Album limit 6")
cr.fetchall()
[(1, u'For Those About To Rock We Salute You', 1), (2, u'Balls to the Wall', 2), (3, u'Restless and Wild', 2), (4, u'Let There Be Rock', 1), (5, u'Big Ones', 3), (6, u'Jagged Little Pill', 4)]
# find the artist who performed on the Album 'Big Ones' cmd = """ select Artist.Name from Artist, Album where Artist.ArtistId = Album.ArtistId and Album.Title = 'Big Ones'; """ cr.execute(cmd) cr.fetchall()
[(u'Aerosmith',)]
# clean up cr.close() conn.close()
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!
发布评论