使用 Boost 的 Property Tree 处理 XML
Boost C++ Libraries 的 PropertyTree 这个函式库( 官方文件 ),基本上是一种通用型的树状资料结构的资料结构;在这棵资料树裡面的每一个节点,都有它自己的资料、以及下方的成员清单。他每一个节点的内部资料结构,在概念上可以看成类似下面的形式:
struct ptree { data_type data; list< pair<key_type, ptree> > children; };而在使用上呢,Property Tree 除了类似 STL container 的操作方法外,也有提供以 key(索引值)组合出来的路径(path)来做资料存取的能力,功能算是满强大的!另外,PropertyTree 除了提供这样的资料结构外,也提供了 XML、INI、JSON 这几种常见的档案标种的 parser,让程式开发者可以简单地透过这个函式库,来读取/写入这些档案,把他们变成结构化的资料。
这一篇文章,基本上就是来讲一下,要怎麽使用 PropertyTree 这个函式库,来处理 XML 档案了。而当然,这边也会提到一些 PropertyTree 的资料结构的存取概念,所以理论上之后要用在其他格式上,问题应该也不大。
XML 的读取/写入
Boost PropertyTree 所提供的 XML Parser 基本上是基于 RapidXML 这个 OpenSource 的 XML parser 来的;而官方文件裡也有提到,他并没有完整地支援 XML 所有的标准(例如他无法处理 DTD、也不支援 encoding 的处理),这是在使用上要注意的地方。不过对于一般使用来说,基本上应该是够用了。
在使用上,Boost PropertyTree 在 boost/property_tree/xml_parser.hpp 这个 header 档裡,提供了 read_xml() 和 write_xml() 这两种函式,可以将 XML 档案(或者从 input stream)读取成 Property Tree 定义的资料结构,也可以将 Property Tree 写入到 XML 档案(或指定的 output stream)。
这些函式都在 boost::property_tree::xml_parser 这个 namespace 下,形式是:
void read_xml( istream &stream, ptree &pt, int flags );
void read_xml( const string &filename, ptree &pt, int flags, const std::locale &loc );
void write_xml( ostream &stream, const ptree &pt, const xml_writer_settings& settings );
void write_xml( const string &filename, const ptree &pt, const std::locale &loc, const xml_writer_settings& settings );
以 read_xml() 来说,第一个参数就是资料来源,如果给他一个 string 的话,就是代表是一个档案名称,如果是一个 istream 的话,他就会以标准的 input stream( 参考 )的方法、来读取资料;而读取完成的资料,就会储存在第二个参数、也就是型别为 ptree 的变数中。
而 ptree 这个型别是被定义在 <boost/property_tree/ptree.hpp> 这个 header 档裡,他的 namespace 是 boost::property_tree,实际上的型别是 basic_ptree<string, string>,也就是每一个节点的索引和值的型别都是 string 的通用型的标准节点;如果有需要的话,应该也是可以使用额外的型别,不过这边就不提了。(注 1)
实际使用呢,很简单,就是:
std::string sFilename = "a.xml";
boost::property_tree::ptree bPTree;
boost::property_tree::xml_parser::read_xml( sFilename, bPTree );
这样就可以把 a.xml 的内容,读取到 bPTree 裡了!
而如果 XML 的资料来源不是档案的话,只要可以转换成 input stream 的形式,也都可以用这个 parser 来处理~例如 XML 已经是字串的话,就可以透过 STL 的 string stream 这样写:
stringstream ss; ss << "<?xml ?><root><test /></root>";
boost::property_tree::ptree bPTree;
boost::property_tree::xml_parser::read_xml( ss, bPTree );
至于输出的部分,其实也是类似的,只要改用 write_xml()、来源档案变成要输出的档案,或是由 intput stream 变成 output stream 而已~下面就是一个简单的例子:
boost::property_tree::ptree bPTree; //.....
boost::property_tree::xml_parser::write_xml( "test.xml", bPTree );
ptree 形式的 XML 的资料形式
既然已经把 XML 的资料都塞到 ptree 这个形式的资料结构裡了,接下来,自然就是看要怎麽把他读出来了~
基本上,ptree 这个资料结构,是代表 XML 中的单一元素(element),但是它本身不会记录自己的名称,而是把名称交给自己的上一层来做纪录。所以它基本上只会记录自己的值,以及用一个 pair<string, ptree> 的 list 来记录属于自己的其他资料,例如底下的 child element 和 attribute;其中,list 裡的每一个 pair 的第一项就是名称、第二项则是以 ptree 形式来记录的资料。
要注意的是,针对 XML 的资料来源,Property Tree 会有一些特别的索引值,像是所有的 attribute 都会被群组起来,放在一个名为 <xmlattr><xmlcomment>
下面就是一个简单的例子:
<root type="node">
<element>value</element>
<size unit="cm" scale="1">
<width>500</width>
<height>500</height>
</size>
</root>
以上方的 XML 片段来说,当透过 Boost 的 Property Tree 的 XML Parser 来分析、以 ptree 的形式来做储存的时候,它的结构大概会变成是下面这样:
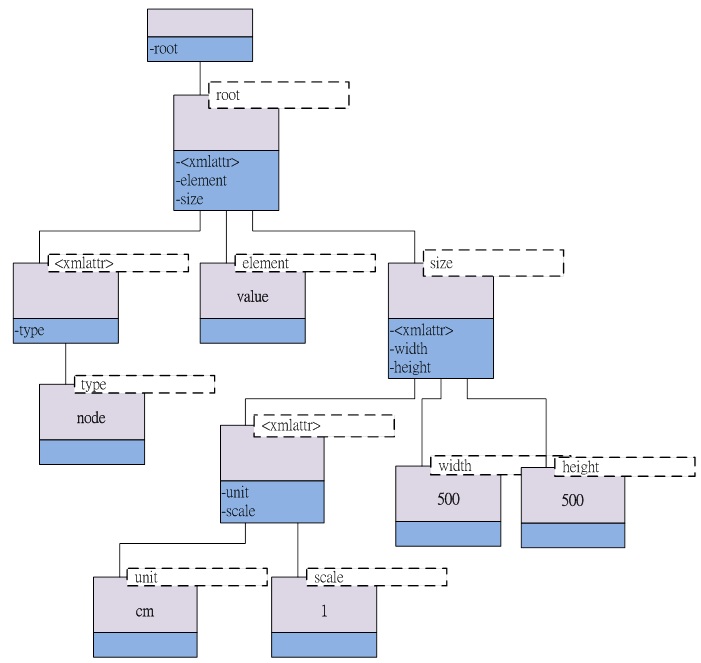
上面的示意图裡,每一个方块都代表一个 ptree 的节点,而上半部浅紫色的部分,是代表这个节点本身的资料(型别是 string),可以透过 data() 这个函式取得;下半部蓝色的部分,则是这个节点的 child 的 list(裡面每一项的资料型别都是 pair< string, ptree>)的索引值、也就是 child 的名称,基本上是以类似 STL container 的 iterator 的形式来做存取。
而右上方的虚线框的部分,则是代表这个节点的名称,但是如同前面所说的,实际上个别节点并不会真的纪录自己的名称,名称的部分实际上是以 pair 的第一个元素的形式,储存在 parent 的 child list 中。也因此可以发现,实际上他会用一个没有名称、也没有值的节点当作整棵树的“根”,底下才是我们要的 XML 的资料。
资料读取范例
概念讲完了,实际操作是怎麽用呢?下面就是 Heresy 针对 ptree 写的 operator<<,可以用在 STL 的 output stream 上;不过为了可以控制缩排、让输出比较漂亮,所以 Heresy 是有用 pair 的方法,再把 ptree 和目前是第几层包成 pair< int, const ptree& > 的形式,第一项的 int 就是代表要缩排几层而已。
ostream& operator<<( ostream& os, const pair<int, const ptree&>& rNode ) {
int iNext = rNode.first + 2;
const ptree& rPT = rNode.second;
os << " Value: [" << rPT.data() << "]\n";
for( auto it = rPT.begin(); it != rPT.end(); ++ it ) {
os.width( iNext ); os << "";
os << "Name: [" << it->first << "]";
os << pair<int, const ptree&>( iNext, it->second );
}
return os;
}其中绿底的部分,就是读取 ptree 的资料的部分,而黄底的部分,则是用 iterator 的形式读取 child list 的部分;其中,iterator 取得的每一项实际上都是型别为 pair<string, ptree> 的资料,他的 first 就是这个 child 的名称(型别为 string), second 就是这个 child 的资料(型别为 ptree)。
而要使用的话,就是类似下面这样:
xml_parser::read_xml( ssXML, PTree ); cout.fill( ' ' );
cout << pair<int, const ptree&>( 0, PTree ) << endl;
然后就会输出成下面这样的形式:
Value: [] Name: [root]
Value: [] Name: [<xmlattr>]
Value: [] Name: [type]
Value: [node] Name: [element]
Value: [value] Name: [size]
Value: [] Name: [<xmlattr>]
Value: [] Name: [unit]
Value: [cm] Name: [scale]
Value: [1] Name: [width]
Value: [500] Name: [height]
Value: [500]
从这边使用的例子应该可以看出来,实际上 ptree 的使用形式就是接近一般的 STL container iterator 的操作,如果对于 STL 使用算熟系的话,这边要操作应该不会有太大的问题;而实际上,ptree 也有提供 find()、push_back()、erase() 这类 STL container 常见的函式,可以进行资料的操作,不过这边就不提了,有兴趣的可以自己玩看看。
指定路径的资料存取
而除了这样把整个 ptree 当作 STL container、用 iterator 的形式来扫之外,实际上 ptree 也有提供 get() 的函式,可以直接透过索引值的组合的字串(Property Tree 是把它称为 path、也就是“路径”)(注 2)、直接读取 ptree 下面特定节点的资料。
string s1 = PTree.get<string>( "root.element" );
string s2 = PTree.get<string>( "root.size.<xmlattr>.unit" );
以上面的例子来说,s1 就会是 element 的值、也就是 value,s2 则会是 size 这个 element 的“unit”这个 attribute 的值,也就是“cm”。
而如果希望做型别转换的话,也是可以在透过 get() 读取时,让他一起做的~例如:
float w = PTree.get<float>( "root.size.width" );
这样的写法,就会把 width 的 500 从字串转换成浮点数,而 w 的值就会是 500.0f;如此一来,在读取资料的同时,也就可以同时做好资料型别转换的动作、算是非常方便的~
不过要注意的是,这种用法在找不到指定的路径的值、或者型别无法正确转换的时候,会丢出 exception 来,告诉你资料有问题、无法读取。
如果想要避免 exception 的话,可以考虑加上第二个参数、来当作预设值,这样在读取不到资料的时候,就自动用所给的预设值来替代。
float d1 = PTree.get<float>( "root.size.depth", 500.0f );
float d2 = PTree.get<float>( "root.size.depth" );
像上面这样的写法,由于 XML 资料本身并不包含 depth 的资料,所以 d1 会是得到预设的 500.0f;但是 d2 的时候,则会因为找不到 depth,所以丢出 exception、中断程式的执行。
除了这两种方法外,其实 Property Tree 也还可以合併 Boost 的 Opetional 这个函式库( 文件 ),使用 get_optional() 这个函式、来读取不一定存在的资料,不过这边就先不提了。
而要写入资料该怎麽办呢?如果是要写入 ptree 这个节点本身的资料的话,直接使用 put_value() 这个函式就可以了(基本上可以视作对应读取用的 data());另外,他也可以像 get() 一样,使用 put() 这个含式、直接去设定这颗树下面某个节点的值。下面就是一把 width 的值从 500 改成 250 的例子。
PTree.put( "root.size.width", 250 );
另外要注意的是,在使用 put() 的时候,如果路径指定的节点存在的话,他会把本来的值改掉;但是如果指定的节点不存在的话,他是会把这些本来不存在的节点建立出来,然后再赋予它指定的值的。
而相较于此,ptree 也还有提供一个 add() 的函式,可以强制建立出新的节点;也就是说,就算路径所指定名称的节点本来就已经存在了,他还是会再建立一个名称一模一样的节点。基本上,应该是不建议这样使用啦~有兴趣的话,可以自己玩看看。
而除了这些函式之外,Property Tree 也还有像是 get_child() 和 put_child() 这类的函式,可以取得特定路径的节点(ptree)、而非取得该节点的值,不过在这边就不多提了。
恩,Boost 的 Property Tree 这篇就先写到这了,基本上内容已经写的比 Heresy 预期的多不少了…而整个写完,也又发现不少 Heresy 在用的时候,没有注意到的地方。
整体来说,Heresy 觉得 Boost 的 Property Tree 对于树状结构的资料存取来说,应该算是一个相当强大的资料结构,尤其是根据路径来做存取的功能,在很多地方应该都算是满实用的~而如果要拿来做 JSON、INI、XML 或是自订格式的档案之间的转换、应该也会是满实用的东西。
目前 Heresy 这边应该是会先把它当作 XML 的 Paser 来用吧~之后可能也会再看看还有没有什麽其他地方用的到, :)
附注:
除了使用 string 当作主要型别的 ptree 外,Property Tree 也还有使用 wstring 的 wptree 可以用;另外,也还有无视大小写的 iptree 以及 iwptree。
Property Tree 的路径实际上也是另一种特殊型别 ptree::path_type,不过可以自动从 string 转过去;他预设是用“.”来做索引值间的连接,如果需要特别的连接字元的话,就需要使用直接使用 path_type 的建构子来建立所需要的路径。像下面的俩的 get() 的范例,实际上就是一样的,只是第二行的例子是强制把索引值之间的连接字元设定为 /。
PTree.get<float>( "root.size.opt.depth" );
PTree.get<float>( ptree::path_type( "root/size/opt/depth", '/' ) );ptree 的所有函式列表请参考官方文件( 连结 )。
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

上一篇: 单 Epoll 多线程 IO 模型
下一篇: 不要相信一个熬夜的人说的每一句话
绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!






发布评论