修改 HuggingFace 模型默认缓存下载路径
一、缓存路径和缓存文件结构
1. 缓存路径
首先,你需要先了解 Transformers 库对于它默认下载的缓存路径和文件结构,这样能让你更清楚的明白,Transformers 库的.cache 系统以及如何更改缓存路径。
通过 Hugging Face 的 Transformers 库自动下载模型,会先缓存在默认路径:
- Linux :
'~/.cache/huggingface/hub' - Windows :
C:\Users\username\.cache\huggingface\hub
缓存的模型文件以哈希值形式储存,文件结构如下:
<CACHE_DIR> # 缓存路径
├─ <MODELS> # 模型路径
├─ <DATASETS> # 数据集路径
├─ <SPACES> # 空间路径
<CACHE_DIR> 通常由 HF_HOME 或 HF_HUB_CACHE 指定,具体看第二节
2. 缓存文件结构
模型,数据集 ,空间,他们的存放格式如下 :models/datasets/spaces--模型名称
<CACHE_DIR>
├─ models--julien-c--EsperBERTo-small
├─ models--lysandrejik--arxiv-nlp
├─ models--bert-base-cased
├─ datasets--glue
├─ datasets--huggingface--DataMeasurementsFiles
├─ spaces--dalle-mini--dalle-mini
其中,不管是 models 、 datasets 还是 spaces ,他们子目录的文件结构也一样,如下:
<CACHE_DIR>
├─ datasets--glue
│ ├─ refs
│ ├─ blobs
│ ├─ snapshots
...
refs :是一个指针文件,使用 Hugging Face 的模型或数据集时,系统会通过检查 refs 文件夹中的信息,确定是否需要更新本地缓存的文件。blobs :文件夹包含已下载的实际文件。每个文件的名称就是它们的哈希值。snapshots : 文件夹包含指向上述 blob 的符号链接。
它本身由多个文件夹组成:每个已知版本一个!该文件夹中不具有实体属性,是连接到 blobs 中哈希值文件的连接。通过这种方式创建的框架,实 现了文件共享的机制。如果在修订版本 bbbbbb 中获取的同一个文件具有相同的哈希值,那么该文件就不需要被重新下载。这意味着,即使在不同的修订版本 中,只要文件内容没有变化,就可以复用之前下载的文件,避免了不必要的重复下载。
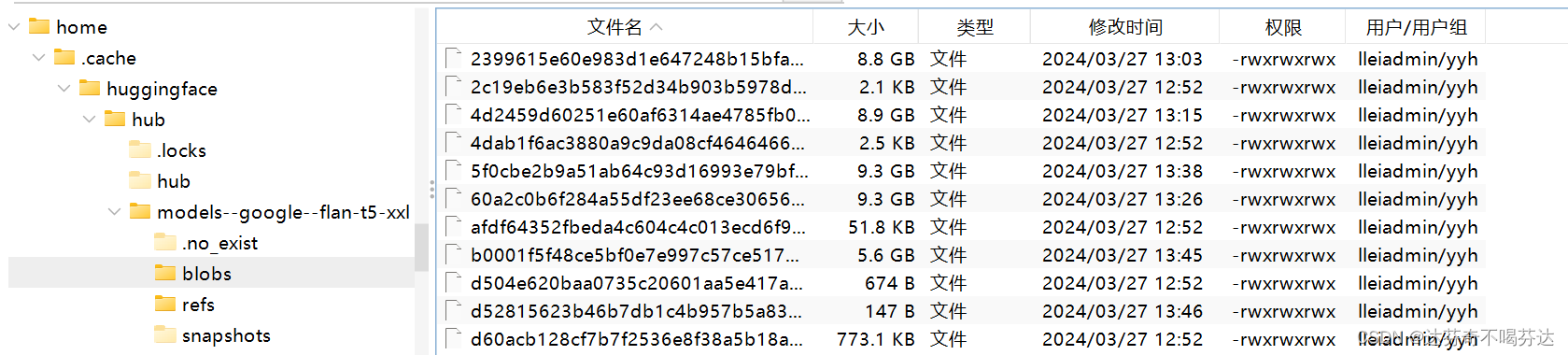
如下图所示,我展示了我 blobs 文件 里的模型文件,他们都自动是以哈希值命名的,我猜是为了防止调用模型是出现重复的情况。
二、更改 Transformers 库模型下载的缓存路径的两种方式
方式一:cache_dir 参数
可以通过 from_pretrained 函数中的 cache_dir 参数来指定,缺点,每次都需要手动指定,比较麻烦。
如:加载一个 bert-base-uncased 模型
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased",cache_dir="路径")
model = AutoModelForMaskedLM.from_pretrained("google-bert/bert-base-uncased",cache_dir="路径")
方式二:设置环境变量
先了解 Shell 优先级顺序 ,
- Shell 环境变量(默认):
HUGGINGFACE_HUB_CACHE或TRANSFORMERS_CACHE。 - Shell 环境变量:
HF_HOME。 - Shell 环境变量:
XDG_CACHE_HOME + /huggingface。
实际使用中,transformer 库首先检查HUGGINGFACE_HUB_CACHE是否被设置,如果没有,再按照上述的优先级顺序检查其他环境变量。下载模型我一般更改HF_HOME。
Linux
通过 vim 编译器永久设置:
vim ~/.bashrc
在末尾行添加:
export HF_HOME="/path/to/you/dir" # 替换为你想更改的目标路径
然后保存退出。输入如下指令让它立即生效:
source ~/.bashrc
可通过如下指令查看是否设置成功
env | grep HF_HOME
如果返回设置的路径,则成功。如图:

Windows
方法一
打开 “控制面板” (可以通过在开始菜单搜索“控制面板”来找到它)。
进入 “系统和安全” > “系统” > “高级系统设置” 。
在出现的 “系统属性” 窗口中,点击 “环境变量” 按钮。
在 “用户变量” 或 “系统变量” 区域点击 “新建” ,然后在“变量名”中输入 TRANSFORMERS_CACHE ,在 “变量值” 中输入 你想要的缓存目录路径 。
方法二
使用 Windows 的命令提示符(CMD)setx HF_HOME "C:\huggingface\hub"
需要重新打开命令提示符窗口才能生效。
三、清理缓存模型文件
在 Python 你想用的环境中 安装:
pip install huggingface_hub["cli"]
然后运行:
huggingface-cli delete-cache #此命令也可以用来查看已经缓存的模型列表。
出现如下图:
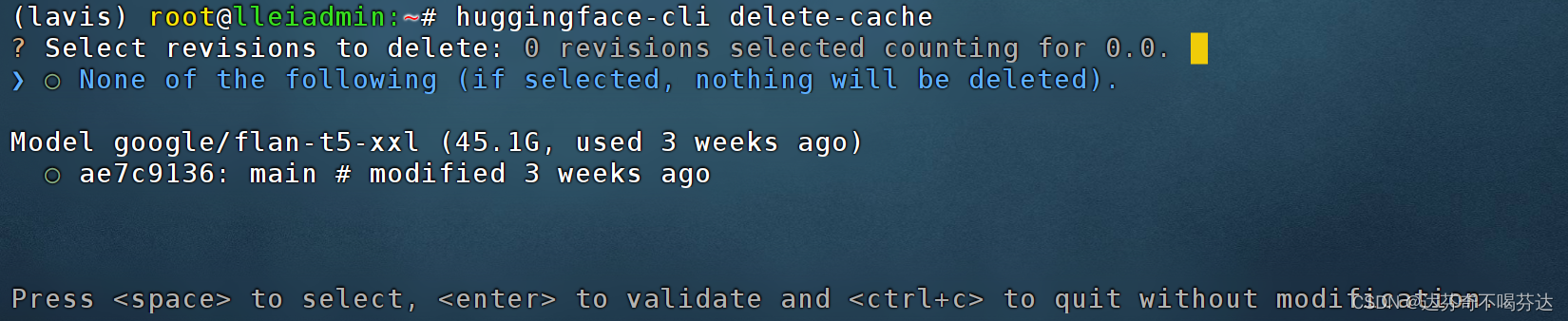
比如我图上的:
Model google/flan-t5-xxl (45.1G, used 3 weeks ago)
○ ae7c9136: main # modified 3 weeks ago
google/flan-t5-xxl 是我下载的模型名称;45.1G 是模型大小;used 3 weeks ago 是最后使用时间;○ ae7c9136: main 最后修改的版本。
最后选择你想要的操作:
- 按键盘箭头键
<up>小键盘 ↑ 方向键和<down>小键盘 ↓ 方向键移动光标。 - 按
<space>(空格键)切换(选择/取消选择)项目,可以多选。 - 按
<Enter>(回车)确认您的选择。 - 如果要取消操作并退出,按
<ctrl+c>退出 TUI。
四、保存模型文件
在第一节中,我们展示了 Transformers 库模型下载后自动缓存的路径,但是这些模型都是以哈希值进行缓存的,我们人类看不懂,所以,如何转化为我们人类看得懂的文件格式呢?
很简单,我们调用 transformers 库的这个函数就行:
例如:我首先从 transformers 库下载模型 bigscience/T0_3B 到缓存路径。
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
然后将缓存的模型保存在到本,采用 .save_pretrained 方法就行:
tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
model = AutoModel.from_pretrained("./your/path/bigscience_t0")
如果你对这篇内容有疑问,欢迎到本站社区发帖提问 参与讨论,获取更多帮助,或者扫码二维码加入 Web 技术交流群。

绑定邮箱获取回复消息
由于您还没有绑定你的真实邮箱,如果其他用户或者作者回复了您的评论,将不能在第一时间通知您!





发布评论