MIT 6.824 Spring 2021 Raft Lab 实现笔记
最近花时间做了一下 6.824 的 Raft Labs,总算把 Raft 亲自实现了一下,收获还是很大的,羡慕 MIT 学生。实验提供的初始代码可以通过 git clone git://g.csail.mit.edu/6.824-golabs-2021 6.824 获取。Lab 指导资料可以在 https://pdos.csail.mit.edu/6.824/labs/lab-raft.html (Lab 2) 和 https://pdos.csail.mit.edu/6.824/labs/lab-kvraft.html (Lab 3)获取。
Lab 4 是 Sharded KV Server 实验,是默认的 Final Project,约等于精简版的 TiKV 了,工作量比较大。不得不说分布式的程序调起来十分要命,首先是错误不一定 100% 出现,复现得碰运气,也基本用不上 Debugger,得在茫茫 Log 中大海捞针,分析不同进程到底以怎样的顺序执行了操作,发生了什么状态导致了 Bug,是对耐心和编程技巧的一次考验。再次羡慕 MIT 学生,拥有优秀的教学资源。
不过,Lab 2 和 Lab 3 都没有要求实现 Membership Change,这个其实也是一个很具有挑战性的功能,有空参考其他资料实现一下。
Raft 有两篇论文,一篇是精简版的发表在 ATC’14 的 [In Search of an Understandable Consensus Algorithm][1],另一篇则是更加完善的 Diego Ongaro 的博士论文 [Consensus: Bridging Theory and Practice][2]。
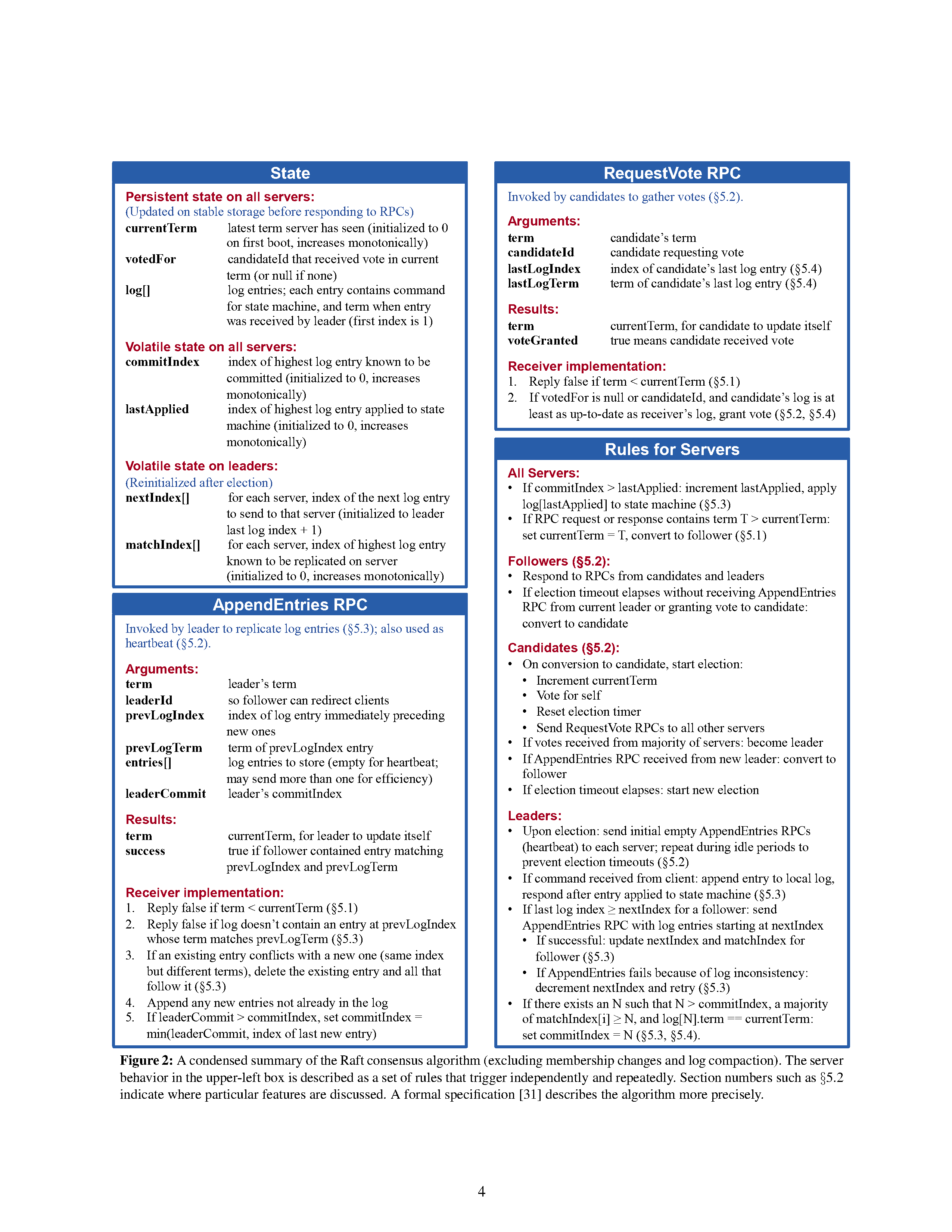
Raft 最最核心的算法只有 Figure 2 的两个 RPC: AppendEntries 和 RequestVote ,非常简单明了,实现起来代码量也不大,大约几百行就可以完成 Leader Election 和 Log Replication 的功能。而且小论文里的 Figure 2 也详细地列出了不同状态下的服务器在收到不同 RPC 的情况下,应当做什么。只要严格按照论文中的要求实现代码,就能完成 Raft 的基本功能。
Raft 有几个基本性质:
- Election Safety:一个 Term 内最多只能有一个 Leader。
- Leader Append-Only:Leader 只会往自己的 Log 中新增日志,不会删除、修改日志。
- Log Matching:如果某两个 Log 有相同的 Index 和 Term,那么这个 Log 以及之前的所有 Log 都包含相同的数据。
- Leader Completeness:如果一个日志已经提交(Commited),那么这个日志将会包含在所有未来的有着更高 Term 的 Leader 中。
- State Machine Safety:如果一个日志已经应用(Applied)到状态机,那么不会有服务器在同一个 Index 应用不同的 Log。
同时,还有几个实现时候的原则:
- Log 只会由 Leader 发送到 Follower,不可能反向传输。
- 状态机只能在一个操作被 Apply 之后,才能将这个操作应用到状态转移。
- Log 应该按顺序 Apply,不应该出现空洞,例如,应用 Index 为 1 的 Log 之后如果应用 Index 为 3 的 Log 是非法的。
论文里提到 Leader 除了在收到客户端请求之后需要发送 AppendEntries RPC 给 Follower 同步最新日志,还需要定时发送 Heartbeat 给 Follower 以维持 Leader 状态,又提到 Heartbeat 其实是 entries 为空的 AppendEntries RPC。一开始可能会觉得 Heartbeat 是一种特殊的消息类型,而且只需要发送 entries 为空就好,但其实如果 Leader 发现 Follower 有缺失的日志(通过检查 nextIndex),也是需要捎带在心跳包中的。
不然如果只在 Leader 收到客户端请求之后才发送 AppendEntries RPC 补齐日志,那么有可能如果客户端长时间不进行任何操作,有一部分日志会永远都同步不到 Follower 上,也就无法提交这部分日志。说白了 Heartbeat 也是 AppendEntries RPC,只是它允许 entries 为空,而不是必须为空。在心跳期间如果发现 Follower 日志落后于 Leader,也是需要按照流程将缺失的 Log 发送到 Follower 的。
另外,AppendEntries RPC 还有一个功能是收集不同 Follower 的日志同步信息,以便 Leader 推进 commitIndex,同时 Leader 也需要通过 AppendEntries RPC 中的 leaderCommit 来推进 Follower 提交日志。所以,哪怕日志为空,Heartbeat 也起到了推进 commitIndex 的作用,各 Server 才可以将日志不断 Apply 到状态机。所以,Heartbeat 并不是仅仅是维持 Leader Lease 一个作用,系统状态也需要依赖它进行整体推进。
因此,Leader 不需要实现单独的 Heartbeat 方法,只需要按照 Heartbeat 间隔向各 Follower 按照完成流程发送 AppendEntries RPC 即可,只是不需要检查 lastLogIndex 是否大于等于 nextIndex。当然,可能某次客户端请求后发送的 AppendEntries RPC 还没返回,nextIndex 还没有推进,就到了 Heartbeat 时间,这种情况下可能会重复发送相同的 AppendEntries RPC,虽然对正确性没有影响,但是是一个可以优化以节省网络带宽的地方。
论文里虽然提到了收到了过期的 RPC 请求直接忽略并返回当前 Term 给请求方,但没提到收到过期的 RPC 回复应该如何处理。一种比较简单的方法就是,比较 RPC 请求时的 Term 和当前 Term,如果是过期的请求,那么直接忽略不处理即可。
论文里还提到 Follower 收到 AppendEntries RPC 时应当检查 prevLogIndex 和 prevLogTerm 是否匹配。但是并没有提到不匹配的时候 Leader 应当如何探测出匹配的 Log Index。一种粗暴的方法是 Leader 每次都将 nextIndex – 1,直到成功匹配为止。这种方法效率显然是很低的,需要大量的 RPC,假如网络延迟比较高,那么时间开销会非常大。当然,也可以考虑二分的方法来匹配,但是二分法可能会传输不必要的 Log Entries。
更好的办法是让 Follower 在发生不匹配的时候尝试找到最后一个匹配的 Log Index 并发送回 Leader,这样 Leader 可以一步到位知道日志最后匹配的位置,也避免了发送不必要的日志。但是论文里没有提到怎么检测不匹配的位置,又如何返回信息。课程 TA 的博客( https://thesquareplanet.com/blog/students-guide-to-raft/ )提到了这么一种办法:
在 AppendEntries Reply 中额外返回 conflictIndex 和 conflictTerm 两个字段
- 如果 prevLogIndex 超过了自己的 Log Index,那么直接返回 conflictIndex = lastLogIndex + 1,conflictTerm = None
- 如果 prevLogIndex 在自己 Log 中存在,但是 Term 不等于 prevLogTerm,说明之前有 Leader 同步了 Log,但没来得及提交就 Crash 了,那么 conflictTerm 设为自己 log 中 prevLogIndex 对应的日志的 Term,并且将 conflictIndex 设置为那个 Term 的第一个日志的 Index
Leader 收到 AppendEntries 失败的时候,需要根据 conflictIndex 和 conflictTerm 两个字段来找到最后匹配的日志。
- 首先找 conflictTerm 在自己日志中是否存在,存在的话将 nextIndex 设置为那个 Term 最后一个 Log 的 Index + 1
- 如果找不到,那么 nextIndex = conflictIndex
这样可以减少 RPC 次数,也避免了发送不必要的 Log Entries 节省网络带宽。
原始的算法中并没有提到 Leader 当选后需要提交空日志,因为作为通用的共识算法,空日志应当由上层应用提供,我们只需要提供一个回调函数接口或者通知机制即可。但是这样可能导致如果 Leader 当选后的 Term 和之前未提交的 Log Term 不一致的话,而后续客户端又没有提供新日志,那么这最后的日志将无法提交,又导致了状态无法推进的问题。尽管正确的解决办法是上层应用在得知新 Leader 当选后立刻提交一个空日志,以便将之前未提交的日志一并提交,但是 Lab 2 测试没有这样的行为。所以我们需要尽可能避免这种情况发生。
一种可行的方法是放宽 Leader 提交日志的条件,将 log[newCommitIndex].Term == currentTerm 的限制放宽到 log[newCommitIndex].Term >= currentTerm – 1。另外还需要调整 Heartbeat Interval 和 Election Timeout(对的,哪怕是 Raft 也要调参 = =),尽可能避免 Term 跨度过大的情况发生,也就是新 Leader 当选后由于网络延迟或者丢包等问题没来得及提交日志又发生了 Election 的问题。个人尝试了 Heartbeat Interval = 125ms 和 Election Timeout = 350ms~550ms 可以稳定通过测试。
分布式以及多线程程序的测试,往往测试几次可能都无法暴露出 bug,需要大量长时间重复测试才可以更充分地说明你的程序没有 bug (有的 bug 可能需要跑几百次才会发生一次)。同时也需要保存好测试中的 log 输出,等测试发现了有 bug 发生,就可以用 log 来排查问题。否则又要跑几百次来复现 bug。
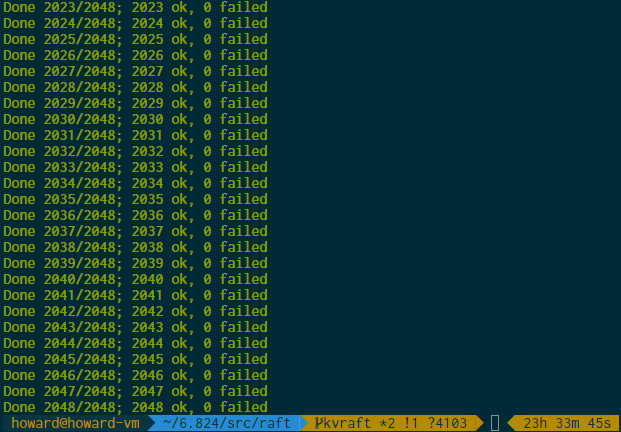
我个人测试用了助教提供的并行测试脚本 https://gist.github.com/jonhoo/f686cacb4b9fe716d5aa ,可以同时开多个 go test 进程来对算法进行测试。这是因为在低负载和高负载的情况下,进程的调度顺序可能有很大不同,高负载情况下往往更容易暴露出一些 Bug。当然并行数不能开太高,我设置的是 CPU 核数 x 2,如果太高的话,可能会发生某个测试跑太慢,实际运行时间太长(例如 2B 测试需要在 120s 内跑完)导致失败的问题(尽管可能程序并没有问题)。我以 CPU 核数 x 2 为并行数,跑了 2048 次测试,在我的 Ubuntu 20.04 虚拟机上一个测试大概需要 8 分钟的实际时间和 1m30s 的 CPU 时间。跑了整整一天之后看见没有 failed,终于觉得实现比较靠谱了。
Raft 日志不能无限增长,所以后期需要实现 Snapshot,并对 Log 数组进行截断操作以节省内存使用,这时候就不能粗暴地用 Log Index 作为数组下标寻址。一种方法是用 map 存储 Log Index 和实际数组下标的关系,不过维护起来可能有些麻烦。由于 Log 是有序存储的,所以用二分查找也是不错的选择,实现也比较简单,不需要额外空间。个人用的是二分查找的办法。
Snapshot 中的 LastIncludedTerm 和 LastIncludedIndex 可以存储在 log[0],这样就不需要额外的字段来存储 Snapshot 状态了,也简化了代码。
Snapshot 的实现也是直接按照论文实现即可,由于不用实现 Snapshot 的分段传输,所以没有什么难度。不过 Snapshot 的应用流程有一点绕,具体流程是:
- 上层应用检测到 Raft Log 过大时,将自己当前状态机进行编码,并调用
Snapshot函数将当前状态数据以及最后应用的 Index 传入 Raft 层,Raft 层截断自己的 Log 并将 Snapshot 数据持久化。 - 当 Follower 收到
InstallSnapshot RPC后(一般是落后太多的情况下,例如宕机太久或者由于网络问题一直没有收到 AppendEntries),更新自己的 Log,并将 Snapshot 提交到 Apply Channel。 - 上层应用收到 Apply Channel 中的 Snapshot 时,调用
CondInstallSnapshot检查 Snapshot 是否是最新的,能否被应用。 - 如果
CondInstallSnapshot返回 true,说明 Snapshot 可以应用,上层根据自己的协议解析 Snapshot Data,应用到自己状态机即可。
实现了 Raft 之后实现上层应用就比较简单了,只需要调用 Start() 接口并监听 Apply Channel,将状态机命令应用即可。Lab 3 就是基于 Lab 2 的 Raft 协议实现一个 Fault-tolerance KV Service。在小论文里篇幅限制没有详细说明 Client 的 RPC 过程,但是在博士论文里有详细说明 RPC 的过程。
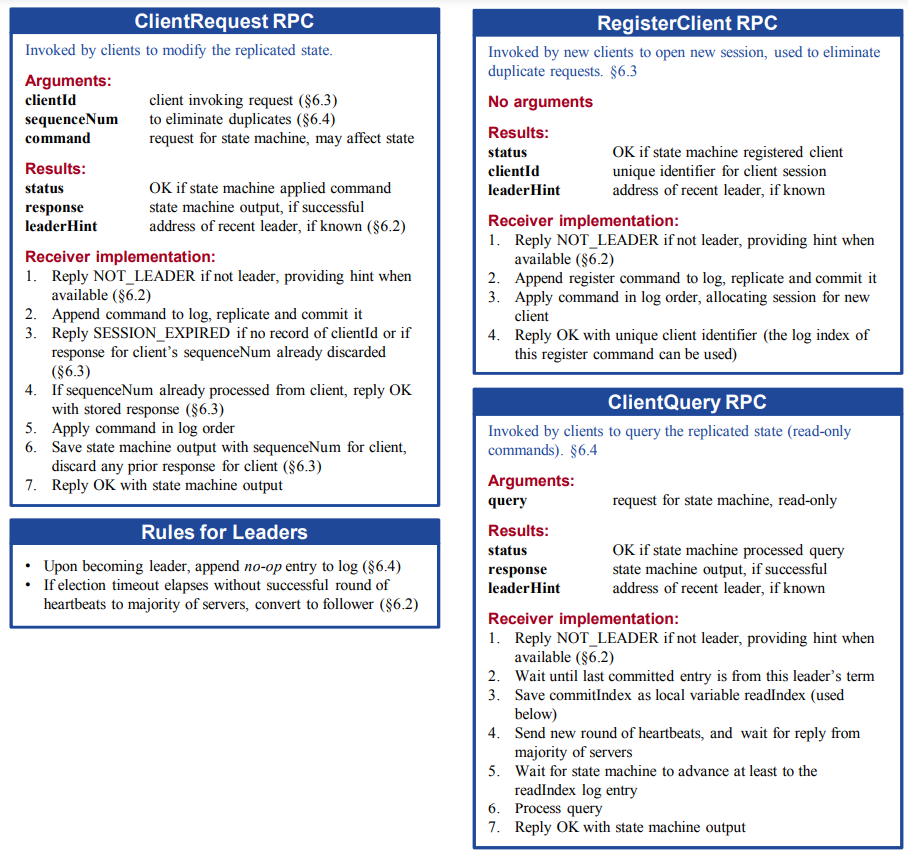
需要注意几点:
- 所有的客户端请求只能由 Leader 处理,如果请求的服务器不是 Leader,或者在请求处理过程中失去了 Leader 的身份,需要返回错误告知 Client 当前 Server 不再是 Leader。一个优化的操作是同时在错误返回中告知当前 Leader 的地址。
- 新 Leader 选举出来的之后为了更快提交之前没有提交的日志,需要马上在当前任期提交一个空操作的日志,成功提交之后之前的日志也就一并提交了。我是通过一个回调函数来实现的。用 Channel 可能更好。
- 客户端初始并不知道哪一个 Server 是 Leader,可以简单地随机尝试一个。当 RPC 失败或者 Server 返回错误说明自己不是 Leader 的情况下,随机重试另外一个 Server,如果错误中包含了 Leader 地址,直接用 Leader 地址即可。由于实际中 Leader 一般不会频繁变化,Client 在收到一次成功的响应之后就可以将 Leader 缓存起来,下一次直接请求即可。当然,也可以实现 Server 负责转发请求到真正的 Leader,但是这种实现会麻烦一些,由客户端自行选择 Leader 会简化实现。
- 为了防止一个客户端命令重复提交,需要每个客户端拥有一个唯一的标识符。博士论文里是使用
RegisterClientRPC 来申请一个 Client ID,Lab 3 简单起见直接由客户端在启动的时候生成一个随机数作为 Client ID。同时,每一个 Client 发送请求的时候都应该携带唯一的 Request ID,可以简单采用递增的序列号来标识请求。Server 端收到请求的时候,首先检查 Client ID + Request ID 是否已经响应过,如果有缓存的话则不再进行 Raft 共识,直接将缓存的响应返回给客户端,达到去重效果。在提交操作到 Raft 层时,需要将 Client ID 与 Request ID 也作为 Op 的一部分提交,确保每一个 Member 都能得知相同的去重数据。在 Server Apply Command 的时候,直接构造好响应请求存入缓存中即可。 - 由于 Server 不可能无限制地缓存所有请求的回复,需要定期删除 Server 的响应缓存(Lab 3 测试中也会测试你的 Snapshot 大小是否超过限制)。需要注意的是每个 Server 淘汰缓存的策略应该是确定性并完全一致的,论文里提到可以采用 LRU 的方法。或者,Leader 提交 Op 的时候同时提交一个时间戳,每个 Server 根据时间戳来决定是否淘汰。也可以 Client 在发送请求的时候捎带上自己最后收到回复的 Request ID,Server 直接将这个 Request ID 以及之前的响应全部淘汰即可。Server 还应当记录每个 Client 的 ID 以及发送过的最大的 Request ID,如果发现一个请求的 Client ID 不存在,或者有着更小的 ID,但是缓存中没有找到,说明这个响应已经处理过,但是已经被淘汰了。这时候可以换回一个 ErrSessionExpired 告知客户端会话过期,如何处理这个错误由客户端决定,博士论文提到其实现是直接 Crash 客户端,这样就直接申请一个新的 Client ID 继续运行就好。
- 每一个请求在状态机 Apply 之前都不应该返回,可以用一个 Channel Block 住当前请求,并用 Raft 层返回的 Command Index 作为索引存放在 map 中。如果某个 Command Index 已经在等待,说明之前这个 Server 曾经当过 Leader,但是可能是某个 Minority 的 Leader,在与 Majority 恢复通信之后 Log 被截断(有更大的 Term 的 Log),之后又当选为 Leader,所以会出现同一个 Command Index 已经有等待的请求的情况发生,这时候应该先响应旧的请求 ErrWrongLeader,然后再将新的请求存入 map 中。Apply Log 的时候也是同理,如果发现实际应用的 Request ID 或者 Client ID 不匹配,说明之前的请求失败了,应该返回 ErrWrongLeader 让客户端重试一次。
- 如果状态机应用了 Snapshot,应该检查 Snapshot 之前的 Index 是不是有正在等待的客户端请求,在 Lab 实现里,只有 Follower 才会收到 Snapshot 信息,所以直接将所有正在等待的客户端请求响应 ErrWrongLeader 即可。
踩过的一些坑:
不要在临界区做阻塞的操作。例如在 Lock 之后向一个阻塞的 Channel 发送消息或者进行同步 RPC。这样大概率会导致死锁。应该另起 goroutine 或者 Unlock 之后再做阻塞的操作(不知道用 select 将其转换为非阻塞操作是否合理)。
如果一个 Channel 需要 close,最好只有一个 goroutine 来对其进行写操作,而且读方不可以 close 这个 Channel,只能由写方来 close。这是由于向一个已经关闭的 channel 进行写操作会导致 panic,如果一个 goroutine close Channel 之后另一个进行写,就会导致 panic。但是由于第一条规则,我们也不能对 Channel 操作加锁,所以最好是将对 Channel 的写操作收敛到一个 goroutine 里。
[1]: Ongaro, Diego, and John K. Ousterhout. “In Search of an Understandable Consensus Algorithm.” In 2014 USENIX Annual Technical Conference, USENIX ATC ’14, Philadelphia, PA, USA, June 19-20, 2014, edited by Garth Gibson and Nickolai Zeldovich, 305–19. USENIX Association, 2014. https://www.usenix.org/conference/atc14/technical-sessions/presentation/ongaro .
[2]: Ongaro, Diego. “Consensus: Bridging Theory and Practice,” n.d., 258.
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!


发布评论